 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfile Prediction: An Alignment-Based Pre-Training Task for Protein Sequence Models
Paper and Code
Dec 01, 2020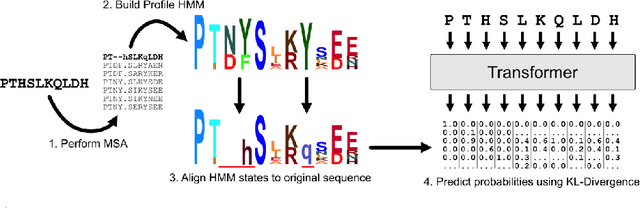
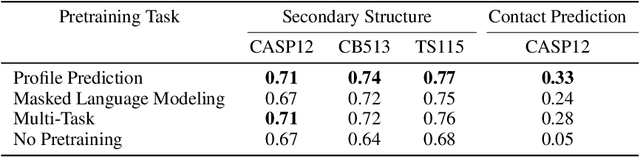
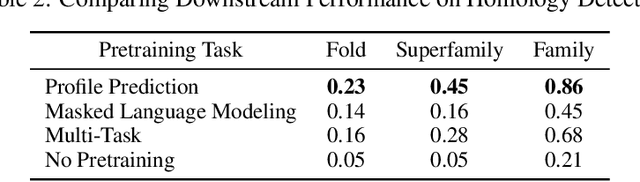
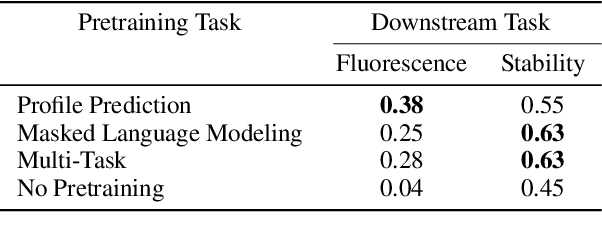
For protein sequence datasets, unlabeled data has greatly outpaced labeled data due to the high cost of wet-lab characterization. Recent deep-learning approaches to protein prediction have shown that pre-training on unlabeled data can yield useful representations for downstream tasks. However, the optimal pre-training strategy remains an open question. Instead of strictly borrowing from natural language processing (NLP) in the form of masked or autoregressive language modeling, we introduce a new pre-training task: directly predicting protein profiles derived from multiple sequence alignments. Using a set of five, standardized downstream tasks for protein models, we demonstrate that our pre-training task along with a multi-task objective outperforms masked language modeling alone on all five tasks. Our results suggest that protein sequence models may benefit from leveraging biologically-inspired inductive biases that go beyond existing language modeling techniques in NLP.