 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWiPE: A Dataset for Document-Level Simplification of Wikipedia Pages
May 30, 2023Text simplification research has mostly focused on sentence-level simplification, even though many desirable edits - such as adding relevant background information or reordering content - may require document-level context. Prior work has also predominantly framed simplification as a single-step, input-to-output task, only implicitly modeling the fine-grained, span-level edits that elucidate the simplification process. To address both gaps, we introduce the SWiPE dataset, which reconstructs the document-level editing process from English Wikipedia (EW) articles to paired Simple Wikipedia (SEW) articles. In contrast to prior work, SWiPE leverages the entire revision history when pairing pages in order to better identify simplification edits. We work with Wikipedia editors to annotate 5,000 EW-SEW document pairs, labeling more than 40,000 edits with proposed 19 categories. To scale our efforts, we propose several models to automatically label edits, achieving an F-1 score of up to 70.6, indicating that this is a tractable but challenging NLU task. Finally, we categorize the edits produced by several simplification models and find that SWiPE-trained models generate more complex edits while reducing unwanted edits.
CREATIVESUMM: Shared Task on Automatic Summarization for Creative Writing
Nov 10, 2022



This paper introduces the shared task of summarizing documents in several creative domains, namely literary texts, movie scripts, and television scripts. Summarizing these creative documents requires making complex literary interpretations, as well as understanding non-trivial temporal dependencies in texts containing varied styles of plot development and narrative structure. This poses unique challenges and is yet underexplored for text summarization systems. In this shared task, we introduce four sub-tasks and their corresponding datasets, focusing on summarizing books, movie scripts, primetime television scripts, and daytime soap opera scripts. We detail the process of curating these datasets for the task, as well as the metrics used for the evaluation of the submissions. As part of the CREATIVESUMM workshop at COLING 2022, the shared task attracted 18 submissions in total. We discuss the submissions and the baselines for each sub-task in this paper, along with directions for facilitating future work in the field.
FOLIO: Natural Language Reasoning with First-Order Logic
Sep 02, 2022
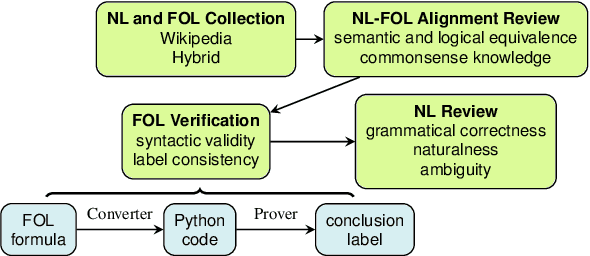
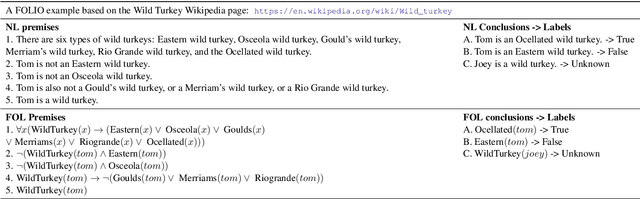
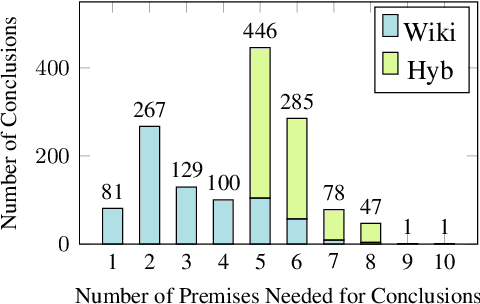
We present FOLIO, a human-annotated, open-domain, and logically complex and diverse dataset for reasoning in natural language (NL), equipped with first order logic (FOL) annotations. FOLIO consists of 1,435 examples (unique conclusions), each paired with one of 487 sets of premises which serve as rules to be used to deductively reason for the validity of each conclusion. The logical correctness of premises and conclusions is ensured by their parallel FOL annotations, which are automatically verified by our FOL inference engine. In addition to the main NL reasoning task, NL-FOL pairs in FOLIO automatically constitute a new NL-FOL translation dataset using FOL as the logical form. Our experiments on FOLIO systematically evaluate the FOL reasoning ability of supervised fine-tuning on medium-sized language models (BERT, RoBERTa) and few-shot prompting on large language models (GPT-NeoX, OPT, GPT-3, Codex). For NL-FOL translation, we experiment with GPT-3 and Codex. Our results show that one of the most capable Large Language Model (LLM) publicly available, GPT-3 davinci, achieves only slightly better than random results with few-shot prompting on a subset of FOLIO, and the model is especially bad at predicting the correct truth values for False and Unknown conclusions. Our dataset and code are available at https://github.com/Yale-LILY/FOLIO.
Improving the Faithfulness of Abstractive Summarization via Entity Coverage Control
Jul 05, 2022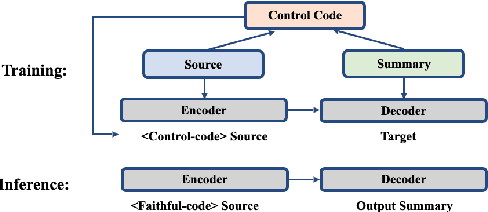
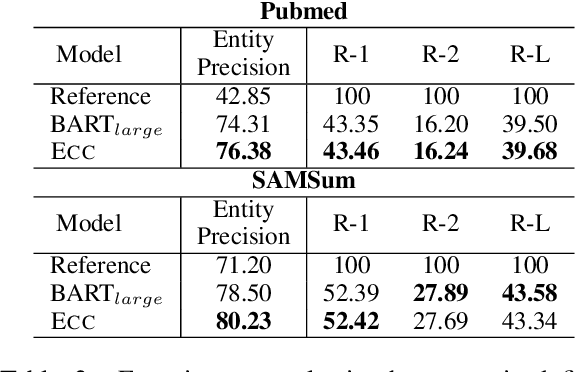
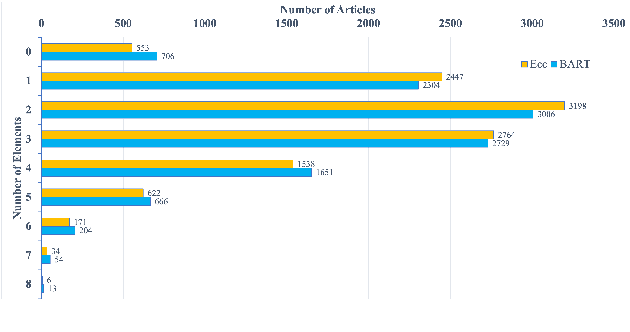
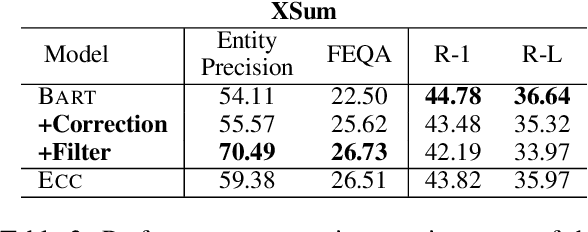
Abstractive summarization systems leveraging pre-training language models have achieved superior results on benchmark datasets. However, such models have been shown to be more prone to hallucinate facts that are unfaithful to the input context. In this paper, we propose a method to remedy entity-level extrinsic hallucinations with Entity Coverage Control (ECC). We first compute entity coverage precision and prepend the corresponding control code for each training example, which implicitly guides the model to recognize faithfulness contents in the training phase. We further extend our method via intermediate fine-tuning on large but noisy data extracted from Wikipedia to unlock zero-shot summarization. We show that the proposed method leads to more faithful and salient abstractive summarization in supervised fine-tuning and zero-shot settings according to our experimental results on three benchmark datasets XSum, Pubmed, and SAMSum of very different domains and styles.
SummVis: Interactive Visual Analysis of Models, Data, and Evaluation for Text Summarization
Apr 15, 2021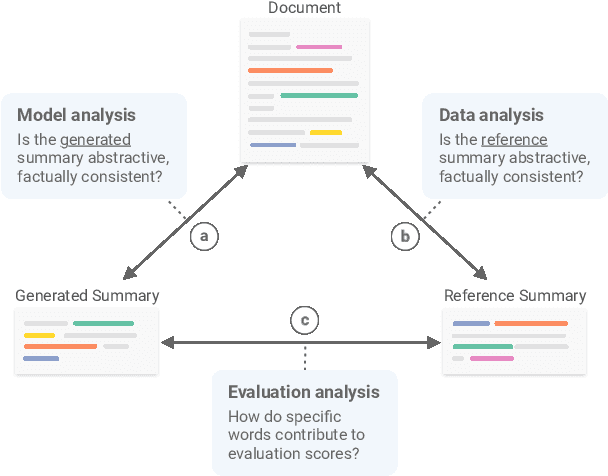
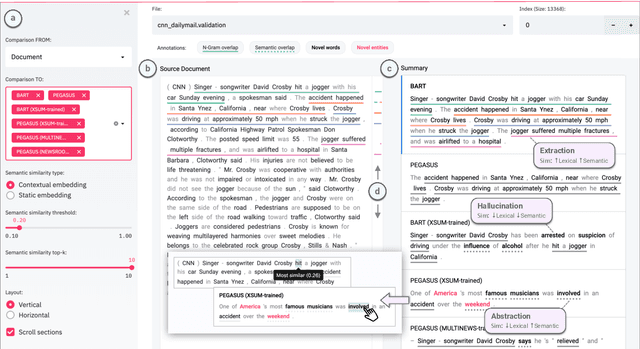
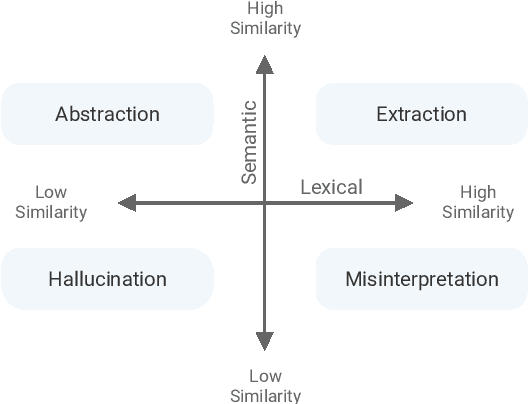

Novel neural architectures, training strategies, and the availability of large-scale corpora haven been the driving force behind recent progress in abstractive text summarization. However, due to the black-box nature of neural models, uninformative evaluation metrics, and scarce tooling for model and data analysis, the true performance and failure modes of summarization models remain largely unknown. To address this limitation, we introduce SummVis, an open-source tool for visualizing abstractive summaries that enables fine-grained analysis of the models, data, and evaluation metrics associated with text summarization. Through its lexical and semantic visualizations, the tools offers an easy entry point for in-depth model prediction exploration across important dimensions such as factual consistency or abstractiveness. The tool together with several pre-computed model outputs is available at https://github.com/robustness-gym/summvis.