 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLINGOLY-TOO: Disentangling Memorisation from Reasoning with Linguistic Templatisation and Orthographic Obfuscation
Mar 04, 2025Effective evaluation of the reasoning capabilities of large language models (LLMs) are susceptible to overestimation due to data exposure of evaluation benchmarks. We introduce a framework for producing linguistic reasoning problems that reduces the effect of memorisation in model performance estimates and apply this framework to develop LINGOLY-TOO, a challenging evaluation benchmark for linguistic reasoning. By developing orthographic templates, we dynamically obfuscate the writing systems of real languages to generate numerous question variations. These variations preserve the reasoning steps required for each solution while reducing the likelihood of specific problem instances appearing in model training data. Our experiments demonstrate that frontier models, including OpenAI o1-preview and DeepSeem R1, struggle with advanced reasoning. Our analysis also shows that LLMs exhibit noticeable variance in accuracy across permutations of the same problem, and on average perform better on questions appearing in their original orthography. Our findings highlight the opaque nature of response generation in LLMs and provide evidence that prior data exposure contributes to overestimating the reasoning capabilities of frontier models.
The PRISM Alignment Project: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models
Apr 24, 2024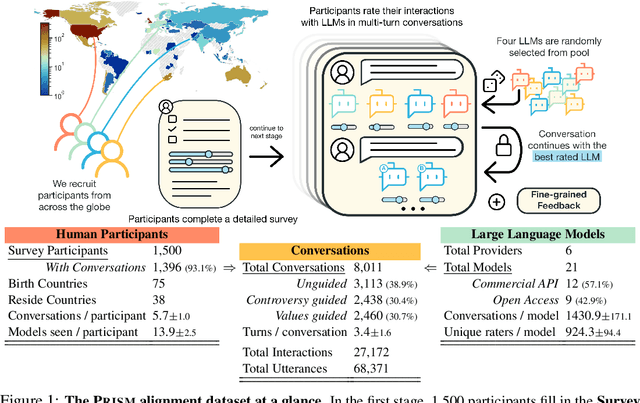
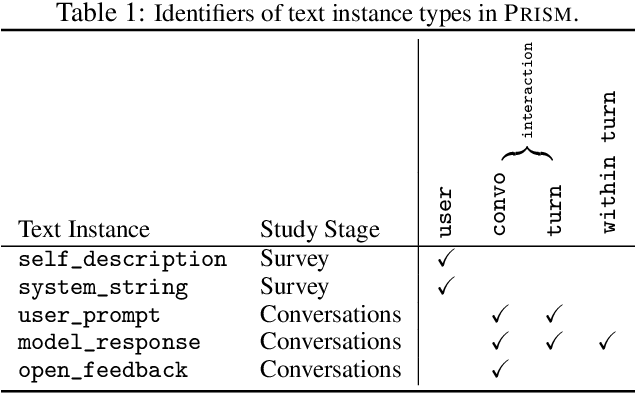
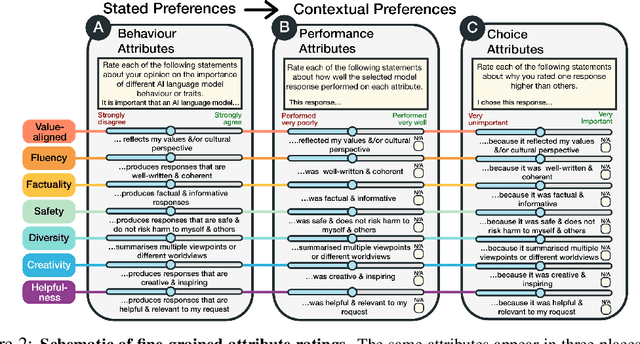

Human feedback plays a central role in the alignment of Large Language Models (LLMs). However, open questions remain about the methods (how), domains (where), people (who) and objectives (to what end) of human feedback collection. To navigate these questions, we introduce PRISM, a new dataset which maps the sociodemographics and stated preferences of 1,500 diverse participants from 75 countries, to their contextual preferences and fine-grained feedback in 8,011 live conversations with 21 LLMs. PRISM contributes (i) wide geographic and demographic participation in human feedback data; (ii) two census-representative samples for understanding collective welfare (UK and US); and (iii) individualised feedback where every rating is linked to a detailed participant profile, thus permitting exploration of personalisation and attribution of sample artefacts. We focus on collecting conversations that centre subjective and multicultural perspectives on value-laden and controversial topics, where we expect the most interpersonal and cross-cultural disagreement. We demonstrate the usefulness of PRISM via three case studies of dialogue diversity, preference diversity, and welfare outcomes, showing that it matters which humans set alignment norms. As well as offering a rich community resource, we advocate for broader participation in AI development and a more inclusive approach to technology design.