 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLINGOLY-TOO: Disentangling Memorisation from Reasoning with Linguistic Templatisation and Orthographic Obfuscation
Mar 04, 2025Effective evaluation of the reasoning capabilities of large language models (LLMs) are susceptible to overestimation due to data exposure of evaluation benchmarks. We introduce a framework for producing linguistic reasoning problems that reduces the effect of memorisation in model performance estimates and apply this framework to develop LINGOLY-TOO, a challenging evaluation benchmark for linguistic reasoning. By developing orthographic templates, we dynamically obfuscate the writing systems of real languages to generate numerous question variations. These variations preserve the reasoning steps required for each solution while reducing the likelihood of specific problem instances appearing in model training data. Our experiments demonstrate that frontier models, including OpenAI o1-preview and DeepSeem R1, struggle with advanced reasoning. Our analysis also shows that LLMs exhibit noticeable variance in accuracy across permutations of the same problem, and on average perform better on questions appearing in their original orthography. Our findings highlight the opaque nature of response generation in LLMs and provide evidence that prior data exposure contributes to overestimating the reasoning capabilities of frontier models.
TopoX: A Suite of Python Packages for Machine Learning on Topological Domains
Feb 07, 2024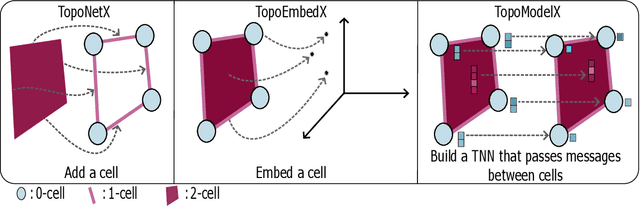
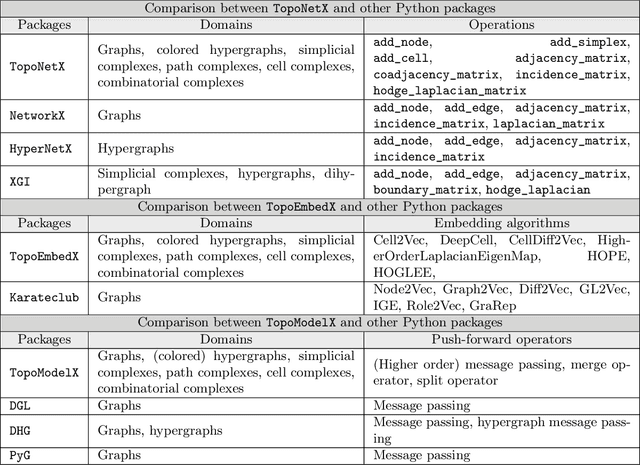
We introduce topox, a Python software suite that provides reliable and user-friendly building blocks for computing and machine learning on topological domains that extend graphs: hypergraphs, simplicial, cellular, path and combinatorial complexes. topox consists of three packages: toponetx facilitates constructing and computing on these domains, including working with nodes, edges and higher-order cells; topoembedx provides methods to embed topological domains into vector spaces, akin to popular graph-based embedding algorithms such as node2vec; topomodelx is built on top of PyTorch and offers a comprehensive toolbox of higher-order message passing functions for neural networks on topological domains. The extensively documented and unit-tested source code of topox is available under MIT license at https://github.com/pyt-team.
Stance Prediction and Claim Verification: An Arabic Perspective
May 21, 2020



This work explores the application of textual entailment in news claim verification and stance prediction using a new corpus in Arabic. The publicly available corpus comes in two perspectives: a version consisting of 4,547 true and false claims and a version consisting of 3,786 pairs (claim, evidence). We describe the methodology for creating the corpus and the annotation process. Using the introduced corpus, we also develop two machine learning baselines for two proposed tasks: claim verification and stance prediction. Our best model utilizes pretraining (BERT) and achieves 76.7 F1 on the stance prediction task and 64.3 F1 on the claim verification task. Our preliminary experiments shed some light on the limits of automatic claim verification that relies on claims text only. Results hint that while the linguistic features and world knowledge learned during pretraining are useful for stance prediction, such learned representations from pretraining are insufficient for verifying claims without access to context or evidence.