 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLINGOLY-TOO: Disentangling Memorisation from Reasoning with Linguistic Templatisation and Orthographic Obfuscation
Mar 04, 2025Effective evaluation of the reasoning capabilities of large language models (LLMs) are susceptible to overestimation due to data exposure of evaluation benchmarks. We introduce a framework for producing linguistic reasoning problems that reduces the effect of memorisation in model performance estimates and apply this framework to develop LINGOLY-TOO, a challenging evaluation benchmark for linguistic reasoning. By developing orthographic templates, we dynamically obfuscate the writing systems of real languages to generate numerous question variations. These variations preserve the reasoning steps required for each solution while reducing the likelihood of specific problem instances appearing in model training data. Our experiments demonstrate that frontier models, including OpenAI o1-preview and DeepSeem R1, struggle with advanced reasoning. Our analysis also shows that LLMs exhibit noticeable variance in accuracy across permutations of the same problem, and on average perform better on questions appearing in their original orthography. Our findings highlight the opaque nature of response generation in LLMs and provide evidence that prior data exposure contributes to overestimating the reasoning capabilities of frontier models.
State-Machine-Based Dialogue Agents with Few-Shot Contextual Semantic Parsers
Sep 16, 2020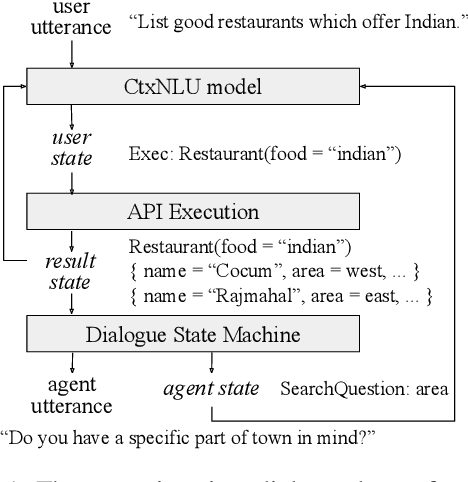
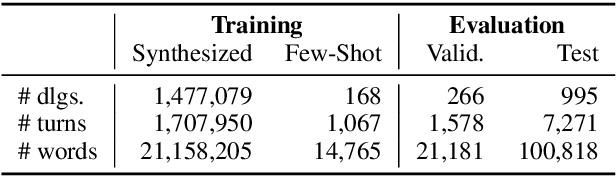

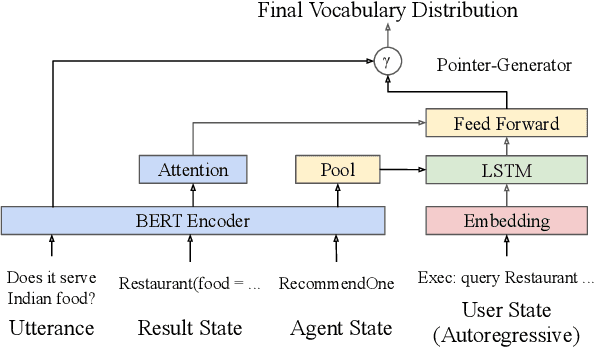
This paper presents a methodology and toolkit for creating a rule-based multi-domain conversational agent for transactions from (1) language annotations of the domains' database schemas and APIs and (2) a couple of hundreds of annotated human dialogues. There is no need for a large annotated training set, which is expensive to acquire. The toolkit uses a pre-defined abstract dialogue state machine to synthesize millions of dialogues based on the domains' information. The annotated and synthesized data are used to train a contextual semantic parser that interprets the user's latest utterance in the context of a formal representation of the conversation up to that point. Developers can refine the state machine to achieve higher accuracy. On the MultiWOZ benchmark, we achieve over 71% turn-by-turn slot accuracy on a cleaned, reannotated test set, without using any of the original training data. Our state machine can model 96% of the human agent turns. Our training strategy improves by 9% over a baseline that uses the same amount of hand-labeled data, showing the benefit of synthesizing data using the state machine.