 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful Embeddings of Irregular and Asynchronous Data for Online Log-NCDEs
May 28, 2026Continuous-time models are a natural choice for irregular and asynchronous data. A central design choice is how to embed discrete observations into continuous time. Interpolation- and imputation-based embeddings reconstruct a continuous observation path, making the model sensitive to the choice of reconstruction. We show that this reconstruction step is unnecessary; under mild conditions, compact-set universality on the model input space transfers to the data space whenever the embedding from data to input is continuous and injective. Guided by this result, and building on the rectilinear control path for Neural Controlled Differential Equations (NCDEs), we introduce a continuous and injective embedding for Log-NCDEs, a universal class of continuous-time models. Our approach records observations as increments and composes them over arbitrary query intervals to directly form log-signatures. This provides interval-level summaries without first interpolating the observed variables, while supporting online computation. Experiments on synthetic controlled dynamics and real-world time-series datasets show that the representation is accurate, efficient, and robust to irregular, asynchronous, and sparse observations.
Sig-DEG for Distillation: Making Diffusion Models Faster and Lighter
Aug 23, 2025Diffusion models have achieved state-of-the-art results in generative modelling but remain computationally intensive at inference time, often requiring thousands of discretization steps. To this end, we propose Sig-DEG (Signature-based Differential Equation Generator), a novel generator for distilling pre-trained diffusion models, which can universally approximate the backward diffusion process at a coarse temporal resolution. Inspired by high-order approximations of stochastic differential equations (SDEs), Sig-DEG leverages partial signatures to efficiently summarize Brownian motion over sub-intervals and adopts a recurrent structure to enable accurate global approximation of the SDE solution. Distillation is formulated as a supervised learning task, where Sig-DEG is trained to match the outputs of a fine-resolution diffusion model on a coarse time grid. During inference, Sig-DEG enables fast generation, as the partial signature terms can be simulated exactly without requiring fine-grained Brownian paths. Experiments demonstrate that Sig-DEG achieves competitive generation quality while reducing the number of inference steps by an order of magnitude. Our results highlight the effectiveness of signature-based approximations for efficient generative modeling.
Structured Linear CDEs: Maximally Expressive and Parallel-in-Time Sequence Models
May 23, 2025



Structured Linear Controlled Differential Equations (SLiCEs) provide a unifying framework for sequence models with structured, input-dependent state-transition matrices that retain the maximal expressivity of dense matrices whilst being cheaper to compute. The framework encompasses existing architectures, such as input-dependent block-diagonal linear recurrent neural networks and DeltaNet's diagonal-plus-low-rank structure, as well as two novel variants based on sparsity and the Walsh--Hadamard transform. We prove that, unlike the diagonal state-transition matrices of S4 and Mamba, SLiCEs employing block-diagonal, sparse, or Walsh--Hadamard matrices match the maximal expressivity of dense matrices. Empirically, SLiCEs solve the $A_5$ state-tracking benchmark with a single layer, achieve best-in-class length generalisation on regular language tasks among parallel-in-time models, and match the state-of-the-art performance of log neural controlled differential equations on six multivariate time-series classification datasets while cutting the average time per training step by a factor of twenty.
LINGOLY-TOO: Disentangling Memorisation from Reasoning with Linguistic Templatisation and Orthographic Obfuscation
Mar 04, 2025Effective evaluation of the reasoning capabilities of large language models (LLMs) are susceptible to overestimation due to data exposure of evaluation benchmarks. We introduce a framework for producing linguistic reasoning problems that reduces the effect of memorisation in model performance estimates and apply this framework to develop LINGOLY-TOO, a challenging evaluation benchmark for linguistic reasoning. By developing orthographic templates, we dynamically obfuscate the writing systems of real languages to generate numerous question variations. These variations preserve the reasoning steps required for each solution while reducing the likelihood of specific problem instances appearing in model training data. Our experiments demonstrate that frontier models, including OpenAI o1-preview and DeepSeem R1, struggle with advanced reasoning. Our analysis also shows that LLMs exhibit noticeable variance in accuracy across permutations of the same problem, and on average perform better on questions appearing in their original orthography. Our findings highlight the opaque nature of response generation in LLMs and provide evidence that prior data exposure contributes to overestimating the reasoning capabilities of frontier models.
Improving In-Context Learning with Small Language Model Ensembles
Oct 29, 2024Large language models (LLMs) have shown impressive capabilities across various tasks, but their performance on domain-specific tasks remains limited. While methods like retrieval augmented generation and fine-tuning can help to address this, they require significant resources. In-context learning (ICL) is a cheap and efficient alternative but cannot match the accuracies of advanced methods. We present Ensemble SuperICL, a novel approach that enhances ICL by leveraging the expertise of multiple fine-tuned small language models (SLMs). Ensemble SuperICL achieves state of the art (SoTA) results on several natural language understanding benchmarks. Additionally, we test it on a medical-domain labelling task and showcase its practicality by using off-the-shelf SLMs fine-tuned on a general language task, achieving superior accuracy in large-scale data labelling compared to all baselines. Finally, we conduct an ablation study and sensitivity analyses to elucidate the underlying mechanism of Ensemble SuperICL. Our research contributes to the growing demand for efficient domain specialisation methods in LLMs, offering a cheap and effective method for practitioners.
Q-learning as a monotone scheme
May 30, 2024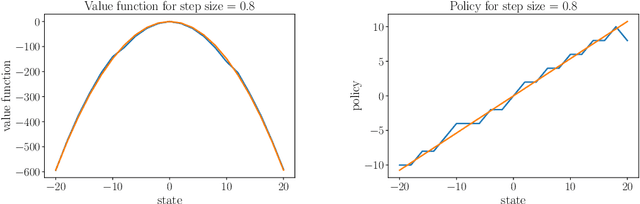
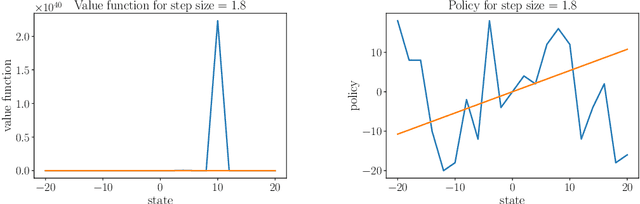
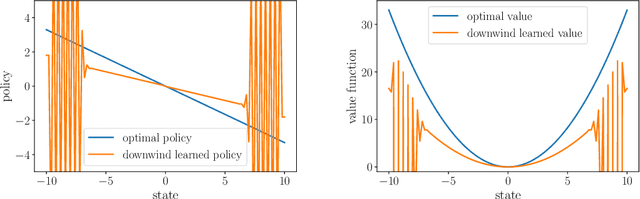
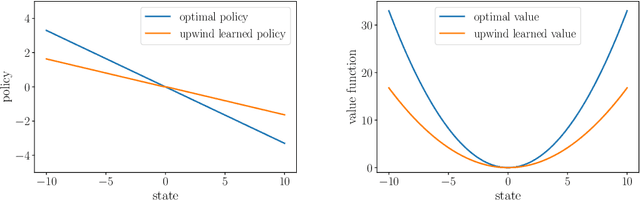
Stability issues with reinforcement learning methods persist. To better understand some of these stability and convergence issues involving deep reinforcement learning methods, we examine a simple linear quadratic example. We interpret the convergence criterion of exact Q-learning in the sense of a monotone scheme and discuss consequences of function approximation on monotonicity properties.
Neural Controlled Differential Equations with Quantum Hidden Evolutions
Apr 30, 2024
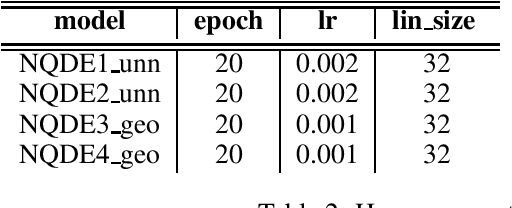
We introduce a class of neural controlled differential equation inspired by quantum mechanics. Neural quantum controlled differential equations (NQDEs) model the dynamics by analogue of the Schr\"{o}dinger equation. Specifically, the hidden state represents the wave function, and its collapse leads to an interpretation of the classification probability. We implement and compare the results of four variants of NQDEs on a toy spiral classification problem.
Is ChatGPT Involved in Texts? Measure the Polish Ratio to Detect ChatGPT-Generated Text
Jul 21, 2023The remarkable capabilities of large-scale language models, such as ChatGPT, in text generation have incited awe and spurred researchers to devise detectors to mitigate potential risks, including misinformation, phishing, and academic dishonesty. Despite this, most previous studies, including HC3, have been predominantly geared towards creating detectors that differentiate between purely ChatGPT-generated texts and human-authored texts. This approach, however, fails to work on discerning texts generated through human-machine collaboration, such as ChatGPT-polished texts. Addressing this gap, we introduce a novel dataset termed HPPT (ChatGPT-polished academic abstracts), facilitating the construction of more robust detectors. It diverges from extant corpora by comprising pairs of human-written and ChatGPT-polished abstracts instead of purely ChatGPT-generated texts. Additionally, we propose the "Polish Ratio" method, an innovative measure of ChatGPT's involvement in text generation based on editing distance. It provides a mechanism to measure the degree of human originality in the resulting text. Our experimental results show our proposed model has better robustness on the HPPT dataset and two existing datasets (HC3 and CDB). Furthermore, the "Polish Ratio" we proposed offers a more comprehensive explanation by quantifying the degree of ChatGPT involvement, which indicates that a Polish Ratio value greater than 0.2 signifies ChatGPT involvement and a value exceeding 0.6 implies that ChatGPT generates most of the text.
Neural Controlled Differential Equations for Online Prediction Tasks
Jun 21, 2021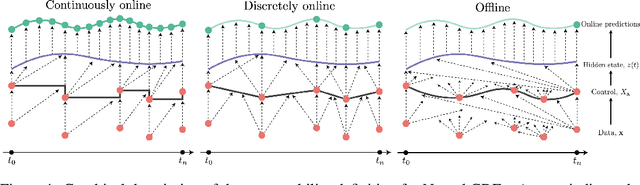

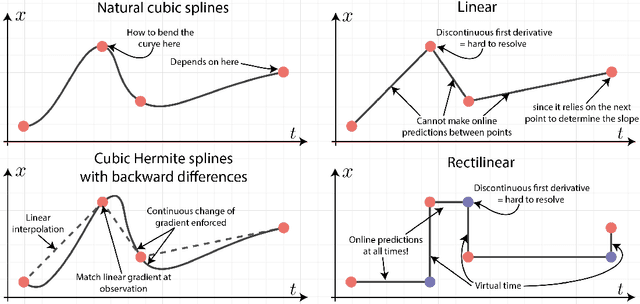
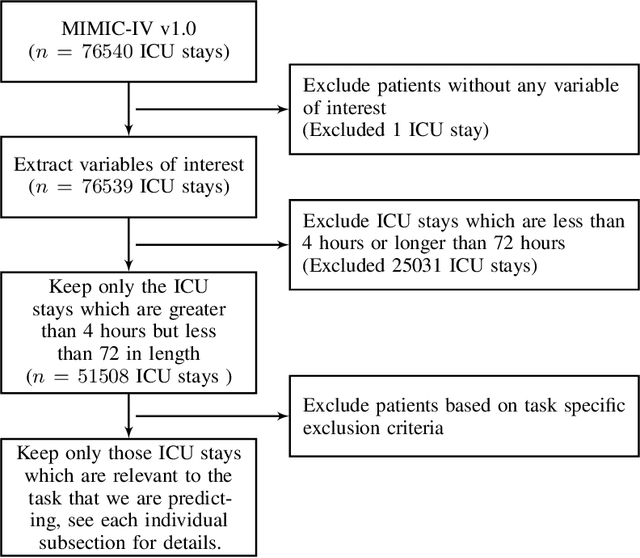
Neural controlled differential equations (Neural CDEs) are a continuous-time extension of recurrent neural networks (RNNs), achieving state-of-the-art (SOTA) performance at modelling functions of irregular time series. In order to interpret discrete data in continuous time, current implementations rely on non-causal interpolations of the data. This is fine when the whole time series is observed in advance, but means that Neural CDEs are not suitable for use in \textit{online prediction tasks}, where predictions need to be made in real-time: a major use case for recurrent networks. Here, we show how this limitation may be rectified. First, we identify several theoretical conditions that interpolation schemes for Neural CDEs should satisfy, such as boundedness and uniqueness. Second, we use these to motivate the introduction of new schemes that address these conditions, offering in particular measurability (for online prediction), and smoothness (for speed). Third, we empirically benchmark our online Neural CDE model on three continuous monitoring tasks from the MIMIC-IV medical database: we demonstrate improved performance on all tasks against ODE benchmarks, and on two of the three tasks against SOTA non-ODE benchmarks.