 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Subspace Cubic-Regularization Methods, with Applications to Low-Rank Functions
Jan 16, 2025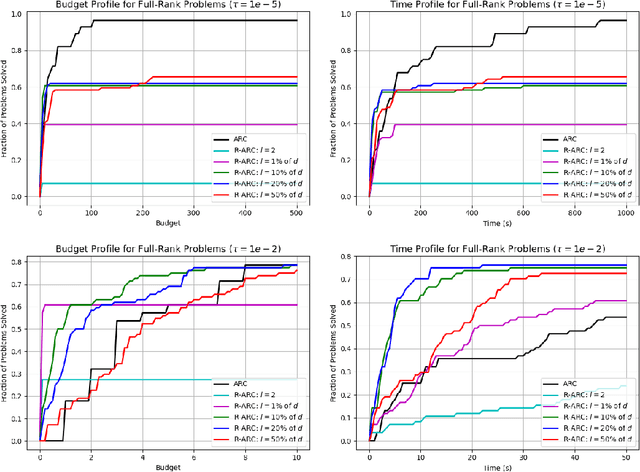


We propose and analyze random subspace variants of the second-order Adaptive Regularization using Cubics (ARC) algorithm. These methods iteratively restrict the search space to some random subspace of the parameters, constructing and minimizing a local model only within this subspace. Thus, our variants only require access to (small-dimensional) projections of first- and second-order problem derivatives and calculate a reduced step inexpensively. Under suitable assumptions, the ensuing methods maintain the optimal first-order, and second-order, global rates of convergence of (full-dimensional) cubic regularization, while showing improved scalability both theoretically and numerically, particularly when applied to low-rank functions. When applied to the latter, our adaptive variant naturally adapts the subspace size to the true rank of the function, without knowing it a priori.
Neural Controlled Differential Equations with Quantum Hidden Evolutions
Apr 30, 2024
We introduce a class of neural controlled differential equation inspired by quantum mechanics. Neural quantum controlled differential equations (NQDEs) model the dynamics by analogue of the Schr\"{o}dinger equation. Specifically, the hidden state represents the wave function, and its collapse leads to an interpretation of the classification probability. We implement and compare the results of four variants of NQDEs on a toy spiral classification problem.
A Randomised Subspace Gauss-Newton Method for Nonlinear Least-Squares
Nov 10, 2022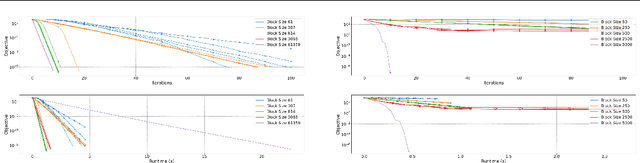
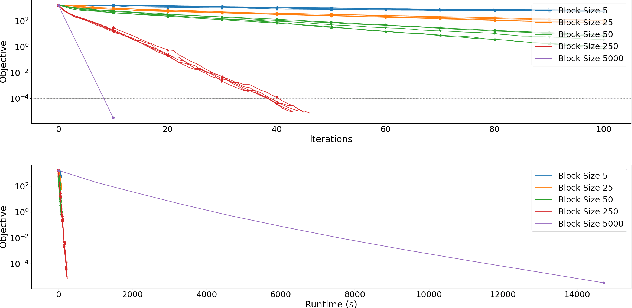
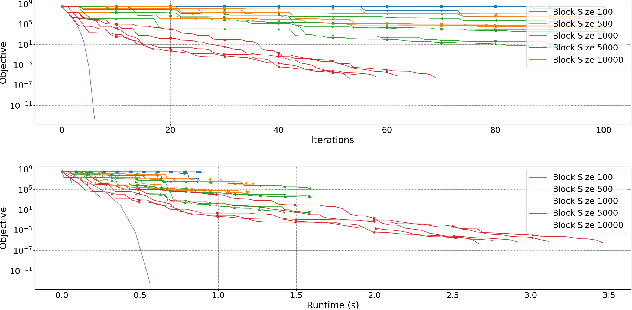
We propose a Randomised Subspace Gauss-Newton (R-SGN) algorithm for solving nonlinear least-squares optimization problems, that uses a sketched Jacobian of the residual in the variable domain and solves a reduced linear least-squares on each iteration. A sublinear global rate of convergence result is presented for a trust-region variant of R-SGN, with high probability, which matches deterministic counterpart results in the order of the accuracy tolerance. Promising preliminary numerical results are presented for R-SGN on logistic regression and on nonlinear regression problems from the CUTEst collection.
* This work first appears in Thirty-seventh International Conference on Machine Learning, 2020, in Workshop on Beyond First Order Methods in ML Systems. https://sites.google.com/view/optml-icml2020/accepted-papers?authuser=0. arXiv admin note: text overlap with arXiv:2206.03371
Johnson-Lindenstrauss embeddings for noisy vectors -- taking advantage of the noise
Sep 01, 2022
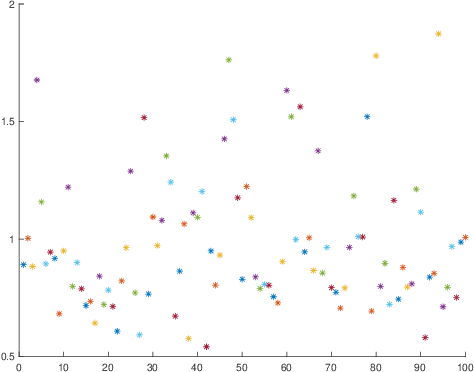
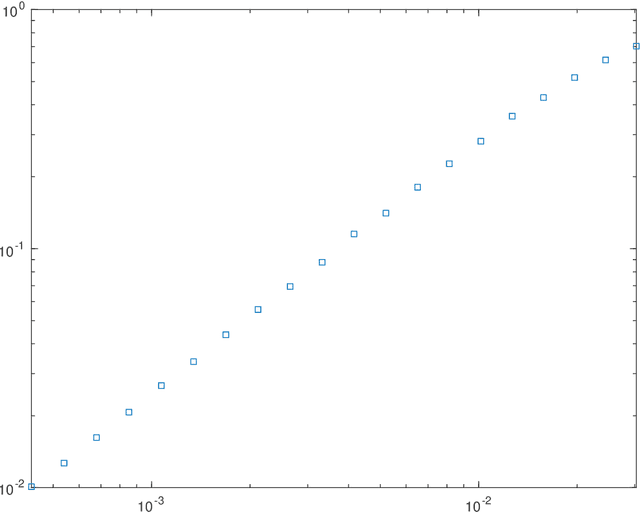
This paper investigates theoretical properties of subsampling and hashing as tools for approximate Euclidean norm-preserving embeddings for vectors with (unknown) additive Gaussian noises. Such embeddings are sometimes called Johnson-lindenstrauss embeddings due to their celebrated lemma. Previous work shows that as sparse embeddings, the success of subsampling and hashing closely depends on the $l_\infty$ to $l_2$ ratios of the vector to be mapped. This paper shows that the presence of noise removes such constrain in high-dimensions, in other words, sparse embeddings such as subsampling and hashing with comparable embedding dimensions to dense embeddings have similar approximate norm-preserving dimensionality-reduction properties. The key is that the noise should be treated as an information to be exploited, not simply something to be removed. Theoretical bounds for subsampling and hashing to recover the approximate norm of a high dimension vector in the presence of noise are derived, with numerical illustrations showing better performances are achieved in the presence of noise.
Hashing embeddings of optimal dimension, with applications to linear least squares
May 25, 2021

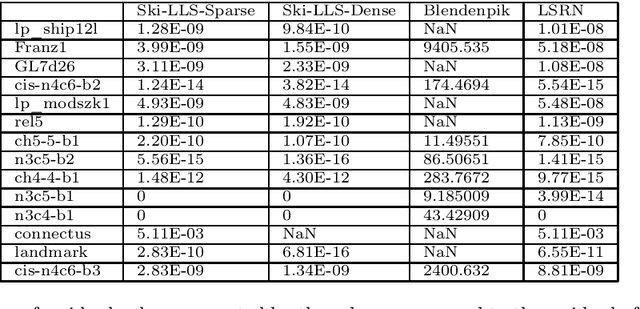

The aim of this paper is two-fold: firstly, to present subspace embedding properties for $s$-hashing sketching matrices, with $s\geq 1$, that are optimal in the projection dimension $m$ of the sketch, namely, $m=\mathcal{O}(d)$, where $d$ is the dimension of the subspace. A diverse set of results are presented that address the case when the input matrix has sufficiently low coherence (thus removing the $\log^2 d$ factor dependence in $m$, in the low-coherence result of Bourgain et al (2015) at the expense of a smaller coherence requirement); how this coherence changes with the number $s$ of column nonzeros (allowing a scaling of $\sqrt{s}$ of the coherence bound), or is reduced through suitable transformations (when considering hashed -- instead of subsampled -- coherence reducing transformations such as randomised Hadamard). Secondly, we apply these general hashing sketching results to the special case of Linear Least Squares (LLS), and develop Ski-LLS, a generic software package for these problems, that builds upon and improves the Blendenpik solver on dense input and the (sequential) LSRN performance on sparse problems. In addition to the hashing sketching improvements, we add suitable linear algebra tools for rank-deficient and for sparse problems that lead Ski-LLS to outperform not only sketching-based routines on randomly generated input, but also state of the art direct solver SPQR and iterative code HSL on certain subsets of the sparse Florida matrix collection; namely, on least squares problems that are significantly overdetermined, or moderately sparse, or difficult.