 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Linear CDEs: Maximally Expressive and Parallel-in-Time Sequence Models
May 23, 2025



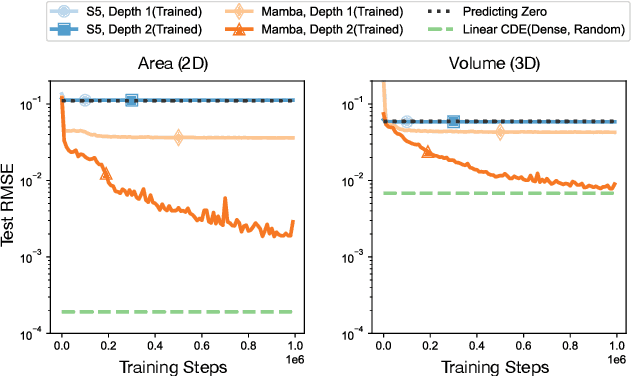
Structured Linear Controlled Differential Equations (SLiCEs) provide a unifying framework for sequence models with structured, input-dependent state-transition matrices that retain the maximal expressivity of dense matrices whilst being cheaper to compute. The framework encompasses existing architectures, such as input-dependent block-diagonal linear recurrent neural networks and DeltaNet's diagonal-plus-low-rank structure, as well as two novel variants based on sparsity and the Walsh--Hadamard transform. We prove that, unlike the diagonal state-transition matrices of S4 and Mamba, SLiCEs employing block-diagonal, sparse, or Walsh--Hadamard matrices match the maximal expressivity of dense matrices. Empirically, SLiCEs solve the $A_5$ state-tracking benchmark with a single layer, achieve best-in-class length generalisation on regular language tasks among parallel-in-time models, and match the state-of-the-art performance of log neural controlled differential equations on six multivariate time-series classification datasets while cutting the average time per training step by a factor of twenty.
ParallelFlow: Parallelizing Linear Transformers via Flow Discretization
Apr 01, 2025


We present a theoretical framework for analyzing linear attention models through matrix-valued state space models (SSMs). Our approach, Parallel Flows, provides a perspective that systematically decouples temporal dynamics from implementation constraints, enabling independent analysis of critical algorithmic components: chunking, parallelization, and information aggregation. Central to this framework is the reinterpretation of chunking procedures as computations of the flows governing system dynamics. This connection establishes a bridge to mathematical tools from rough path theory, opening the door to new insights into sequence modeling architectures. As a concrete application, we analyze DeltaNet in a generalized low-rank setting motivated by recent theoretical advances. Our methods allow us to design simple, streamlined generalizations of hardware-efficient algorithms present in the literature, and to provide completely different ones, inspired by rough paths techniques, with provably lower complexity. This dual contribution demonstrates how principled theoretical analysis can both explain existing practical methods and inspire fundamentally new computational approaches.
Fixed-Point RNNs: From Diagonal to Dense in a Few Iterations
Mar 13, 2025



Linear recurrent neural networks (RNNs) and state-space models (SSMs) such as Mamba have become promising alternatives to softmax-attention as sequence mixing layers in Transformer architectures. Current models, however, do not exhibit the full state-tracking expressivity of RNNs because they rely on channel-wise (i.e. diagonal) sequence mixing. In this paper, we propose to compute a dense linear RNN as the fixed-point of a parallelizable diagonal linear RNN in a single layer. We explore mechanisms to improve its memory and state-tracking abilities in practice, and achieve state-of-the-art results on the commonly used toy tasks $A_5$, $S_5$, copying, and modular arithmetics. We hope our results will open new avenues to more expressive and efficient sequence mixers.
Signature Reconstruction from Randomized Signatures
Feb 05, 2025



Controlled ordinary differential equations driven by continuous bounded variation curves can be considered a continuous time analogue of recurrent neural networks for the construction of expressive features of the input curves. We ask up to which extent well known signature features of such curves can be reconstructed from controlled ordinary differential equations with (untrained) random vector fields. The answer turns out to be algebraically involved, but essentially the number of signature features, which can be reconstructed from the non-linear flow of the controlled ordinary differential equation, is exponential in its hidden dimension, when the vector fields are chosen to be neural with depth two. Moreover, we characterize a general linear independence condition on arbitrary vector fields, under which the signature features up to some fixed order can always be reconstructed. Algebraically speaking this complements in a quantitative manner several well known results from the theory of Lie algebras of vector fields and puts them in a context of machine learning.
Rough kernel hedging
Jan 16, 2025

Building on the functional-analytic framework of operator-valued kernels and un-truncated signature kernels, we propose a scalable, provably convergent signature-based algorithm for a broad class of high-dimensional, path-dependent hedging problems. We make minimal assumptions about market dynamics by modelling them as general geometric rough paths, yielding a fully model-free approach. Furthermore, through a representer theorem, we provide theoretical guarantees on the existence and uniqueness of a global minimum for the resulting optimization problem and derive an analytic solution under highly general loss functions. Similar to the popular deep hedging approach, but in a more rigorous fashion, our method can also incorporate additional features via the underlying operator-valued kernel, such as trading signals, news analytics, and past hedging decisions, closely aligning with true machine-learning practice.
Graph Expansions of Deep Neural Networks and their Universal Scaling Limits
Jul 11, 2024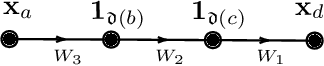


We present a unified approach to obtain scaling limits of neural networks using the genus expansion technique from random matrix theory. This approach begins with a novel expansion of neural networks which is reminiscent of Butcher series for ODEs, and is obtained through a generalisation of Fa\`a di Bruno's formula to an arbitrary number of compositions. In this expansion, the role of monomials is played by random multilinear maps indexed by directed graphs whose edges correspond to random matrices, which we call operator graphs. This expansion linearises the effect of the activation functions, allowing for the direct application of Wick's principle to compute the expectation of each of its terms. We then determine the leading contribution to each term by embedding the corresponding graphs onto surfaces, and computing their Euler characteristic. Furthermore, by developing a correspondence between analytic and graphical operations, we obtain similar graph expansions for the neural tangent kernel as well as the input-output Jacobian of the original neural network, and derive their infinite-width limits with relative ease. Notably, we find explicit formulae for the moments of the limiting singular value distribution of the Jacobian. We then show that all of these results hold for networks with more general weights, such as general matrices with i.i.d. entries satisfying moment assumptions, complex matrices and sparse matrices.
Theoretical Foundations of Deep Selective State-Space Models
Mar 04, 2024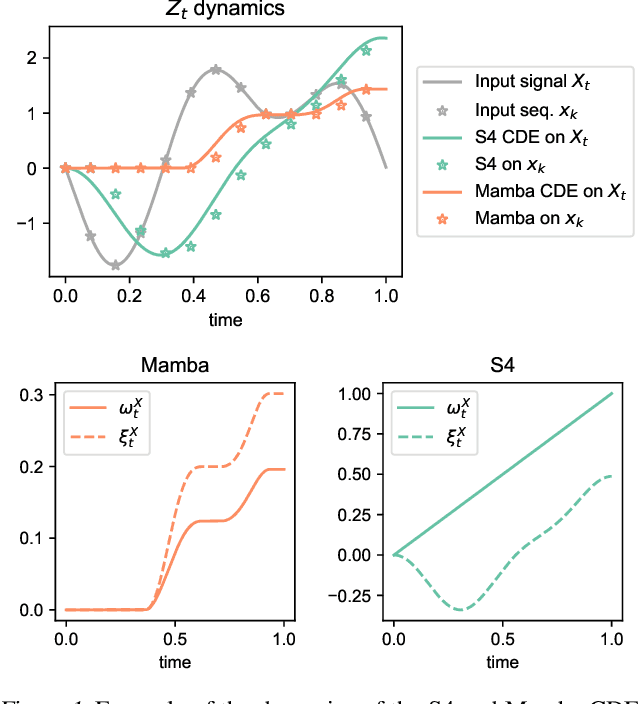
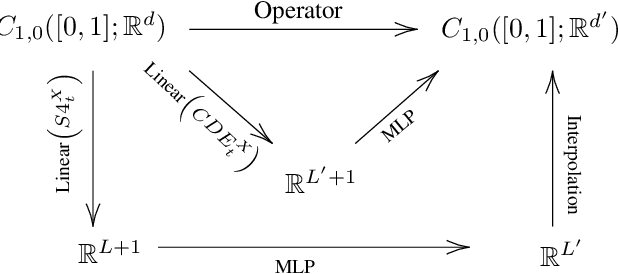
Structured state-space models (SSMs) such as S4, stemming from the seminal work of Gu et al., are gaining popularity as effective approaches for modeling sequential data. Deep SSMs demonstrate outstanding performance across a diverse set of domains, at a reduced training and inference cost compared to attention-based transformers. Recent developments show that if the linear recurrence powering SSMs allows for multiplicative interactions between inputs and hidden states (e.g. GateLoop, Mamba, GLA), then the resulting architecture can surpass in both in accuracy and efficiency attention-powered foundation models trained on text, at scales of billion parameters. In this paper, we give theoretical grounding to this recent finding using tools from Rough Path Theory: we show that when random linear recurrences are equipped with simple input-controlled transitions (selectivity mechanism), then the hidden state is provably a low-dimensional projection of a powerful mathematical object called the signature of the input -- capturing non-linear interactions between tokens at distinct timescales. Our theory not only motivates the success of modern selective state-space models such as Mamba but also provides a solid framework to understand the expressive power of future SSM variants.
Neural signature kernels as infinite-width-depth-limits of controlled ResNets
Mar 30, 2023


Motivated by the paradigm of reservoir computing, we consider randomly initialized controlled ResNets defined as Euler-discretizations of neural controlled differential equations (Neural CDEs). We show that in the infinite-width-then-depth limit and under proper scaling, these architectures converge weakly to Gaussian processes indexed on some spaces of continuous paths and with kernels satisfying certain partial differential equations (PDEs) varying according to the choice of activation function. In the special case where the activation is the identity, we show that the equation reduces to a linear PDE and the limiting kernel agrees with the signature kernel of Salvi et al. (2021). In this setting, we also show that the width-depth limits commute. We name this new family of limiting kernels neural signature kernels. Finally, we show that in the infinite-depth regime, finite-width controlled ResNets converge in distribution to Neural CDEs with random vector fields which, depending on whether the weights are shared across layers, are either time-independent and Gaussian or behave like a matrix-valued Brownian motion.