 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe PRISM Alignment Project: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models
Paper and Code
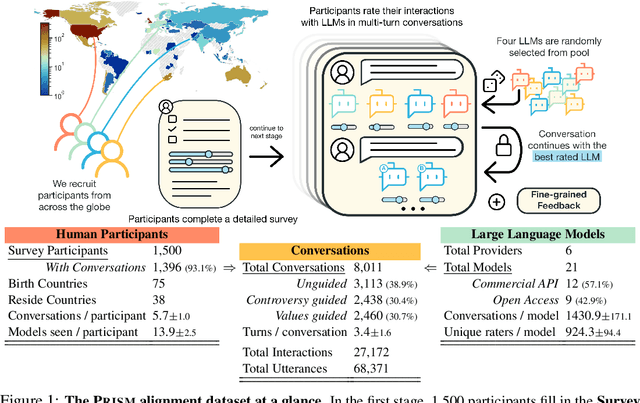
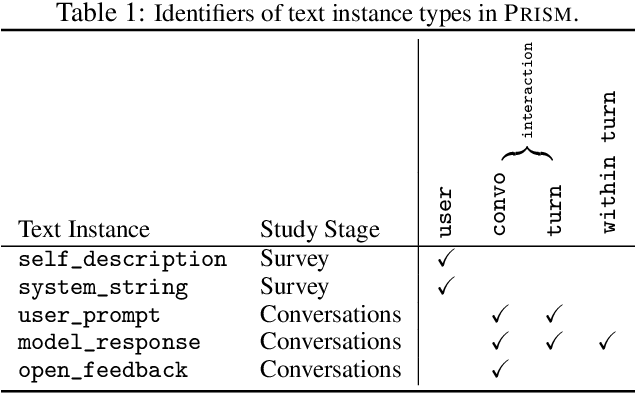
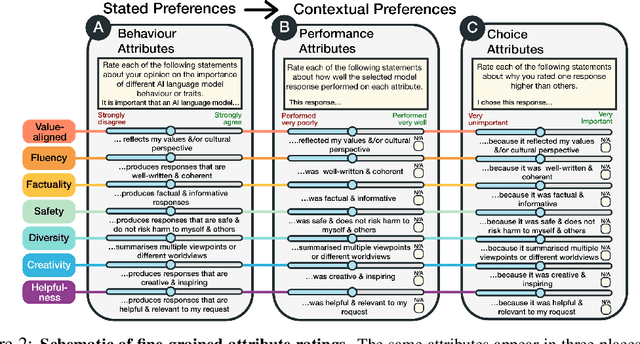

Human feedback plays a central role in the alignment of Large Language Models (LLMs). However, open questions remain about the methods (how), domains (where), people (who) and objectives (to what end) of human feedback collection. To navigate these questions, we introduce PRISM, a new dataset which maps the sociodemographics and stated preferences of 1,500 diverse participants from 75 countries, to their contextual preferences and fine-grained feedback in 8,011 live conversations with 21 LLMs. PRISM contributes (i) wide geographic and demographic participation in human feedback data; (ii) two census-representative samples for understanding collective welfare (UK and US); and (iii) individualised feedback where every rating is linked to a detailed participant profile, thus permitting exploration of personalisation and attribution of sample artefacts. We focus on collecting conversations that centre subjective and multicultural perspectives on value-laden and controversial topics, where we expect the most interpersonal and cross-cultural disagreement. We demonstrate the usefulness of PRISM via three case studies of dialogue diversity, preference diversity, and welfare outcomes, showing that it matters which humans set alignment norms. As well as offering a rich community resource, we advocate for broader participation in AI development and a more inclusive approach to technology design.