 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Reward Models with Synthetic Critiques
Paper and Code


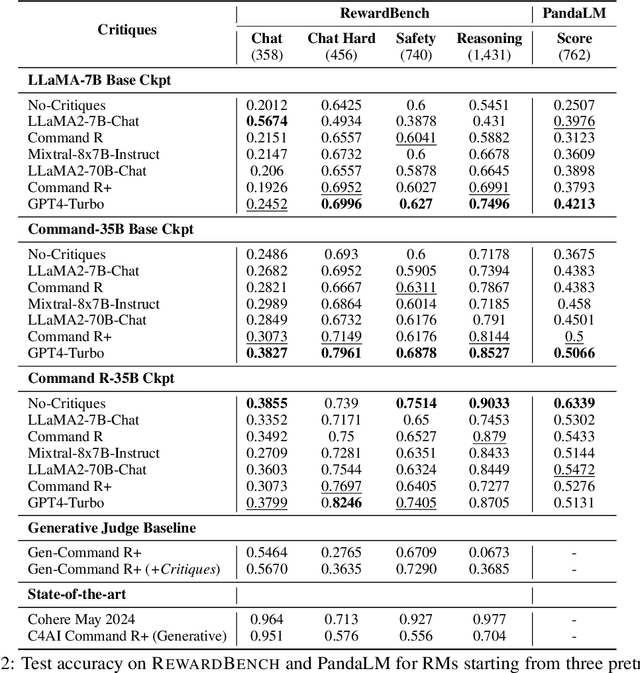
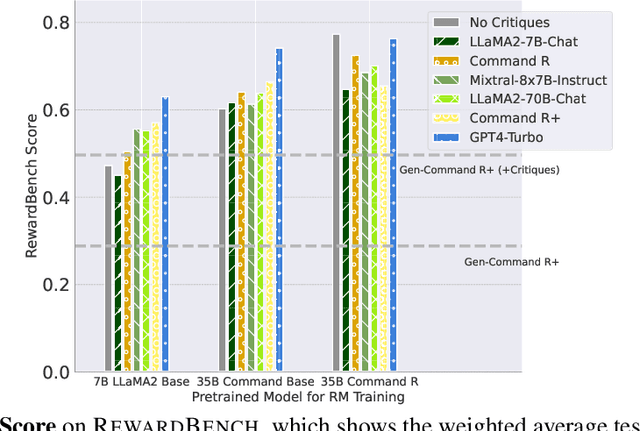
Reward models (RM) play a critical role in aligning language models through the process of reinforcement learning from human feedback. RMs are trained to predict a score reflecting human preference, which requires significant time and cost for human annotation. Additionally, RMs tend to quickly overfit on superficial features in the training set, hindering their generalization performance on unseen distributions. We propose a novel approach using synthetic natural language critiques generated by large language models to provide additional feedback, evaluating aspects such as instruction following, correctness, and style. This offers richer signals and more robust features for RMs to assess and score on. We demonstrate that high-quality critiques improve the performance and data efficiency of RMs initialized from different pretrained models. Conversely, we also show that low-quality critiques negatively impact performance. Furthermore, incorporating critiques enhances the interpretability and robustness of RM training.