 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuotient Normalized Maximum Likelihood Criterion for Learning Bayesian Network Structures
Aug 27, 2024We introduce an information theoretic criterion for Bayesian network structure learning which we call quotient normalized maximum likelihood (qNML). In contrast to the closely related factorized normalized maximum likelihood criterion, qNML satisfies the property of score equivalence. It is also decomposable and completely free of adjustable hyperparameters. For practical computations, we identify a remarkably accurate approximation proposed earlier by Szpankowski and Weinberger. Experiments on both simulated and real data demonstrate that the new criterion leads to parsimonious models with good predictive accuracy.
* Accepted to AISTATS 2018
Multi-Agent Path Finding with Real Robot Dynamics and Interdependent Tasks for Automated Warehouses
Aug 26, 2024Multi-Agent Path Finding (MAPF) is an important optimization problem underlying the deployment of robots in automated warehouses and factories. Despite the large body of work on this topic, most approaches make heavy simplifications, both on the environment and the agents, which make the resulting algorithms impractical for real-life scenarios. In this paper, we consider a realistic problem of online order delivery in a warehouse, where a fleet of robots bring the products belonging to each order from shelves to workstations. This creates a stream of inter-dependent pickup and delivery tasks and the associated MAPF problem consists of computing realistic collision-free robot trajectories fulfilling these tasks. To solve this MAPF problem, we propose an extension of the standard Prioritized Planning algorithm to deal with the inter-dependent tasks (Interleaved Prioritized Planning) and a novel Via-Point Star (VP*) algorithm to compute an optimal dynamics-compliant robot trajectory to visit a sequence of goal locations while avoiding moving obstacles. We prove the completeness of our approach and evaluate it in simulation as well as in a real warehouse.
Learning Synthetic to Real Transfer for Localization and Navigational Tasks
Nov 23, 2020



Autonomous navigation consists in an agent being able to navigate without human intervention or supervision, it affects both high level planning and low level control. Navigation is at the crossroad of multiple disciplines, it combines notions of computer vision, robotics and control. This work aimed at creating, in a simulation, a navigation pipeline whose transfer to the real world could be done with as few efforts as possible. Given the limited time and the wide range of problematic to be tackled, absolute navigation performances while important was not the main objective. The emphasis was rather put on studying the sim2real gap which is one the major bottlenecks of modern robotics and autonomous navigation. To design the navigation pipeline four main challenges arise; environment, localization, navigation and planning. The iGibson simulator is picked for its photo-realistic textures and physics engine. A topological approach to tackle space representation was picked over metric approaches because they generalize better to new environments and are less sensitive to change of conditions. The navigation pipeline is decomposed as a localization module, a planning module and a local navigation module. These modules utilize three different networks, an image representation extractor, a passage detector and a local policy. The laters are trained on specifically tailored tasks with some associated datasets created for those specific tasks. Localization is the ability for the agent to localize itself against a specific space representation. It must be reliable, repeatable and robust to a wide variety of transformations. Localization is tackled as an image retrieval task using a deep neural network trained on an auxiliary task as a feature descriptor extractor. The local policy is trained with behavioral cloning from expert trajectories gathered with ROS navigation stack.
Non-Markovian Control with Gated End-to-End Memory Policy Networks
May 31, 2017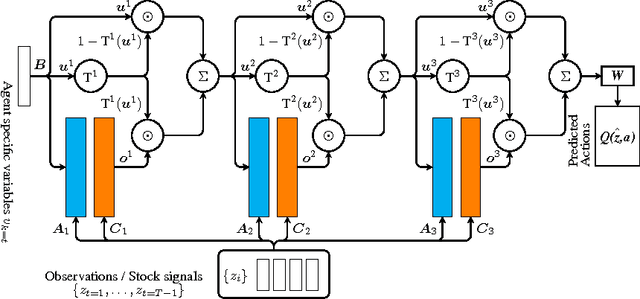
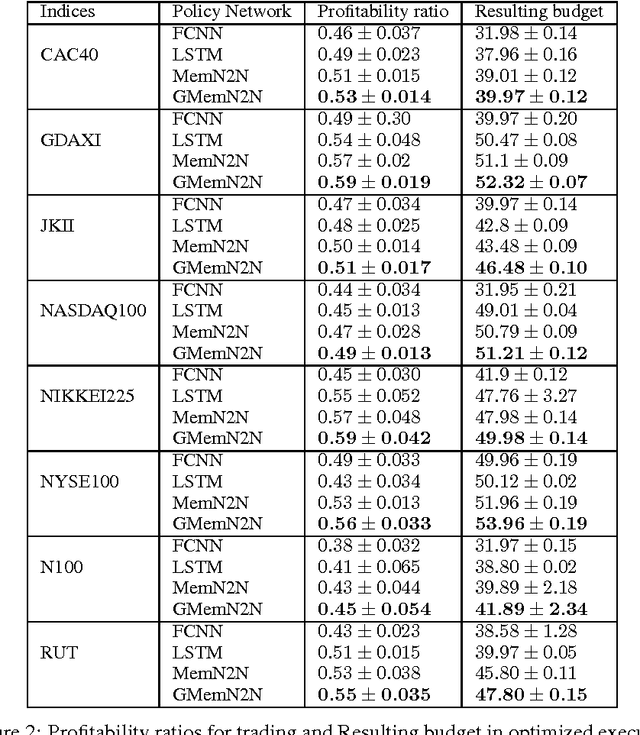
Partially observable environments present an important open challenge in the domain of sequential control learning with delayed rewards. Despite numerous attempts during the two last decades, the majority of reinforcement learning algorithms and associated approximate models, applied to this context, still assume Markovian state transitions. In this paper, we explore the use of a recently proposed attention-based model, the Gated End-to-End Memory Network, for sequential control. We call the resulting model the Gated End-to-End Memory Policy Network. More precisely, we use a model-free value-based algorithm to learn policies for partially observed domains using this memory-enhanced neural network. This model is end-to-end learnable and it features unbounded memory. Indeed, because of its attention mechanism and associated non-parametric memory, the proposed model allows us to define an attention mechanism over the observation stream unlike recurrent models. We show encouraging results that illustrate the capability of our attention-based model in the context of the continuous-state non-stationary control problem of stock trading. We also present an OpenAI Gym environment for simulated stock exchange and explain its relevance as a benchmark for the field of non-Markovian decision process learning.
Optimal Policies for Observing Time Series and Related Restless Bandit Problems
Mar 29, 2017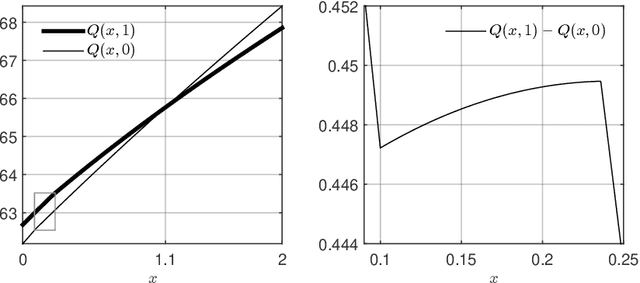
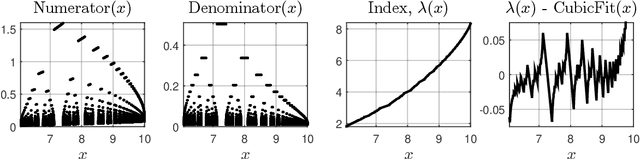
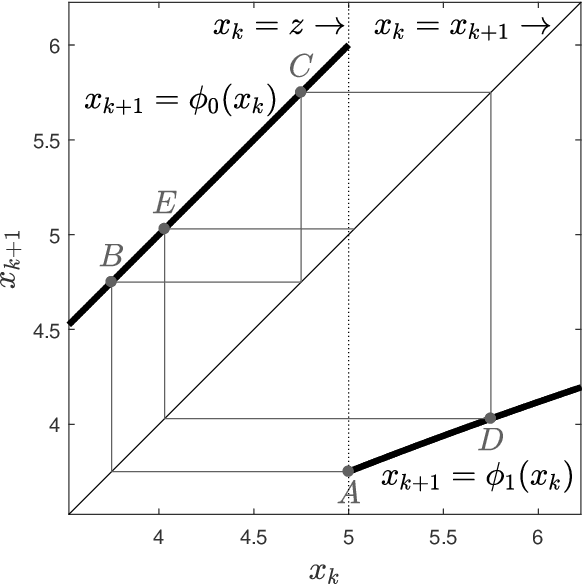

The trade-off between the cost of acquiring and processing data, and uncertainty due to a lack of data is fundamental in machine learning. A basic instance of this trade-off is the problem of deciding when to make noisy and costly observations of a discrete-time Gaussian random walk, so as to minimise the posterior variance plus observation costs. We present the first proof that a simple policy, which observes when the posterior variance exceeds a threshold, is optimal for this problem. The proof generalises to a wide range of cost functions other than the posterior variance. This result implies that optimal policies for linear-quadratic-Gaussian control with costly observations have a threshold structure. It also implies that the restless bandit problem of observing multiple such time series, has a well-defined Whittle index. We discuss computation of that index, give closed-form formulae for it, and compare the performance of the associated index policy with heuristic policies. The proof is based on a new verification theorem that demonstrates threshold structure for Markov decision processes, and on the relation between binary sequences known as mechanical words and the dynamics of discontinuous nonlinear maps, which frequently arise in physics, control and biology.
When are Kalman-filter restless bandits indexable?
Sep 15, 2015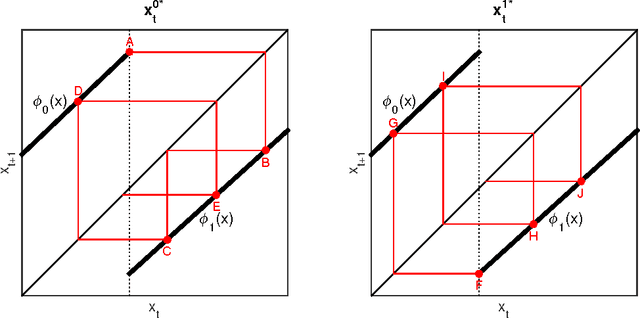


We study the restless bandit associated with an extremely simple scalar Kalman filter model in discrete time. Under certain assumptions, we prove that the problem is indexable in the sense that the Whittle index is a non-decreasing function of the relevant belief state. In spite of the long history of this problem, this appears to be the first such proof. We use results about Schur-convexity and mechanical words, which are particular binary strings intimately related to palindromes.
Minimum Encoding Approaches for Predictive Modeling
Jan 30, 2013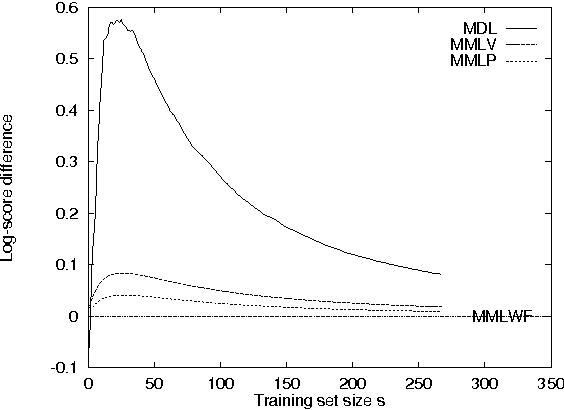
We analyze differences between two information-theoretically motivated approaches to statistical inference and model selection: the Minimum Description Length (MDL) principle, and the Minimum Message Length (MML) principle. Based on this analysis, we present two revised versions of MML: a pointwise estimator which gives the MML-optimal single parameter model, and a volumewise estimator which gives the MML-optimal region in the parameter space. Our empirical results suggest that with small data sets, the MDL approach yields more accurate predictions than the MML estimators. The empirical results also demonstrate that the revised MML estimators introduced here perform better than the original MML estimator suggested by Wallace and Freeman.
On Supervised Selection of Bayesian Networks
Jan 23, 2013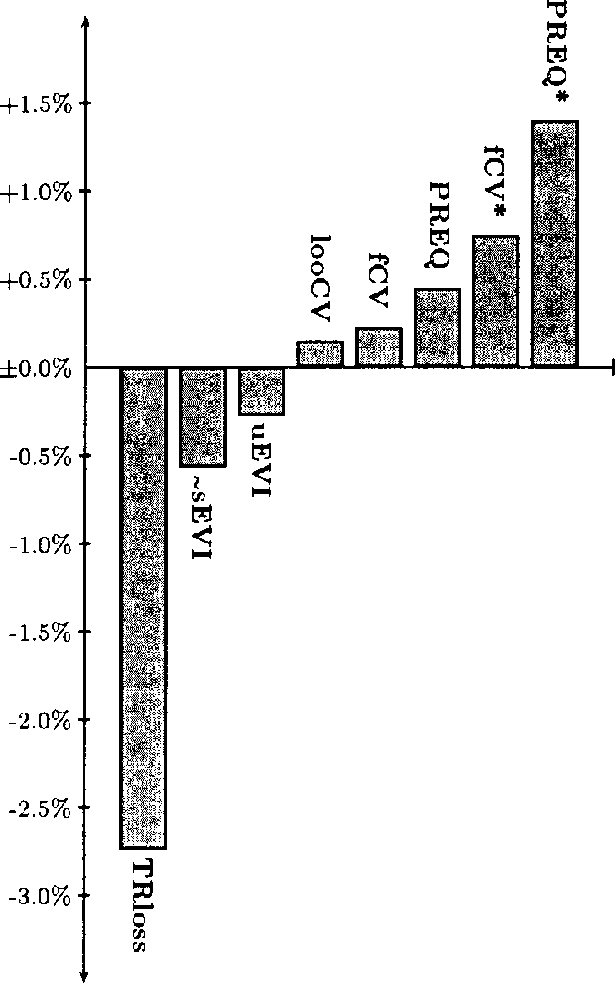
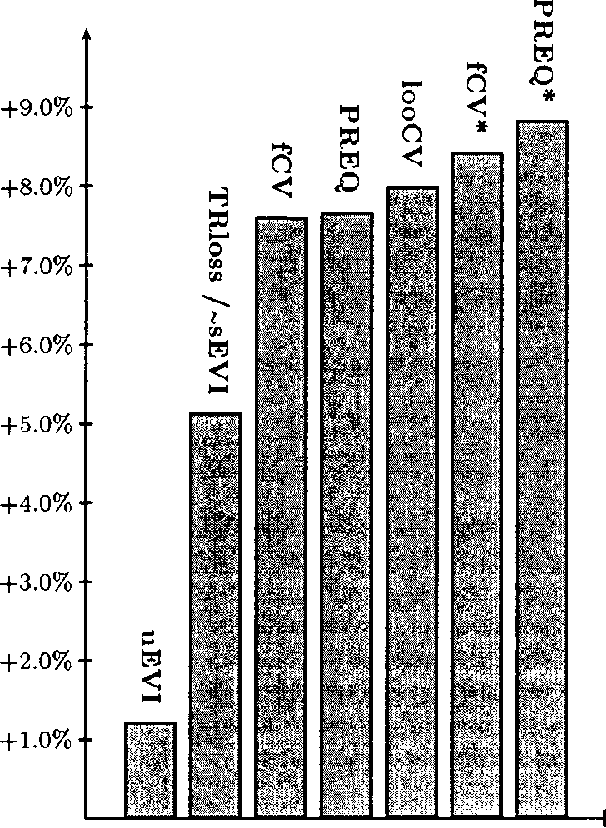
Given a set of possible models (e.g., Bayesian network structures) and a data sample, in the unsupervised model selection problem the task is to choose the most accurate model with respect to the domain joint probability distribution. In contrast to this, in supervised model selection it is a priori known that the chosen model will be used in the future for prediction tasks involving more ``focused' predictive distributions. Although focused predictive distributions can be produced from the joint probability distribution by marginalization, in practice the best model in the unsupervised sense does not necessarily perform well in supervised domains. In particular, the standard marginal likelihood score is a criterion for the unsupervised task, and, although frequently used for supervised model selection also, does not perform well in such tasks. In this paper we study the performance of the marginal likelihood score empirically in supervised Bayesian network selection tasks by using a large number of publicly available classification data sets, and compare the results to those obtained by alternative model selection criteria, including empirical crossvalidation methods, an approximation of a supervised marginal likelihood measure, and a supervised version of Dawids prequential(predictive sequential) principle.The results demonstrate that the marginal likelihood score does NOT perform well FOR supervised model selection, WHILE the best results are obtained BY using Dawids prequential r napproach.
A simple approach for finding the globally optimal Bayesian network structure
Jun 27, 2012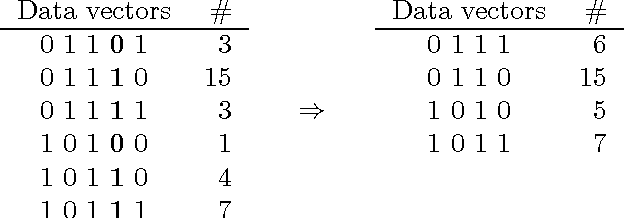
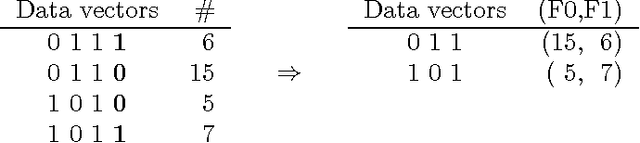
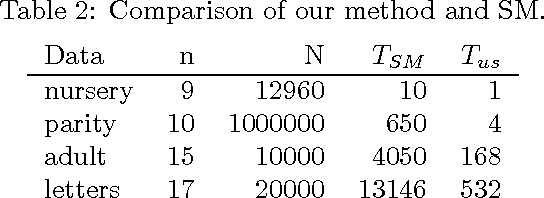
We study the problem of learning the best Bayesian network structure with respect to a decomposable score such as BDe, BIC or AIC. This problem is known to be NP-hard, which means that solving it becomes quickly infeasible as the number of variables increases. Nevertheless, in this paper we show that it is possible to learn the best Bayesian network structure with over 30 variables, which covers many practically interesting cases. Our algorithm is less complicated and more efficient than the techniques presented earlier. It can be easily parallelized, and offers a possibility for efficient exploration of the best networks consistent with different variable orderings. In the experimental part of the paper we compare the performance of the algorithm to the previous state-of-the-art algorithm. Free source-code and an online-demo can be found at http://b-course.hiit.fi/bene.
On Sensitivity of the MAP Bayesian Network Structure to the Equivalent Sample Size Parameter
Jun 20, 2012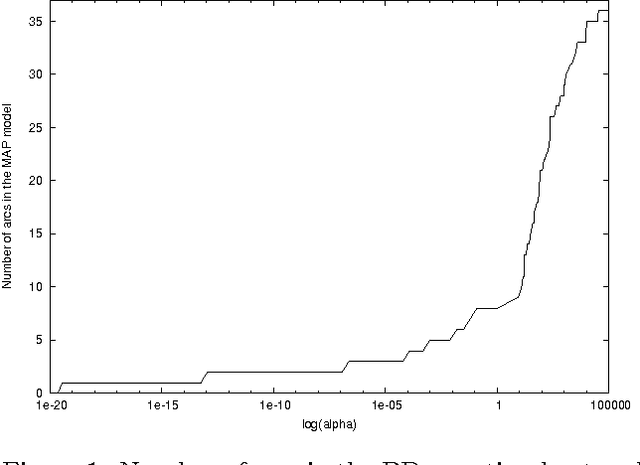
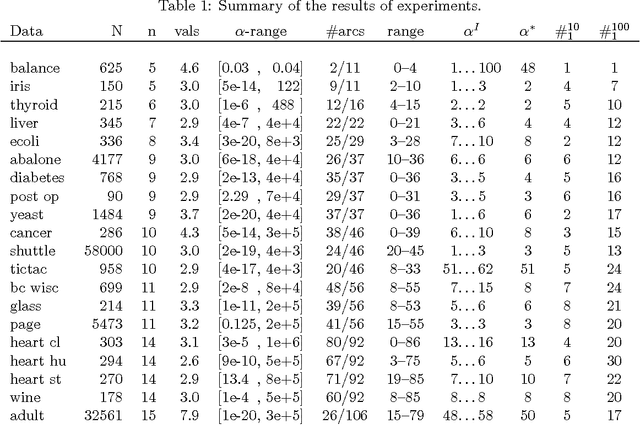
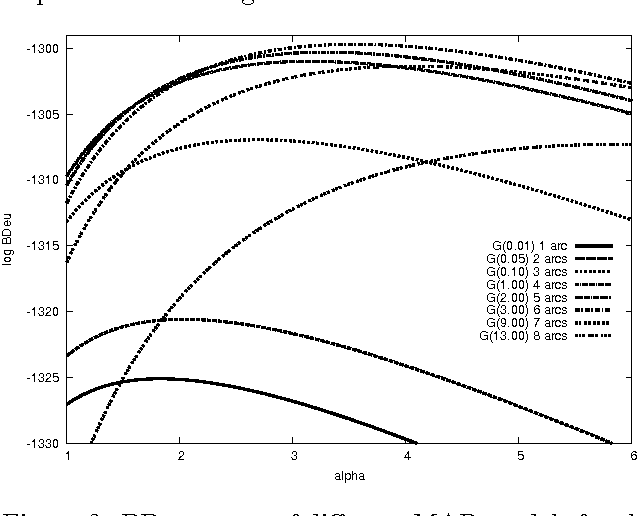
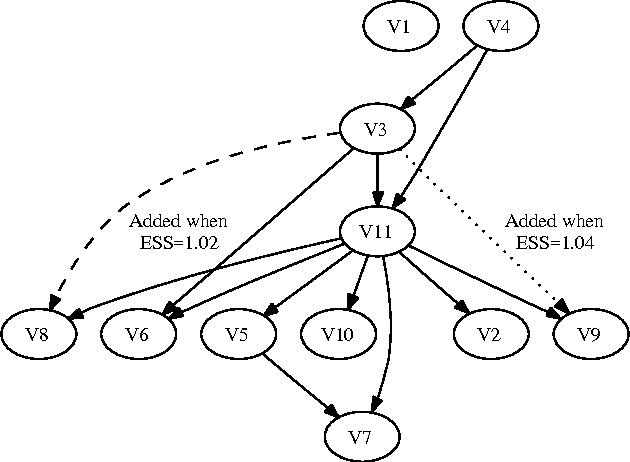
BDeu marginal likelihood score is a popular model selection criterion for selecting a Bayesian network structure based on sample data. This non-informative scoring criterion assigns same score for network structures that encode same independence statements. However, before applying the BDeu score, one must determine a single parameter, the equivalent sample size alpha. Unfortunately no generally accepted rule for determining the alpha parameter has been suggested. This is disturbing, since in this paper we show through a series of concrete experiments that the solution of the network structure optimization problem is highly sensitive to the chosen alpha parameter value. Based on these results, we are able to give explanations for how and why this phenomenon happens, and discuss ideas for solving this problem.