 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuotient Normalized Maximum Likelihood Criterion for Learning Bayesian Network Structures
Aug 27, 2024We introduce an information theoretic criterion for Bayesian network structure learning which we call quotient normalized maximum likelihood (qNML). In contrast to the closely related factorized normalized maximum likelihood criterion, qNML satisfies the property of score equivalence. It is also decomposable and completely free of adjustable hyperparameters. For practical computations, we identify a remarkably accurate approximation proposed earlier by Szpankowski and Weinberger. Experiments on both simulated and real data demonstrate that the new criterion leads to parsimonious models with good predictive accuracy.
* Accepted to AISTATS 2018
Learning non-parametric Markov networks with mutual information
Aug 08, 2017
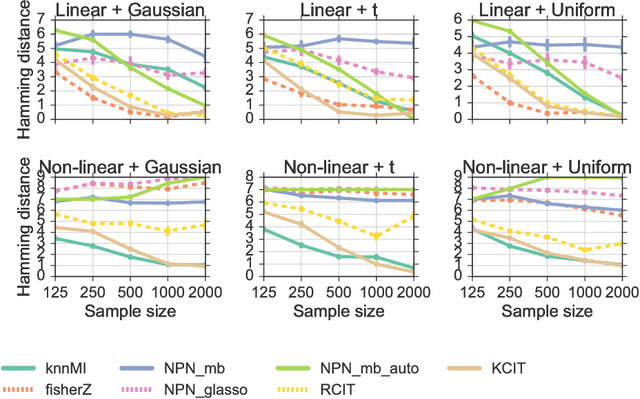
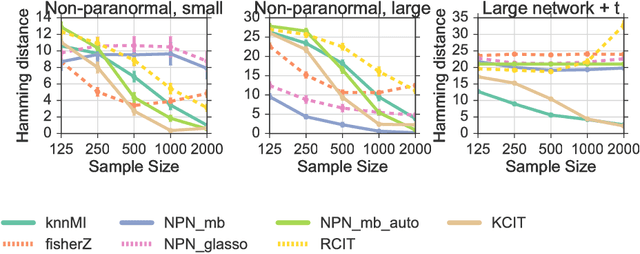
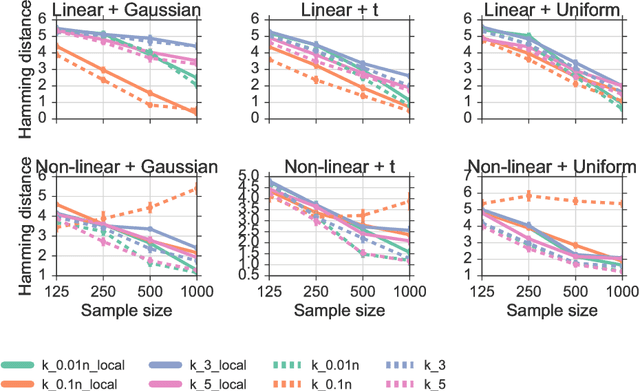
We propose a method for learning Markov network structures for continuous data without invoking any assumptions about the distribution of the variables. The method makes use of previous work on a non-parametric estimator for mutual information which is used to create a non-parametric test for multivariate conditional independence. This independence test is then combined with an efficient constraint-based algorithm for learning the graph structure. The performance of the method is evaluated on several synthetic data sets and it is shown to learn considerably more accurate structures than competing methods when the dependencies between the variables involve non-linearities.
On the inconsistency of $\ell_1$-penalised sparse precision matrix estimation
Mar 08, 2016
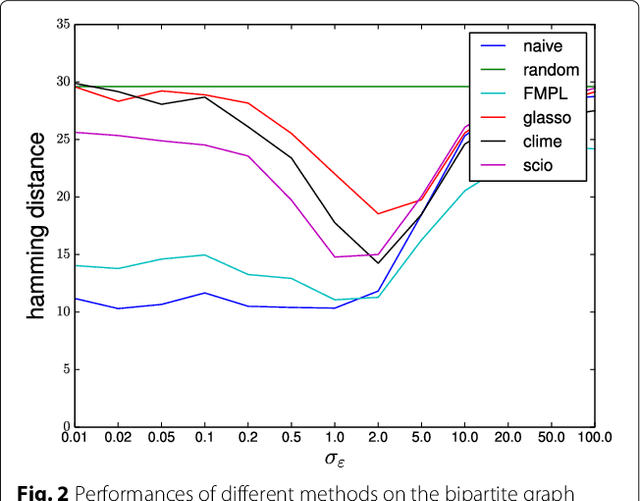

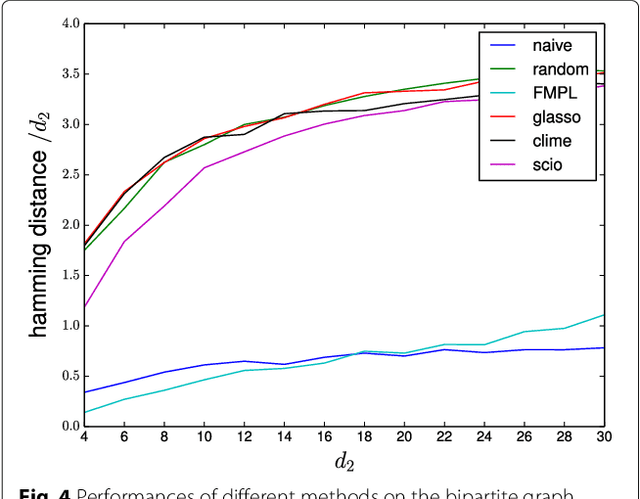
Various $\ell_1$-penalised estimation methods such as graphical lasso and CLIME are widely used for sparse precision matrix estimation. Many of these methods have been shown to be consistent under various quantitative assumptions about the underlying true covariance matrix. Intuitively, these conditions are related to situations where the penalty term will dominate the optimisation. In this paper, we explore the consistency of $\ell_1$-based methods for a class of sparse latent variable -like models, which are strongly motivated by several types of applications. We show that all $\ell_1$-based methods fail dramatically for models with nearly linear dependencies between the variables. We also study the consistency on models derived from real gene expression data and note that the assumptions needed for consistency never hold even for modest sized gene networks and $\ell_1$-based methods also become unreliable in practice for larger networks.
Learning Gaussian Graphical Models With Fractional Marginal Pseudo-likelihood
Feb 25, 2016
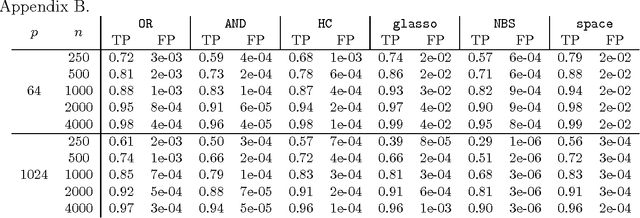


We propose a Bayesian approximate inference method for learning the dependence structure of a Gaussian graphical model. Using pseudo-likelihood, we derive an analytical expression to approximate the marginal likelihood for an arbitrary graph structure without invoking any assumptions about decomposability. The majority of the existing methods for learning Gaussian graphical models are either restricted to decomposable graphs or require specification of a tuning parameter that may have a substantial impact on learned structures. By combining a simple sparsity inducing prior for the graph structures with a default reference prior for the model parameters, we obtain a fast and easily applicable scoring function that works well for even high-dimensional data. We demonstrate the favourable performance of our approach by large-scale comparisons against the leading methods for learning non-decomposable Gaussian graphical models. A theoretical justification for our method is provided by showing that it yields a consistent estimator of the graph structure.