 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the inconsistency of $\ell_1$-penalised sparse precision matrix estimation
Paper and Code
Mar 08, 2016
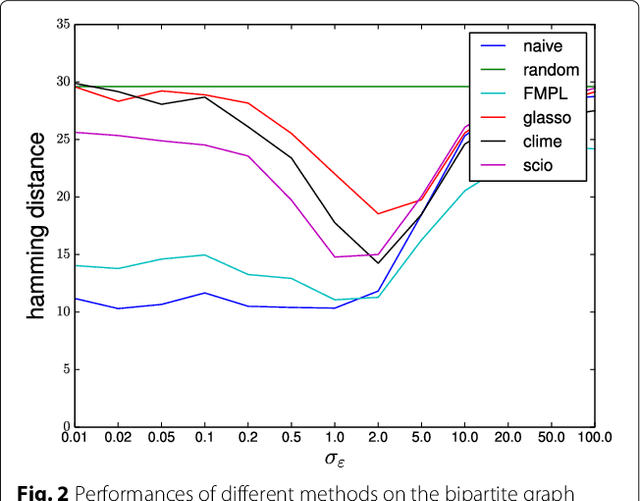

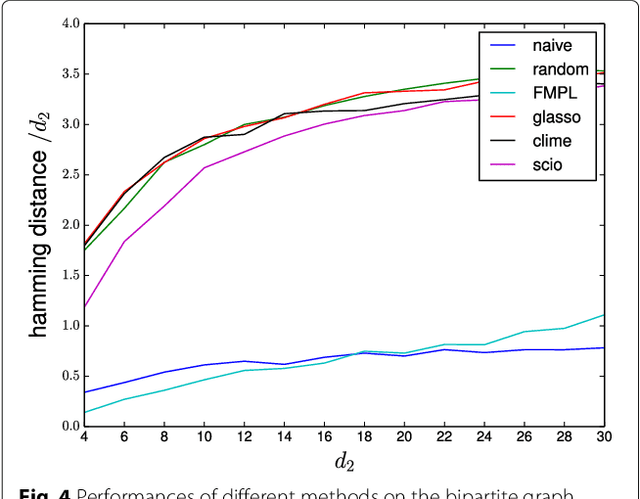
Various $\ell_1$-penalised estimation methods such as graphical lasso and CLIME are widely used for sparse precision matrix estimation. Many of these methods have been shown to be consistent under various quantitative assumptions about the underlying true covariance matrix. Intuitively, these conditions are related to situations where the penalty term will dominate the optimisation. In this paper, we explore the consistency of $\ell_1$-based methods for a class of sparse latent variable -like models, which are strongly motivated by several types of applications. We show that all $\ell_1$-based methods fail dramatically for models with nearly linear dependencies between the variables. We also study the consistency on models derived from real gene expression data and note that the assumptions needed for consistency never hold even for modest sized gene networks and $\ell_1$-based methods also become unreliable in practice for larger networks.