 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Definition of Open-Ended Learning Problems for Goal-Conditioned Agents
Nov 02, 2023A lot of recent machine learning research papers have "Open-ended learning" in their title. But very few of them attempt to define what they mean when using the term. Even worse, when looking more closely there seems to be no consensus on what distinguishes open-ended learning from related concepts such as continual learning, lifelong learning or autotelic learning. In this paper, we contribute to fixing this situation. After illustrating the genealogy of the concept and more recent perspectives about what it truly means, we outline that open-ended learning is generally conceived as a composite notion encompassing a set of diverse properties. In contrast with these previous approaches, we propose to isolate a key elementary property of open-ended processes, which is to always produce novel elements from time to time over an infinite horizon. From there, we build the notion of open-ended learning problems and focus in particular on the subset of open-ended goal-conditioned reinforcement learning problems, as this framework facilitates the definition of learning a growing repertoire of skills. Finally, we highlight the work that remains to be performed to fill the gap between our elementary definition and the more involved notions of open-ended learning that developmental AI researchers may have in mind.
DREAM Architecture: a Developmental Approach to Open-Ended Learning in Robotics
May 13, 2020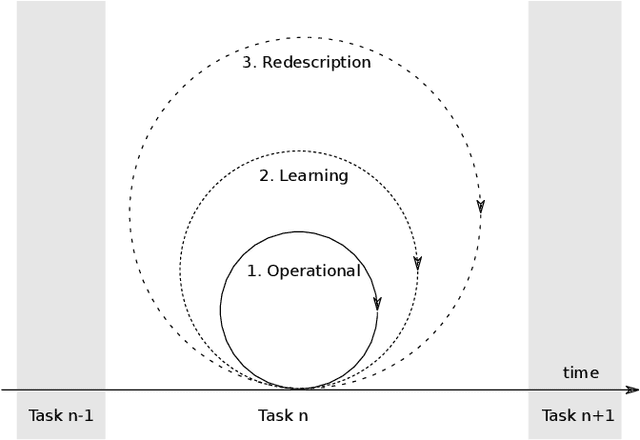
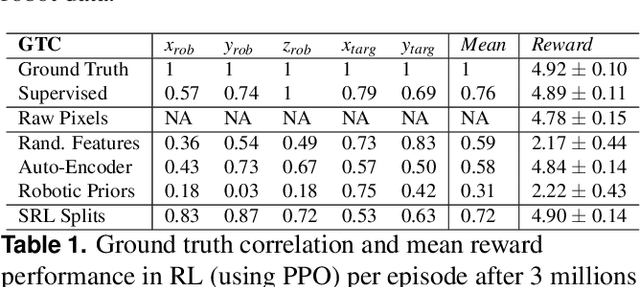
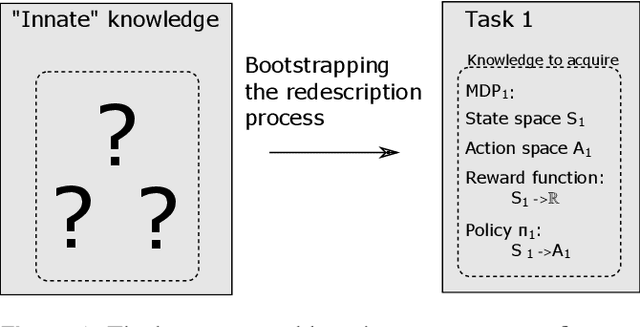
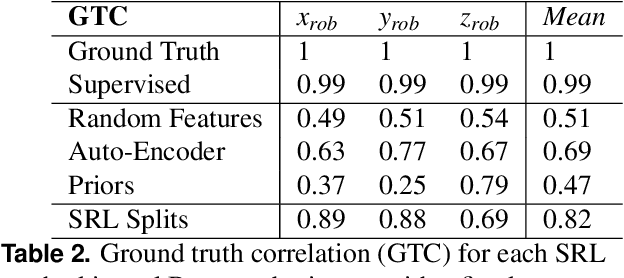
Robots are still limited to controlled conditions, that the robot designer knows with enough details to endow the robot with the appropriate models or behaviors. Learning algorithms add some flexibility with the ability to discover the appropriate behavior given either some demonstrations or a reward to guide its exploration with a reinforcement learning algorithm. Reinforcement learning algorithms rely on the definition of state and action spaces that define reachable behaviors. Their adaptation capability critically depends on the representations of these spaces: small and discrete spaces result in fast learning while large and continuous spaces are challenging and either require a long training period or prevent the robot from converging to an appropriate behavior. Beside the operational cycle of policy execution and the learning cycle, which works at a slower time scale to acquire new policies, we introduce the redescription cycle, a third cycle working at an even slower time scale to generate or adapt the required representations to the robot, its environment and the task. We introduce the challenges raised by this cycle and we present DREAM (Deferred Restructuring of Experience in Autonomous Machines), a developmental cognitive architecture to bootstrap this redescription process stage by stage, build new state representations with appropriate motivations, and transfer the acquired knowledge across domains or tasks or even across robots. We describe results obtained so far with this approach and end up with a discussion of the questions it raises in Neuroscience.