 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous state-space segmentation for Deep-RL sparse reward scenarios
Apr 04, 2025Dealing with environments with sparse rewards has always been crucial for systems developed to operate in autonomous open-ended learning settings. Intrinsic Motivations could be an effective way to help Deep Reinforcement Learning algorithms learn in such scenarios. In fact, intrinsic reward signals, such as novelty or curiosity, are generally adopted to improve exploration when extrinsic rewards are delayed or absent. Building on previous works, we tackle the problem of learning policies in the presence of sparse rewards by proposing a two-level architecture that alternates an ''intrinsically driven'' phase of exploration and autonomous sub-goal generation, to a phase of sparse reward, goal-directed policy learning. The idea is to build several small networks, each one specialized on a particular sub-path, and use them as starting points for future exploration without the need to further explore from scratch previously learnt paths. Two versions of the system have been trained and tested in the Gym SuperMarioBros environment without considering any additional extrinsic reward. The results show the validity of our approach and the importance of autonomously segment the environment to generate an efficient path towards the final goal.
Synthesizing Evolving Symbolic Representations for Autonomous Systems
Sep 18, 2024Recently, AI systems have made remarkable progress in various tasks. Deep Reinforcement Learning(DRL) is an effective tool for agents to learn policies in low-level state spaces to solve highly complex tasks. Researchers have introduced Intrinsic Motivation(IM) to the RL mechanism, which simulates the agent's curiosity, encouraging agents to explore interesting areas of the environment. This new feature has proved vital in enabling agents to learn policies without being given specific goals. However, even though DRL intelligence emerges through a sub-symbolic model, there is still a need for a sort of abstraction to understand the knowledge collected by the agent. To this end, the classical planning formalism has been used in recent research to explicitly represent the knowledge an autonomous agent acquires and effectively reach extrinsic goals. Despite classical planning usually presents limited expressive capabilities, PPDDL demonstrated usefulness in reviewing the knowledge gathered by an autonomous system, making explicit causal correlations, and can be exploited to find a plan to reach any state the agent faces during its experience. This work presents a new architecture implementing an open-ended learning system able to synthesize from scratch its experience into a PPDDL representation and update it over time. Without a predefined set of goals and tasks, the system integrates intrinsic motivations to explore the environment in a self-directed way, exploiting the high-level knowledge acquired during its experience. The system explores the environment and iteratively: (a) discover options, (b) explore the environment using options, (c) abstract the knowledge collected and (d) plan. This paper proposes an alternative approach to implementing open-ended learning architectures exploiting low-level and high-level representations to extend its knowledge in a virtuous loop.
Purpose for Open-Ended Learning Robots: A Computational Taxonomy, Definition, and Operationalisation
Mar 04, 2024Autonomous open-ended learning (OEL) robots are able to cumulatively acquire new skills and knowledge through direct interaction with the environment, for example relying on the guidance of intrinsic motivations and self-generated goals. OEL robots have a high relevance for applications as they can use the autonomously acquired knowledge to accomplish tasks relevant for their human users. OEL robots, however, encounter an important limitation: this may lead to the acquisition of knowledge that is not so much relevant to accomplish the users' tasks. This work analyses a possible solution to this problem that pivots on the novel concept of `purpose'. Purposes indicate what the designers and/or users want from the robot. The robot should use internal representations of purposes, called here `desires', to focus its open-ended exploration towards the acquisition of knowledge relevant to accomplish them. This work contributes to develop a computational framework on purpose in two ways. First, it formalises a framework on purpose based on a three-level motivational hierarchy involving: (a) the purposes; (b) the desires, which are domain independent; (c) specific domain dependent state-goals. Second, the work highlights key challenges highlighted by the framework such as: the `purpose-desire alignment problem', the `purpose-goal grounding problem', and the `arbitration between desires'. Overall, the approach enables OEL robots to learn in an autonomous way but also to focus on acquiring goals and skills that meet the purposes of the designers and users.
A Definition of Open-Ended Learning Problems for Goal-Conditioned Agents
Nov 02, 2023A lot of recent machine learning research papers have "Open-ended learning" in their title. But very few of them attempt to define what they mean when using the term. Even worse, when looking more closely there seems to be no consensus on what distinguishes open-ended learning from related concepts such as continual learning, lifelong learning or autotelic learning. In this paper, we contribute to fixing this situation. After illustrating the genealogy of the concept and more recent perspectives about what it truly means, we outline that open-ended learning is generally conceived as a composite notion encompassing a set of diverse properties. In contrast with these previous approaches, we propose to isolate a key elementary property of open-ended processes, which is to always produce novel elements from time to time over an infinite horizon. From there, we build the notion of open-ended learning problems and focus in particular on the subset of open-ended goal-conditioned reinforcement learning problems, as this framework facilitates the definition of learning a growing repertoire of skills. Finally, we highlight the work that remains to be performed to fill the gap between our elementary definition and the more involved notions of open-ended learning that developmental AI researchers may have in mind.
Option Discovery for Autonomous Generation of Symbolic Knowledge
Jun 03, 2022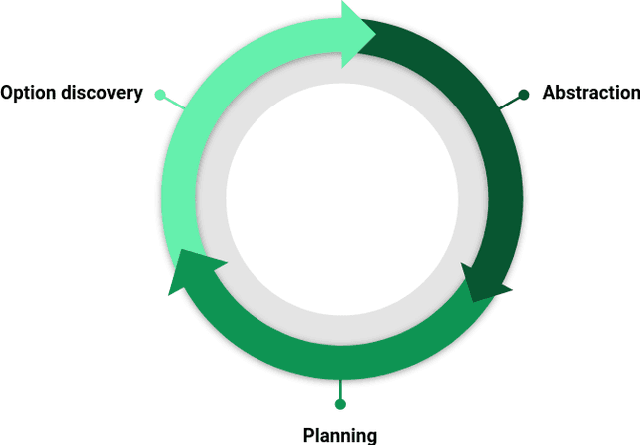
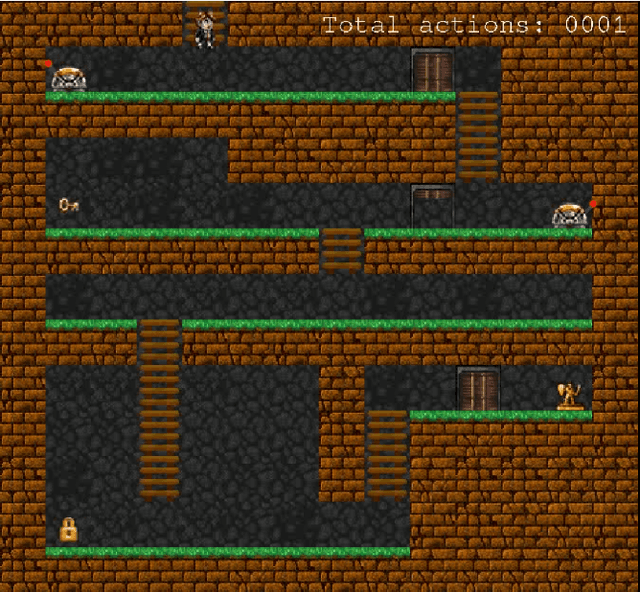


In this work we present an empirical study where we demonstrate the possibility of developing an artificial agent that is capable to autonomously explore an experimental scenario. During the exploration, the agent is able to discover and learn interesting options allowing to interact with the environment without any pre-assigned goal, then abstract and re-use the acquired knowledge to solve possible tasks assigned ex-post. We test the system in the so-called Treasure Game domain described in the recent literature and we empirically demonstrate that the discovered options can be abstracted in an probabilistic symbolic planning model (using the PPDDL language), which allowed the agent to generate symbolic plans to achieve extrinsic goals.
Autonomous Open-Ended Learning of Tasks with Non-Stationary Interdependencies
May 16, 2022
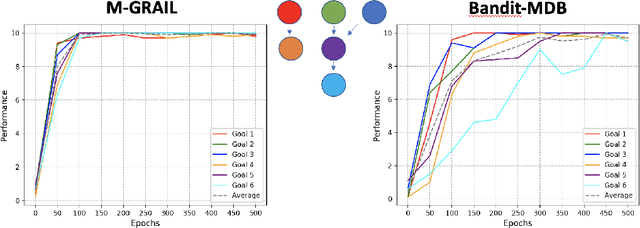
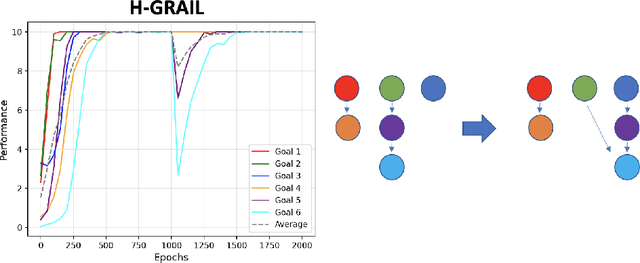
Autonomous open-ended learning is a relevant approach in machine learning and robotics, allowing the design of artificial agents able to acquire goals and motor skills without the necessity of user assigned tasks. A crucial issue for this approach is to develop strategies to ensure that agents can maximise their competence on as many tasks as possible in the shortest possible time. Intrinsic motivations have proven to generate a task-agnostic signal to properly allocate the training time amongst goals. While the majority of works in the field of intrinsically motivated open-ended learning focus on scenarios where goals are independent from each other, only few of them studied the autonomous acquisition of interdependent tasks, and even fewer tackled scenarios where goals involve non-stationary interdependencies. Building on previous works, we tackle these crucial issues at the level of decision making (i.e., building strategies to properly select between goals), and we propose a hierarchical architecture that treating sub-tasks selection as a Markov Decision Process is able to properly learn interdependent skills on the basis of intrinsically generated motivations. In particular, we first deepen the analysis of a previous system, showing the importance of incorporating information about the relationships between tasks at a higher level of the architecture (that of goal selection). Then we introduce H-GRAIL, a new system that extends the previous one by adding a new learning layer to store the autonomously acquired sequences of tasks to be able to modify them in case the interdependencies are non-stationary. All systems are tested in a real robotic scenario, with a Baxter robot performing multiple interdependent reaching tasks.
Autonomous learning of multiple, context-dependent tasks
Nov 27, 2020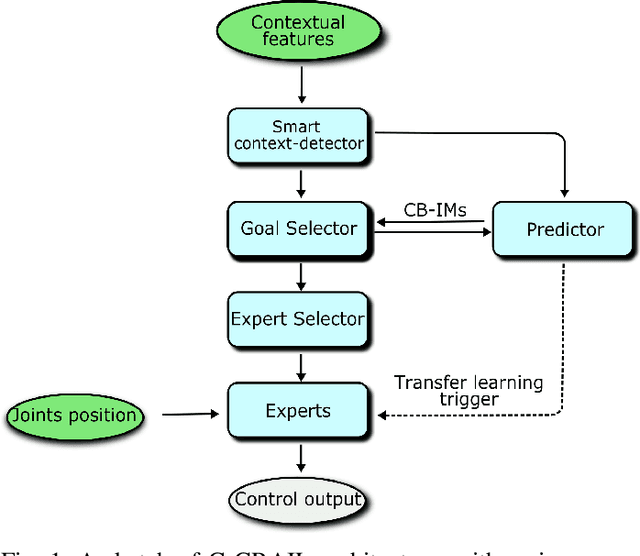
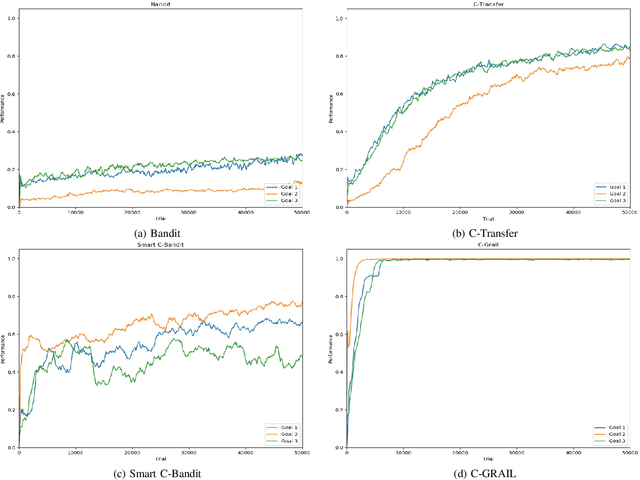
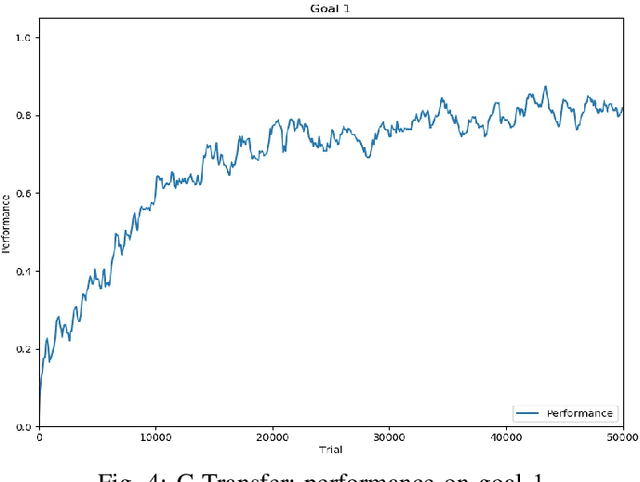
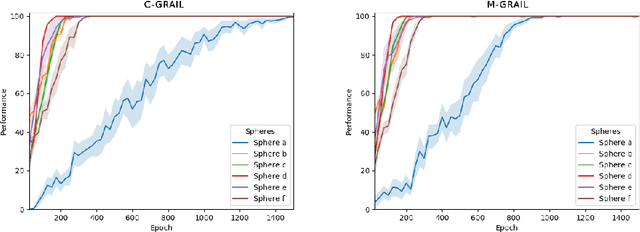
When facing the problem of autonomously learning multiple tasks with reinforcement learning systems, researchers typically focus on solutions where just one parametrised policy per task is sufficient to solve them. However, in complex environments presenting different contexts, the same task might need a set of different skills to be solved. These situations pose two challenges: (a) to recognise the different contexts that need different policies; (b) quickly learn the policies to accomplish the same tasks in the new discovered contexts. These two challenges are even harder if faced within an open-ended learning framework where an agent has to autonomously discover the goals that it might accomplish in a given environment, and also to learn the motor skills to accomplish them. We propose a novel open-ended learning robot architecture, C-GRAIL, that solves the two challenges in an integrated fashion. In particular, the architecture is able to detect new relevant contests, and ignore irrelevant ones, on the basis of the decrease of the expected performance for a given goal. Moreover, the architecture can quickly learn the policies for the new contexts by exploiting transfer learning importing knowledge from already acquired policies. The architecture is tested in a simulated robotic environment involving a robot that autonomously learns to reach relevant target objects in the presence of multiple obstacles generating several different obstacles. The proposed architecture outperforms other models not using the proposed autonomous context-discovery and transfer-learning mechanisms.
Learning High-Level Planning Symbols from Intrinsically Motivated Experience
Jul 18, 2019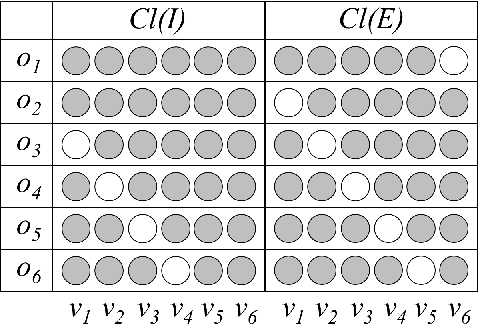
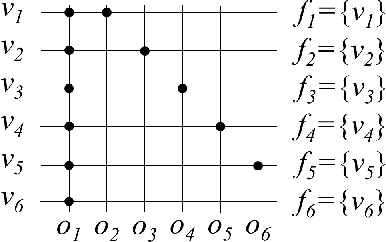
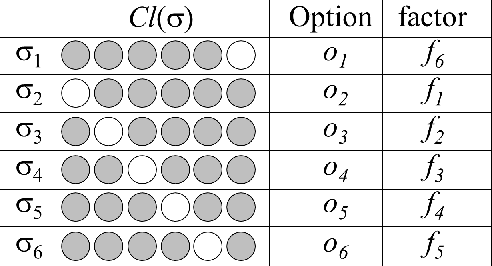
In symbolic planning systems, the knowledge on the domain is commonly provided by an expert. Recently, an automatic abstraction procedure has been proposed in the literature to create a Planning Domain Definition Language (PDDL) representation, which is the most widely used input format for most off-the-shelf automated planners, starting from `options', a data structure used to represent actions within the hierarchical reinforcement learning framework. We propose an architecture that potentially removes the need for human intervention. In particular, the architecture first acquires options in a fully autonomous fashion on the basis of open-ended learning, then builds a PDDL domain based on symbols and operators that can be used to accomplish user-defined goals through a standard PDDL planner. We start from an implementation of the above mentioned procedure tested on a set of benchmark domains in which a humanoid robot can change the state of some objects through direct interaction with the environment. We then investigate some critical aspects of the information abstraction process that have been observed, and propose an extension that mitigates such criticalities, in particular by analysing the type of classifiers that allow a suitable grounding of symbols.
Autonomous Reinforcement Learning of Multiple Interrelated Tasks
Jun 04, 2019
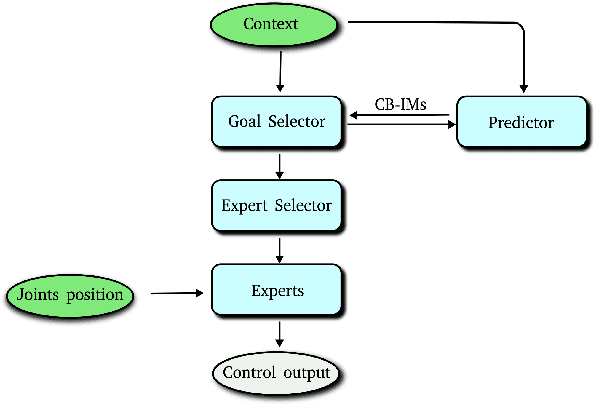
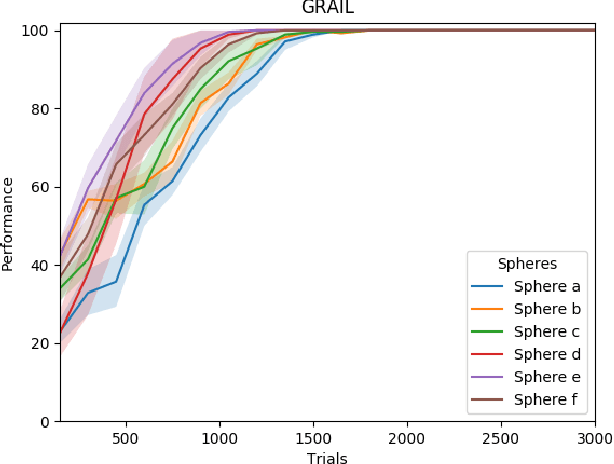
Autonomous multiple tasks learning is a fundamental capability to develop versatile artificial agents that can act in complex environments. In real-world scenarios, tasks may be interrelated (or "hierarchical") so that a robot has to first learn to achieve some of them to set the preconditions for learning other ones. Even though different strategies have been used in robotics to tackle the acquisition of interrelated tasks, in particular within the developmental robotics framework, autonomous learning in this kind of scenarios is still an open question. Building on previous research in the framework of intrinsically motivated open-ended learning, in this work we describe how this question can be addressed working on the level of task selection, in particular considering the multiple interrelated tasks scenario as an MDP where the system is trying to maximise its competence over all the tasks.
Autonomous Open-Ended Learning of Interdependent Tasks
May 07, 2019
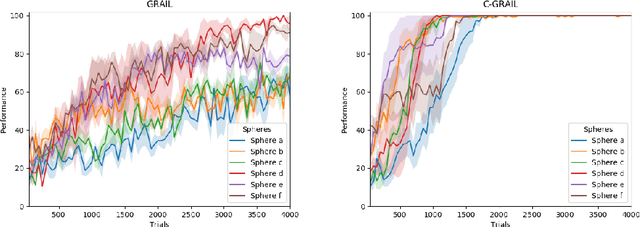
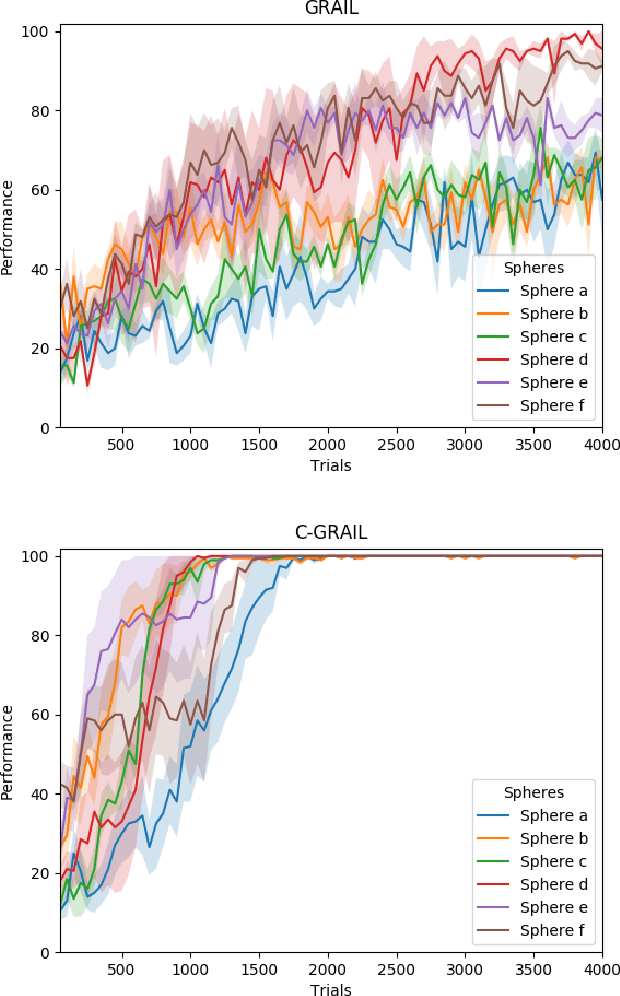
Autonomy is fundamental for artificial agents acting in complex real-world scenarios. The acquisition of many different skills is pivotal to foster versatile autonomous behaviour and thus a main objective for robotics and machine learning. Intrinsic motivations have proven to properly generate a task-agnostic signal to drive the autonomous acquisition of multiple policies in settings requiring the learning of multiple tasks. However, in real world scenarios tasks may be interdependent so that some of them may constitute the precondition for learning other ones. Despite different strategies have been used to tackle the acquisition of interdependent/hierarchical tasks, fully autonomous open-ended learning in these scenarios is still an open question. Building on previous research within the framework of intrinsically-motivated open-ended learning, we propose an architecture for robot control that tackles this problem from the point of view of decision making, i.e. treating the selection of tasks as a Markov Decision Process where the system selects the policies to be trained in order to maximise its competence over all the tasks. The system is then tested with a humanoid robot solving interdependent multiple reaching tasks.