 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Evolving Symbolic Representations for Autonomous Systems
Sep 18, 2024Recently, AI systems have made remarkable progress in various tasks. Deep Reinforcement Learning(DRL) is an effective tool for agents to learn policies in low-level state spaces to solve highly complex tasks. Researchers have introduced Intrinsic Motivation(IM) to the RL mechanism, which simulates the agent's curiosity, encouraging agents to explore interesting areas of the environment. This new feature has proved vital in enabling agents to learn policies without being given specific goals. However, even though DRL intelligence emerges through a sub-symbolic model, there is still a need for a sort of abstraction to understand the knowledge collected by the agent. To this end, the classical planning formalism has been used in recent research to explicitly represent the knowledge an autonomous agent acquires and effectively reach extrinsic goals. Despite classical planning usually presents limited expressive capabilities, PPDDL demonstrated usefulness in reviewing the knowledge gathered by an autonomous system, making explicit causal correlations, and can be exploited to find a plan to reach any state the agent faces during its experience. This work presents a new architecture implementing an open-ended learning system able to synthesize from scratch its experience into a PPDDL representation and update it over time. Without a predefined set of goals and tasks, the system integrates intrinsic motivations to explore the environment in a self-directed way, exploiting the high-level knowledge acquired during its experience. The system explores the environment and iteratively: (a) discover options, (b) explore the environment using options, (c) abstract the knowledge collected and (d) plan. This paper proposes an alternative approach to implementing open-ended learning architectures exploiting low-level and high-level representations to extend its knowledge in a virtuous loop.
Option Discovery for Autonomous Generation of Symbolic Knowledge
Jun 03, 2022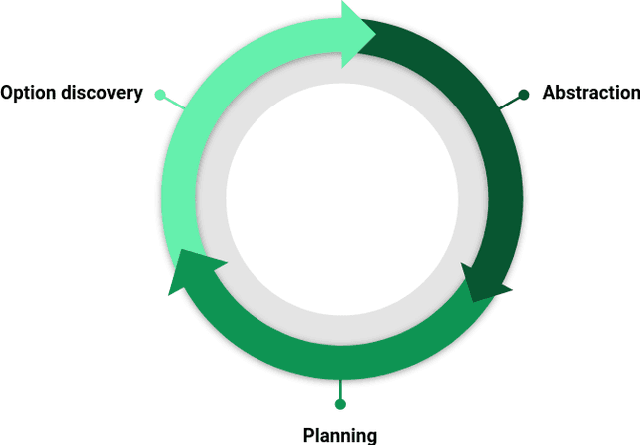
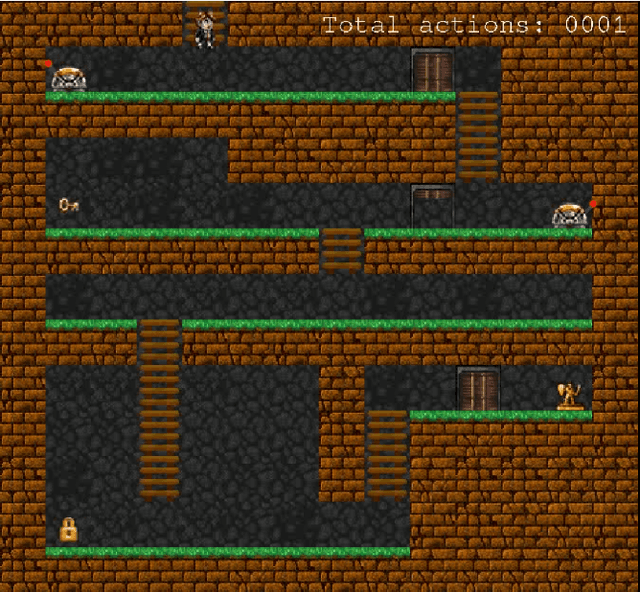


In this work we present an empirical study where we demonstrate the possibility of developing an artificial agent that is capable to autonomously explore an experimental scenario. During the exploration, the agent is able to discover and learn interesting options allowing to interact with the environment without any pre-assigned goal, then abstract and re-use the acquired knowledge to solve possible tasks assigned ex-post. We test the system in the so-called Treasure Game domain described in the recent literature and we empirically demonstrate that the discovered options can be abstracted in an probabilistic symbolic planning model (using the PPDDL language), which allowed the agent to generate symbolic plans to achieve extrinsic goals.
Learning High-Level Planning Symbols from Intrinsically Motivated Experience
Jul 18, 2019
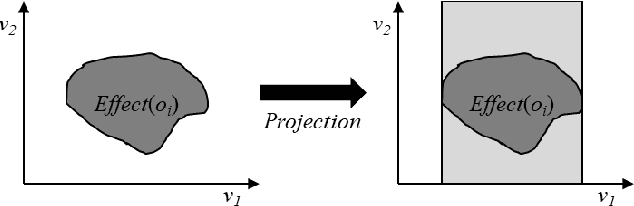
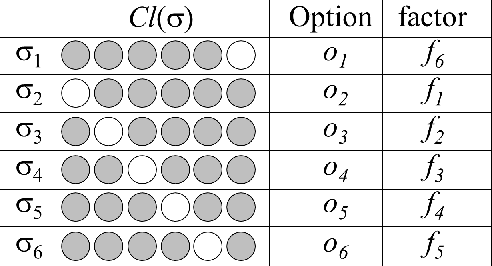
In symbolic planning systems, the knowledge on the domain is commonly provided by an expert. Recently, an automatic abstraction procedure has been proposed in the literature to create a Planning Domain Definition Language (PDDL) representation, which is the most widely used input format for most off-the-shelf automated planners, starting from `options', a data structure used to represent actions within the hierarchical reinforcement learning framework. We propose an architecture that potentially removes the need for human intervention. In particular, the architecture first acquires options in a fully autonomous fashion on the basis of open-ended learning, then builds a PDDL domain based on symbols and operators that can be used to accomplish user-defined goals through a standard PDDL planner. We start from an implementation of the above mentioned procedure tested on a set of benchmark domains in which a humanoid robot can change the state of some objects through direct interaction with the environment. We then investigate some critical aspects of the information abstraction process that have been observed, and propose an extension that mitigates such criticalities, in particular by analysing the type of classifiers that allow a suitable grounding of symbols.