 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusing Robot Open-Ended Reinforcement Learning Through Users' Purposes
Mar 16, 2025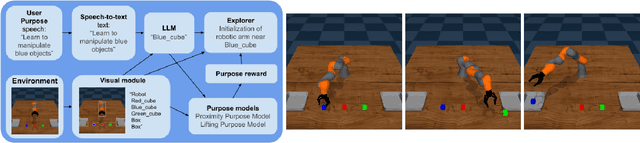
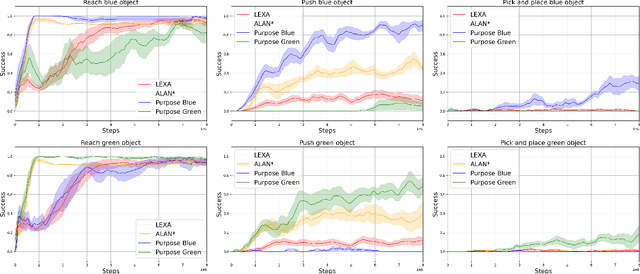
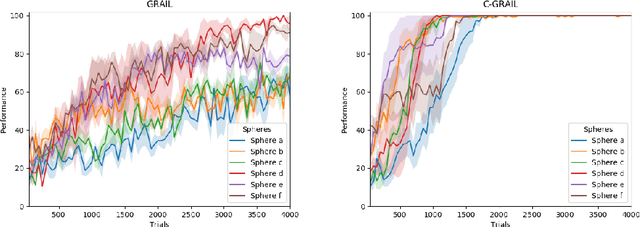
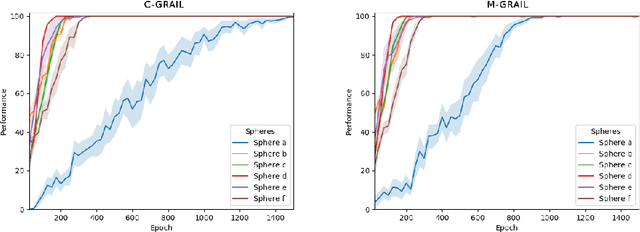
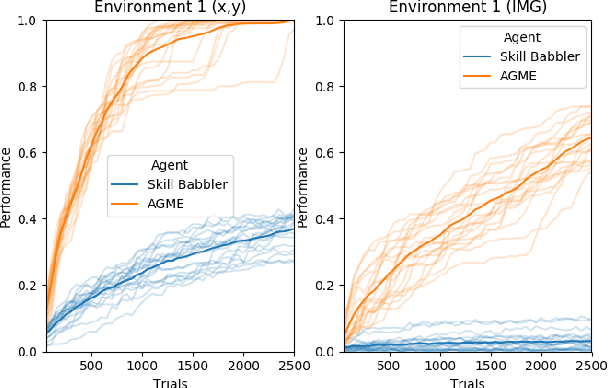
Open-Ended Learning (OEL) autonomous robots can acquire new skills and knowledge through direct interaction with their environment, relying on mechanisms such as intrinsic motivations and self-generated goals to guide learning processes. OEL robots are highly relevant for applications as they can autonomously leverage acquired knowledge to perform tasks beneficial to human users in unstructured environments, addressing challenges unforeseen at design time. However, OEL robots face a significant limitation: their openness may lead them to waste time learning information that is irrelevant to tasks desired by specific users. Here, we propose a solution called `Purpose-Directed Open-Ended Learning' (POEL), based on the novel concept of `purpose' introduced in previous work. A purpose specifies what users want the robot to achieve. The key insight of this work is that purpose can focus OEL on learning self-generated classes of tasks that, while unknown during autonomous learning (as typical in OEL), involve objects relevant to the purpose. This concept is operationalised in a novel robot architecture capable of receiving a human purpose through speech-to-text, analysing the scene to identify objects, and using a Large Language Model to reason about which objects are purpose-relevant. These objects are then used to bias OEL exploration towards their spatial proximity and to self-generate rewards that favour interactions with them. The solution is tested in a simulated scenario where a camera-arm-gripper robot interacts freely with purpose-related and distractor objects. For the first time, the results demonstrate the potential advantages of purpose-focused OEL over state-of-the-art OEL methods, enabling robots to handle unstructured environments while steering their learning toward knowledge acquisition relevant to users.
Purpose for Open-Ended Learning Robots: A Computational Taxonomy, Definition, and Operationalisation
Mar 04, 2024Autonomous open-ended learning (OEL) robots are able to cumulatively acquire new skills and knowledge through direct interaction with the environment, for example relying on the guidance of intrinsic motivations and self-generated goals. OEL robots have a high relevance for applications as they can use the autonomously acquired knowledge to accomplish tasks relevant for their human users. OEL robots, however, encounter an important limitation: this may lead to the acquisition of knowledge that is not so much relevant to accomplish the users' tasks. This work analyses a possible solution to this problem that pivots on the novel concept of `purpose'. Purposes indicate what the designers and/or users want from the robot. The robot should use internal representations of purposes, called here `desires', to focus its open-ended exploration towards the acquisition of knowledge relevant to accomplish them. This work contributes to develop a computational framework on purpose in two ways. First, it formalises a framework on purpose based on a three-level motivational hierarchy involving: (a) the purposes; (b) the desires, which are domain independent; (c) specific domain dependent state-goals. Second, the work highlights key challenges highlighted by the framework such as: the `purpose-desire alignment problem', the `purpose-goal grounding problem', and the `arbitration between desires'. Overall, the approach enables OEL robots to learn in an autonomous way but also to focus on acquiring goals and skills that meet the purposes of the designers and users.
A method for the ethical analysis of brain-inspired AI
May 18, 2023Despite its successes, to date Artificial Intelligence (AI) is still characterized by a number of shortcomings with regards to different application domains and goals. These limitations are arguably both conceptual (e.g., related to underlying theoretical models, such as symbolic vs. connectionist), and operational (e.g., related to robustness and ability to generalize). Biologically inspired AI, and more specifically brain-inspired AI, promises to provide further biological aspects beyond those that are already traditionally included in AI, making it possible to assess and possibly overcome some of its present shortcomings. This article examines some conceptual, technical, and ethical issues raised by the development and use of brain-inspired AI. Against this background, the paper asks whether there is anything ethically unique about brain-inspired AI. The aim of the paper is to introduce a method that has a heuristic nature and that can be applied to identify and address the ethical issues arising from brain-inspired AI. The conclusion resulting from the application of this method is that, compared to traditional AI, brain-inspired AI raises new foundational ethical issues and some new practical ethical issues, and exacerbates some of the issues raised by traditional AI.
A Computational Model of Representation Learning in the Brain Cortex, Integrating Unsupervised and Reinforcement Learning
Jun 07, 2021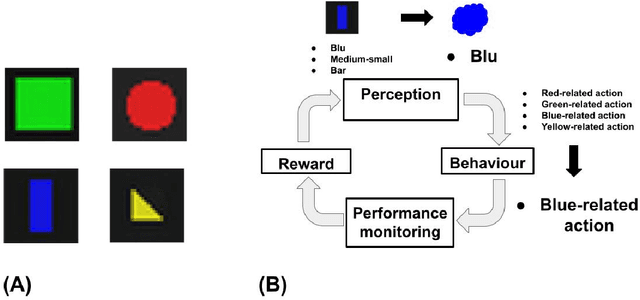
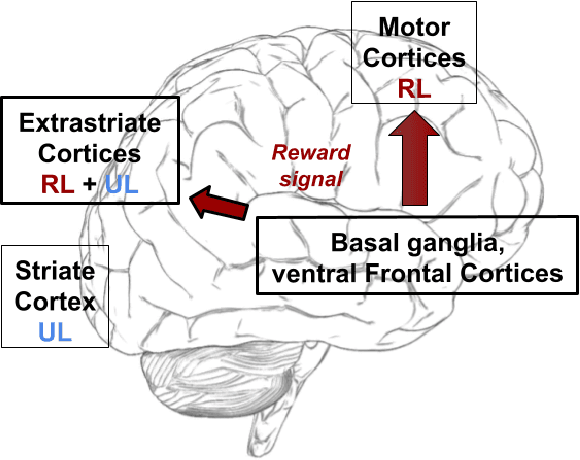
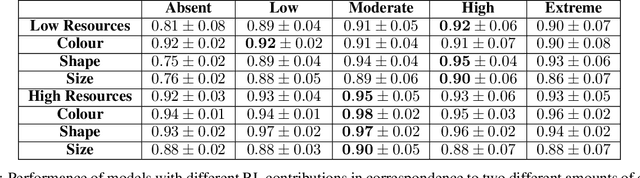
A common view on the brain learning processes proposes that the three classic learning paradigms -- unsupervised, reinforcement, and supervised -- take place in respectively the cortex, the basal-ganglia, and the cerebellum. However, dopamine outbursts, usually assumed to encode reward, are not limited to the basal ganglia but also reach prefrontal, motor, and higher sensory cortices. We propose that in the cortex the same reward-based trial-and-error processes might support not only the acquisition of motor representations but also of sensory representations. In particular, reward signals might guide trial-and-error processes that mix with associative learning processes to support the acquisition of representations better serving downstream action selection. We tested the soundness of this hypothesis with a computational model that integrates unsupervised learning (Contrastive Divergence) and reinforcement learning (REINFORCE). The model was tested with a task requiring different responses to different visual images grouped in categories involving either colour, shape, or size. Results show that a balanced mix of unsupervised and reinforcement learning processes leads to the best performance. Indeed, excessive unsupervised learning tends to under-represent task-relevant features while excessive reinforcement learning tends to initially learn slowly and then to incur in local minima. These results stimulate future empirical studies on category learning directed to investigate similar effects in the extrastriate visual cortices. Moreover, they prompt further computational investigations directed to study the possible advantages of integrating unsupervised and reinforcement learning processes.
An open-ended learning architecture to face the REAL 2020 simulated robot competition
Nov 27, 2020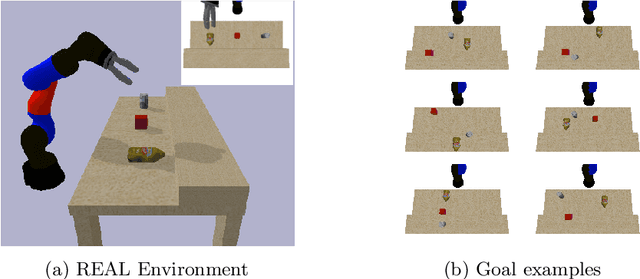
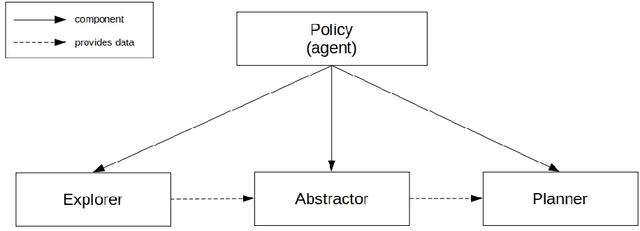

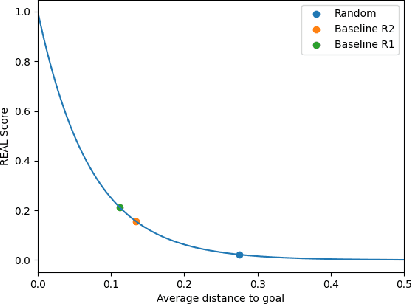
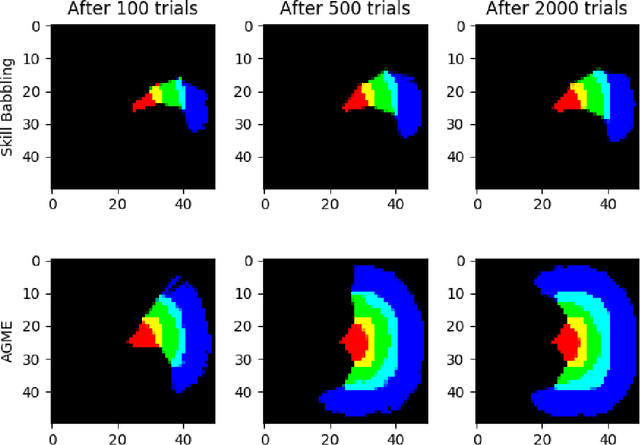
Open-ended learning is a core research field of machine learning and robotics aiming to build learning machines and robots able to autonomously acquire knowledge and skills and to reuse them to solve novel tasks. The multiple challenges posed by open-ended learning have been operationalized in the robotic competition REAL 2020. This requires a simulated camera-arm-gripper robot to (a) autonomously learn to interact with objects during an intrinsic phase where it can learn how to move objects and then (b) during an extrinsic phase, to re-use the acquired knowledge to accomplish externally given goals requiring the robot to move objects to specific locations unknown during the intrinsic phase. Here we present a 'baseline architecture' for solving the challenge, provided as baseline model for REAL 2020. Few models have all the functionalities needed to solve the REAL 2020 benchmark and none has been tested with it yet. The architecture we propose is formed by three components: (1) Abstractor: abstracting sensory input to learn relevant control variables from images; (2) Explorer: generating experience to learn goals and actions; (3) Planner: formulating and executing action plans to accomplish the externally provided goals. The architecture represents the first model to solve the simpler REAL 2020 'Round 1' allowing the use of a simple parameterised push action. On Round 2, the architecture was used with a more general action (sequence of joints positions) achieving again higher than chance level performance. The baseline software is well documented and available for download and use at https://github.com/AIcrowd/REAL2020_starter_kit.
Learning High-Level Planning Symbols from Intrinsically Motivated Experience
Jul 18, 2019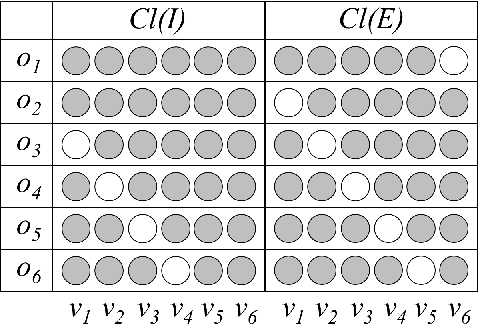
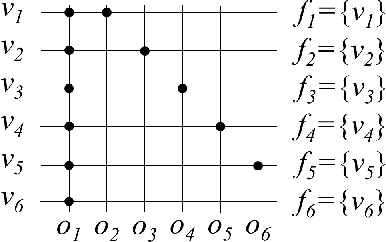
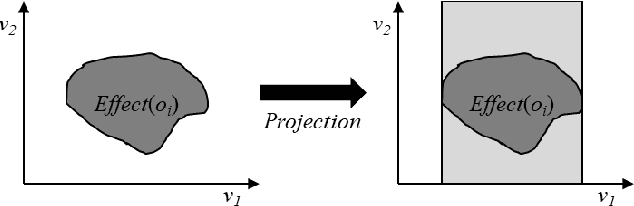
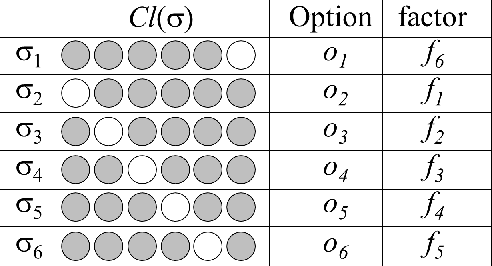
In symbolic planning systems, the knowledge on the domain is commonly provided by an expert. Recently, an automatic abstraction procedure has been proposed in the literature to create a Planning Domain Definition Language (PDDL) representation, which is the most widely used input format for most off-the-shelf automated planners, starting from `options', a data structure used to represent actions within the hierarchical reinforcement learning framework. We propose an architecture that potentially removes the need for human intervention. In particular, the architecture first acquires options in a fully autonomous fashion on the basis of open-ended learning, then builds a PDDL domain based on symbols and operators that can be used to accomplish user-defined goals through a standard PDDL planner. We start from an implementation of the above mentioned procedure tested on a set of benchmark domains in which a humanoid robot can change the state of some objects through direct interaction with the environment. We then investigate some critical aspects of the information abstraction process that have been observed, and propose an extension that mitigates such criticalities, in particular by analysing the type of classifiers that allow a suitable grounding of symbols.
Autonomous Reinforcement Learning of Multiple Interrelated Tasks
Jun 04, 2019
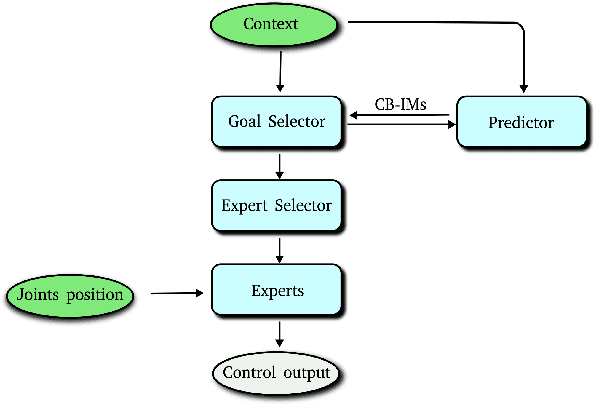
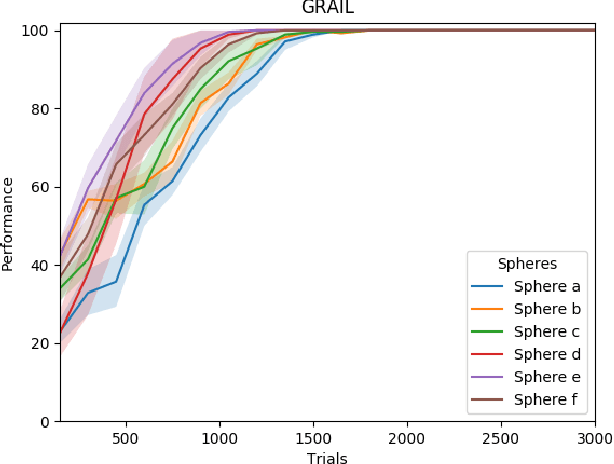
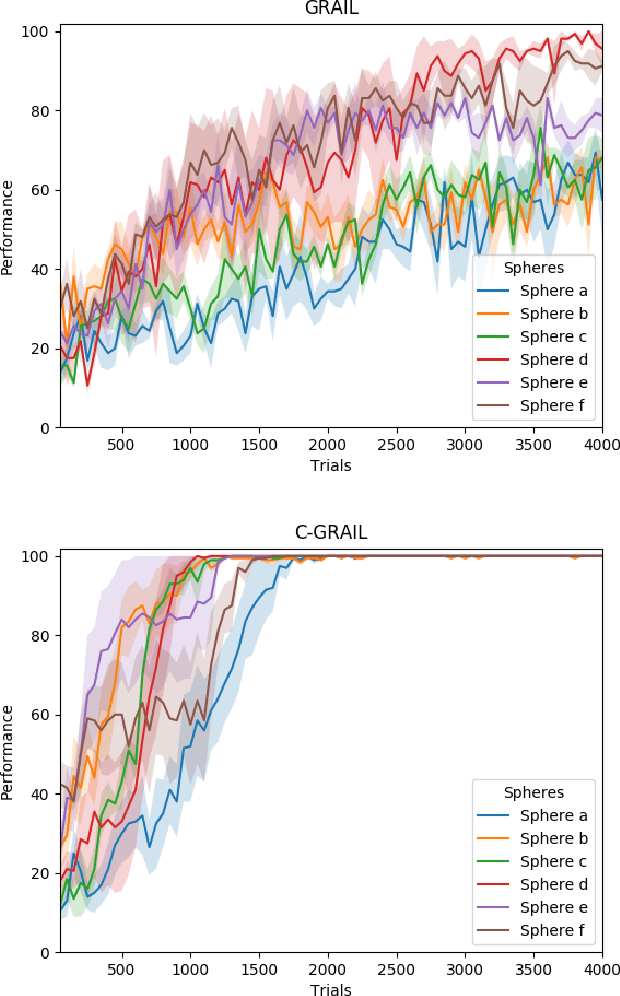
Autonomous multiple tasks learning is a fundamental capability to develop versatile artificial agents that can act in complex environments. In real-world scenarios, tasks may be interrelated (or "hierarchical") so that a robot has to first learn to achieve some of them to set the preconditions for learning other ones. Even though different strategies have been used in robotics to tackle the acquisition of interrelated tasks, in particular within the developmental robotics framework, autonomous learning in this kind of scenarios is still an open question. Building on previous research in the framework of intrinsically motivated open-ended learning, in this work we describe how this question can be addressed working on the level of task selection, in particular considering the multiple interrelated tasks scenario as an MDP where the system is trying to maximise its competence over all the tasks.
Autonomous Open-Ended Learning of Interdependent Tasks
May 07, 2019
Autonomy is fundamental for artificial agents acting in complex real-world scenarios. The acquisition of many different skills is pivotal to foster versatile autonomous behaviour and thus a main objective for robotics and machine learning. Intrinsic motivations have proven to properly generate a task-agnostic signal to drive the autonomous acquisition of multiple policies in settings requiring the learning of multiple tasks. However, in real world scenarios tasks may be interdependent so that some of them may constitute the precondition for learning other ones. Despite different strategies have been used to tackle the acquisition of interdependent/hierarchical tasks, fully autonomous open-ended learning in these scenarios is still an open question. Building on previous research within the framework of intrinsically-motivated open-ended learning, we propose an architecture for robot control that tackles this problem from the point of view of decision making, i.e. treating the selection of tasks as a Markov Decision Process where the system selects the policies to be trained in order to maximise its competence over all the tasks. The system is then tested with a humanoid robot solving interdependent multiple reaching tasks.
Autonomous discovery of the goal space to learn a parameterized skill
May 19, 2018
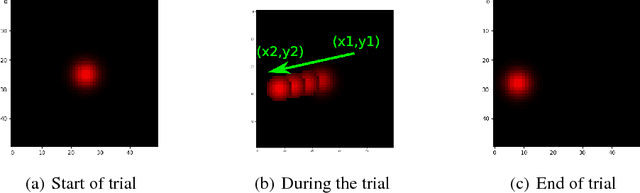
A parameterized skill is a mapping from multiple goals/task parameters to the policy parameters to accomplish them. Existing works in the literature show how a parameterized skill can be learned given a task space that defines all the possible achievable goals. In this work, we focus on tasks defined in terms of final states (goals), and we face on the challenge where the agent aims to autonomously acquire a parameterized skill to manipulate an initially unknown environment. In this case, the task space is not known a priori and the agent has to autonomously discover it. The agent may posit as a task space its whole sensory space (i.e. the space of all possible sensor readings) as the achievable goals will certainly be a subset of this space. However, the space of achievable goals may be a very tiny subspace in relation to the whole sensory space, thus directly using the sensor space as task space exposes the agent to the curse of dimensionality and makes existing autonomous skill acquisition algorithms inefficient. In this work we present an algorithm that actively discovers the manifold of the achievable goals within the sensor space. We validate the algorithm by employing it in multiple different simulated scenarios where the agent actions achieve different types of goals: moving a redundant arm, pushing an object, and changing the color of an object.