 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: A Self-supervised Framework for Improving Faithfulness in Conditional Text Generation
Feb 19, 2025Large Language Models (LLMs), when used for conditional text generation, often produce hallucinations, i.e., information that is unfaithful or not grounded in the input context. This issue arises in typical conditional text generation tasks, such as text summarization and data-to-text generation, where the goal is to produce fluent text based on contextual input. When fine-tuned on specific domains, LLMs struggle to provide faithful answers to a given context, often adding information or generating errors. One underlying cause of this issue is that LLMs rely on statistical patterns learned from their training data. This reliance can interfere with the model's ability to stay faithful to a provided context, leading to the generation of ungrounded information. We build upon this observation and introduce a novel self-supervised method for generating a training set of unfaithful samples. We then refine the model using a training process that encourages the generation of grounded outputs over unfaithful ones, drawing on preference-based training. Our approach leads to significantly more grounded text generation, outperforming existing self-supervised techniques in faithfulness, as evaluated through automatic metrics, LLM-based assessments, and human evaluations.
LOCOST: State-Space Models for Long Document Abstractive Summarization
Jan 31, 2024



State-space models are a low-complexity alternative to transformers for encoding long sequences and capturing long-term dependencies. We propose LOCOST: an encoder-decoder architecture based on state-space models for conditional text generation with long context inputs. With a computational complexity of $O(L \log L)$, this architecture can handle significantly longer sequences than state-of-the-art models that are based on sparse attention patterns. We evaluate our model on a series of long document abstractive summarization tasks. The model reaches a performance level that is 93-96% comparable to the top-performing sparse transformers of the same size while saving up to 50% memory during training and up to 87% during inference. Additionally, LOCOST effectively handles input texts exceeding 600K tokens at inference time, setting new state-of-the-art results on full-book summarization and opening new perspectives for long input processing.
Learning from Multiple Sources for Data-to-Text and Text-to-Data
Feb 22, 2023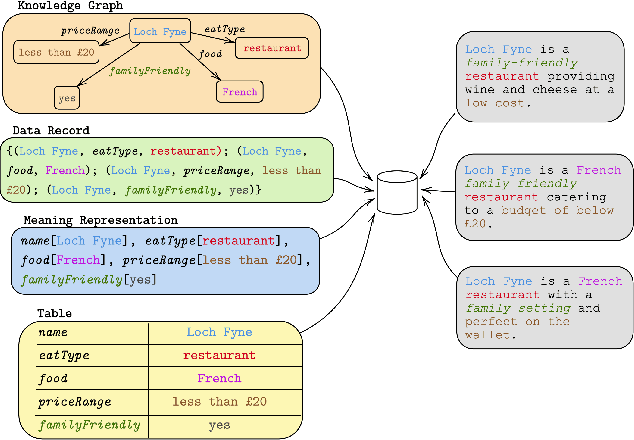
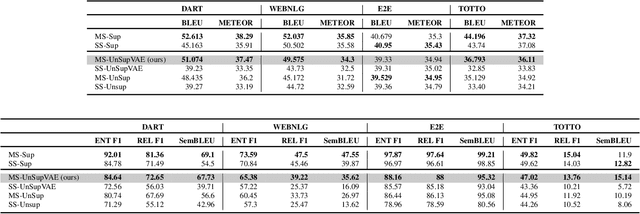
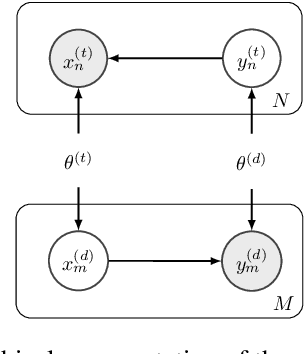
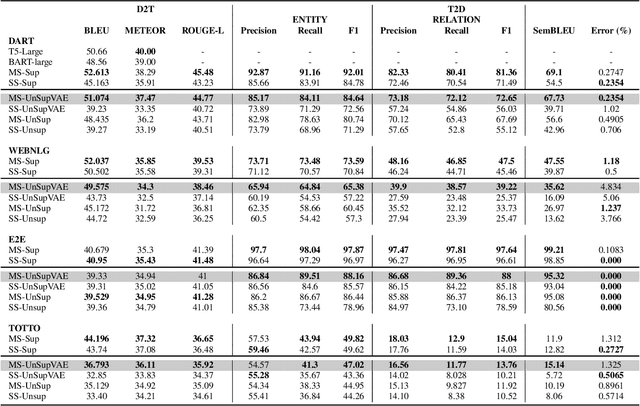
Data-to-text (D2T) and text-to-data (T2D) are dual tasks that convert structured data, such as graphs or tables into fluent text, and vice versa. These tasks are usually handled separately and use corpora extracted from a single source. Current systems leverage pre-trained language models fine-tuned on D2T or T2D tasks. This approach has two main limitations: first, a separate system has to be tuned for each task and source; second, learning is limited by the scarcity of available corpora. This paper considers a more general scenario where data are available from multiple heterogeneous sources. Each source, with its specific data format and semantic domain, provides a non-parallel corpus of text and structured data. We introduce a variational auto-encoder model with disentangled style and content variables that allows us to represent the diversity that stems from multiple sources of text and data. Our model is designed to handle the tasks of D2T and T2D jointly. We evaluate our model on several datasets, and show that by learning from multiple sources, our model closes the performance gap with its supervised single-source counterpart and outperforms it in some cases.
SaLinA: Sequential Learning of Agents
Oct 15, 2021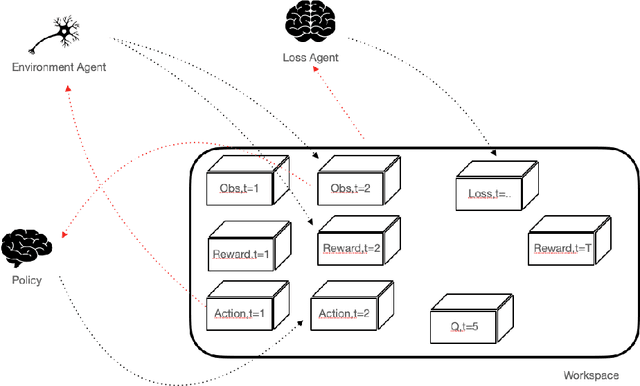


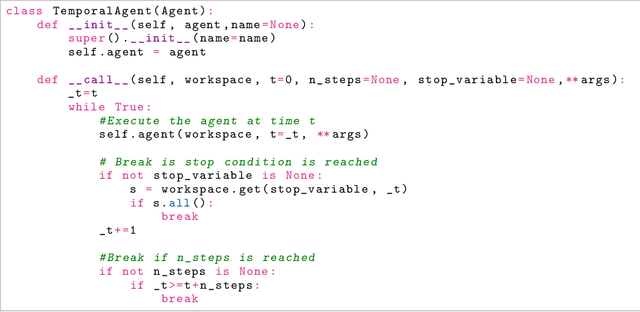
SaLinA is a simple library that makes implementing complex sequential learning models easy, including reinforcement learning algorithms. It is built as an extension of PyTorch: algorithms coded with \SALINA{} can be understood in few minutes by PyTorch users and modified easily. Moreover, SaLinA naturally works with multiple CPUs and GPUs at train and test time, thus being a good fit for the large-scale training use cases. In comparison to existing RL libraries, SaLinA has a very low adoption cost and capture a large variety of settings (model-based RL, batch RL, hierarchical RL, multi-agent RL, etc.). But SaLinA does not only target RL practitioners, it aims at providing sequential learning capabilities to any deep learning programmer.