 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: A Self-supervised Framework for Improving Faithfulness in Conditional Text Generation
Feb 19, 2025Large Language Models (LLMs), when used for conditional text generation, often produce hallucinations, i.e., information that is unfaithful or not grounded in the input context. This issue arises in typical conditional text generation tasks, such as text summarization and data-to-text generation, where the goal is to produce fluent text based on contextual input. When fine-tuned on specific domains, LLMs struggle to provide faithful answers to a given context, often adding information or generating errors. One underlying cause of this issue is that LLMs rely on statistical patterns learned from their training data. This reliance can interfere with the model's ability to stay faithful to a provided context, leading to the generation of ungrounded information. We build upon this observation and introduce a novel self-supervised method for generating a training set of unfaithful samples. We then refine the model using a training process that encourages the generation of grounded outputs over unfaithful ones, drawing on preference-based training. Our approach leads to significantly more grounded text generation, outperforming existing self-supervised techniques in faithfulness, as evaluated through automatic metrics, LLM-based assessments, and human evaluations.
LOCOST: State-Space Models for Long Document Abstractive Summarization
Jan 31, 2024



State-space models are a low-complexity alternative to transformers for encoding long sequences and capturing long-term dependencies. We propose LOCOST: an encoder-decoder architecture based on state-space models for conditional text generation with long context inputs. With a computational complexity of $O(L \log L)$, this architecture can handle significantly longer sequences than state-of-the-art models that are based on sparse attention patterns. We evaluate our model on a series of long document abstractive summarization tasks. The model reaches a performance level that is 93-96% comparable to the top-performing sparse transformers of the same size while saving up to 50% memory during training and up to 87% during inference. Additionally, LOCOST effectively handles input texts exceeding 600K tokens at inference time, setting new state-of-the-art results on full-book summarization and opening new perspectives for long input processing.
Learning from Multiple Sources for Data-to-Text and Text-to-Data
Feb 22, 2023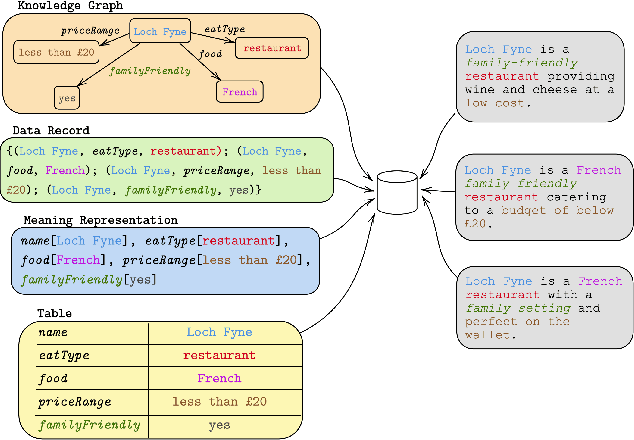
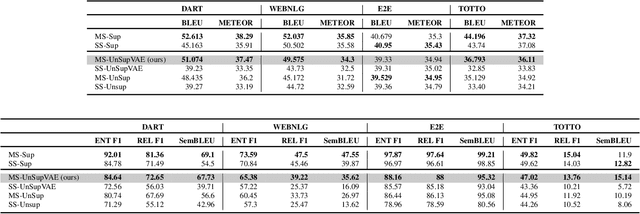
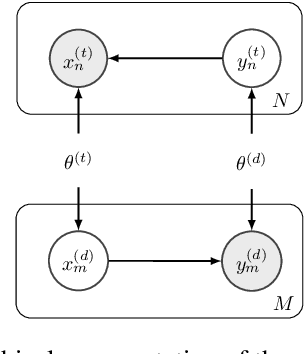
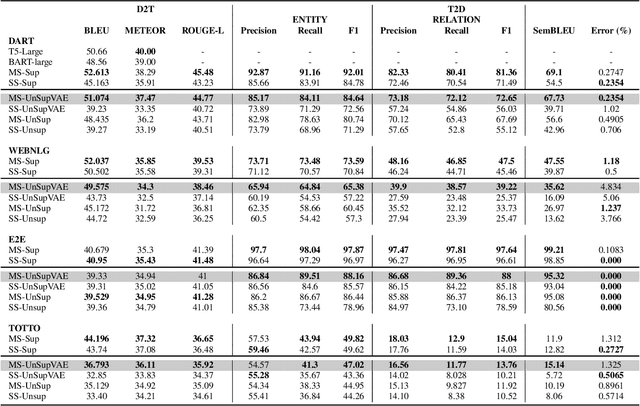
Data-to-text (D2T) and text-to-data (T2D) are dual tasks that convert structured data, such as graphs or tables into fluent text, and vice versa. These tasks are usually handled separately and use corpora extracted from a single source. Current systems leverage pre-trained language models fine-tuned on D2T or T2D tasks. This approach has two main limitations: first, a separate system has to be tuned for each task and source; second, learning is limited by the scarcity of available corpora. This paper considers a more general scenario where data are available from multiple heterogeneous sources. Each source, with its specific data format and semantic domain, provides a non-parallel corpus of text and structured data. We introduce a variational auto-encoder model with disentangled style and content variables that allows us to represent the diversity that stems from multiple sources of text and data. Our model is designed to handle the tasks of D2T and T2D jointly. We evaluate our model on several datasets, and show that by learning from multiple sources, our model closes the performance gap with its supervised single-source counterpart and outperforms it in some cases.
Non-parametric clustering over user features and latent behavioral functions with dual-view mixture models
Dec 18, 2018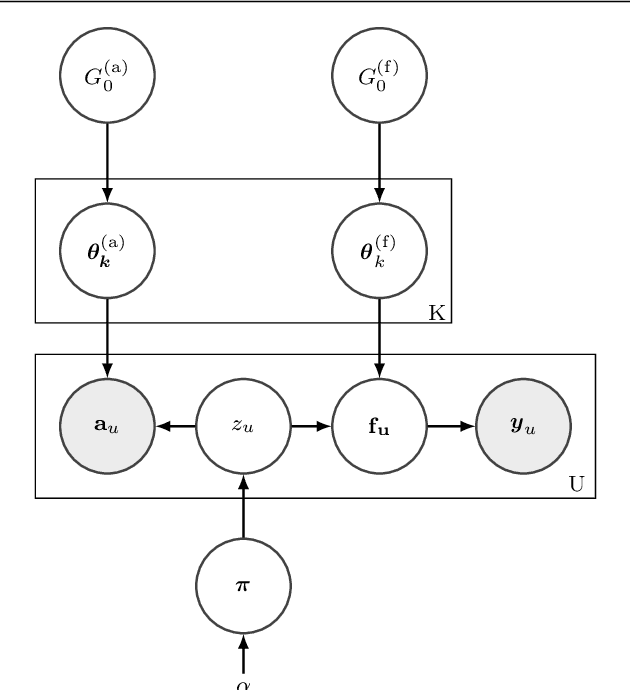
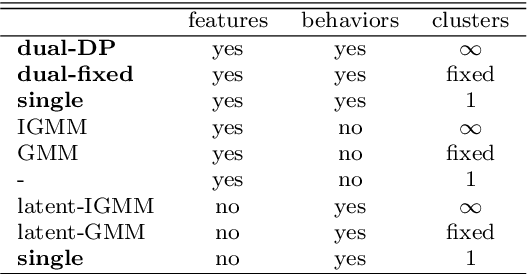
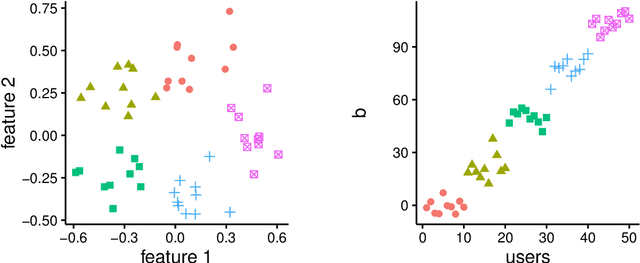
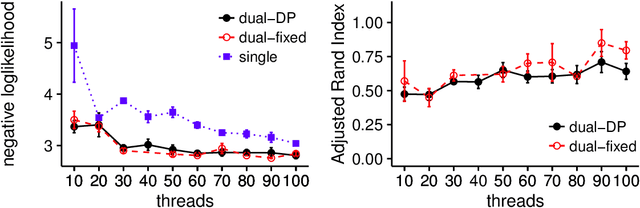
We present a dual-view mixture model to cluster users based on their features and latent behavioral functions. Every component of the mixture model represents a probability density over a feature view for observed user attributes and a behavior view for latent behavioral functions that are indirectly observed through user actions or behaviors. Our task is to infer the groups of users as well as their latent behavioral functions. We also propose a non-parametric version based on a Dirichlet Process to automatically infer the number of clusters. We test the properties and performance of the model on a synthetic dataset that represents the participation of users in the threads of an online forum. Experiments show that dual-view models outperform single-view ones when one of the views lacks information.
Bayesian Mean-parameterized Nonnegative Binary Matrix Factorization
Dec 17, 2018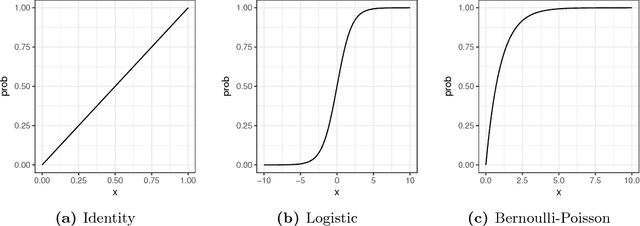
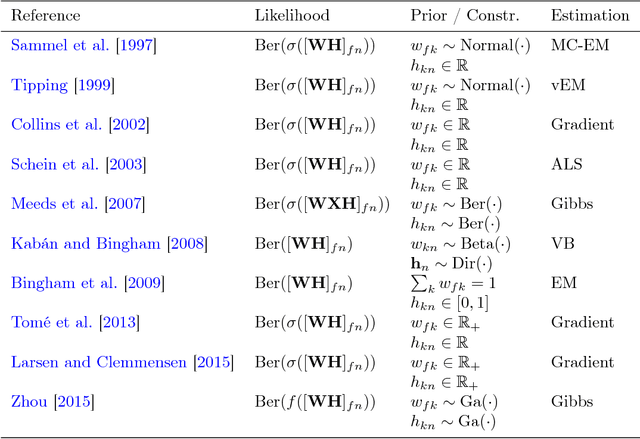

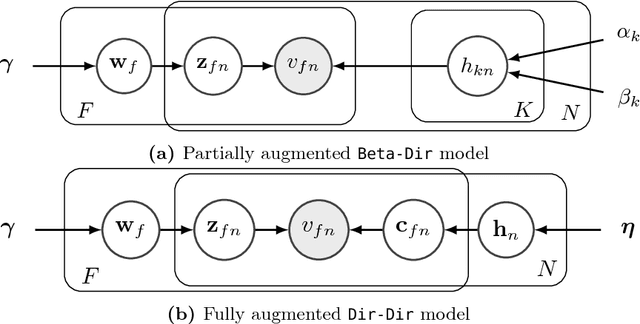
Binary data matrices can represent many types of data such as social networks, votes or gene expression. In some cases, the analysis of binary matrices can be tackled with nonnegative matrix factorization (NMF), where the observed data matrix is approximated by the product of two smaller nonnegative matrices. In this context, probabilistic NMF assumes a generative model where the data is usually Bernoulli-distributed. Often, a link function is used to map the factorization to the $[0,1]$ range, ensuring a valid Bernoulli mean parameter. However, link functions have the potential disadvantage to lead to uninterpretable models. Mean-parameterized NMF, on the contrary, overcomes this problem. We propose a unified framework for Bayesian mean-parameterized nonnegative binary matrix factorization models (NBMF). We analyze three models which correspond to three possible constraints that respect the mean-parametrization without the need for link functions. Furthermore, we derive a novel collapsed Gibbs sampler and a collapsed variational algorithm to infer the posterior distribution of the factors. Next, we extend the proposed models to a nonparametric setting where the number of used latent dimensions is automatically driven by the observed data. We analyze the performance of our NBMF methods in multiple datasets for different tasks such as dictionary learning and prediction of missing data. Experiments show that our methods provide similar or superior results than the state of the art, while automatically detecting the number of relevant components.
Closed-form Marginal Likelihood in Gamma-Poisson Matrix Factorization
May 31, 2018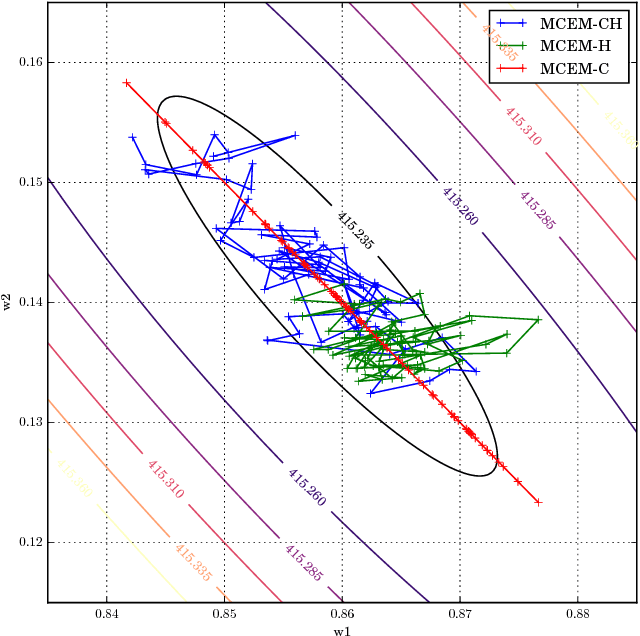
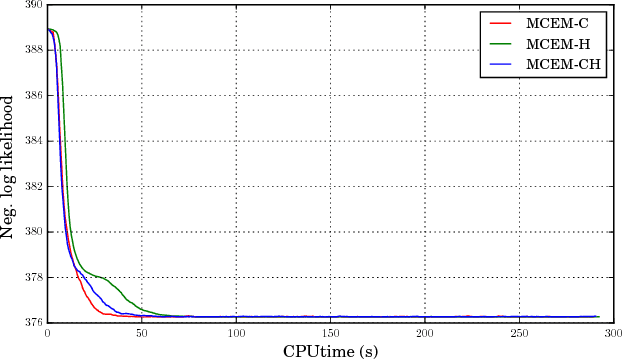
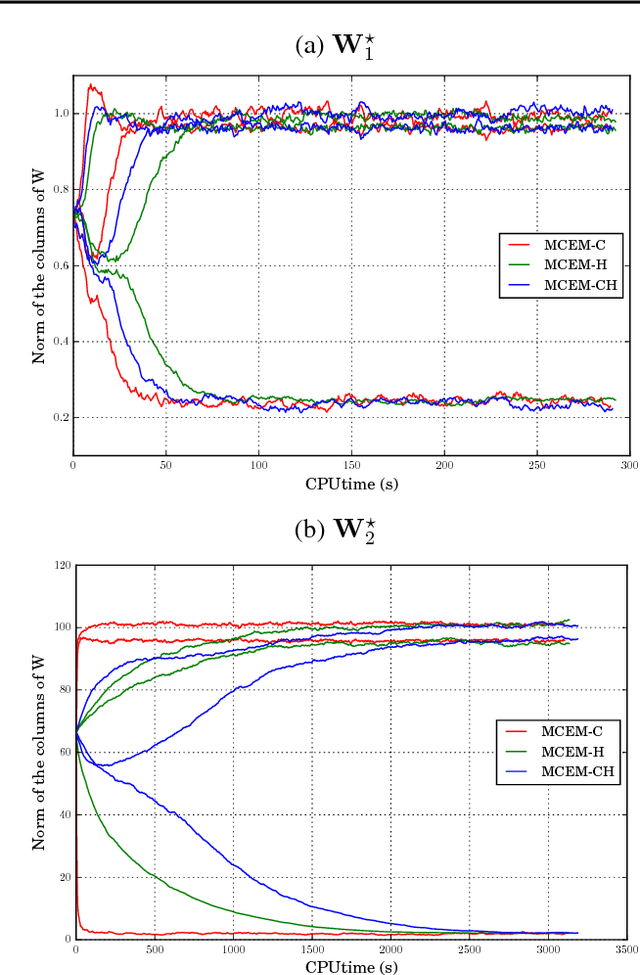
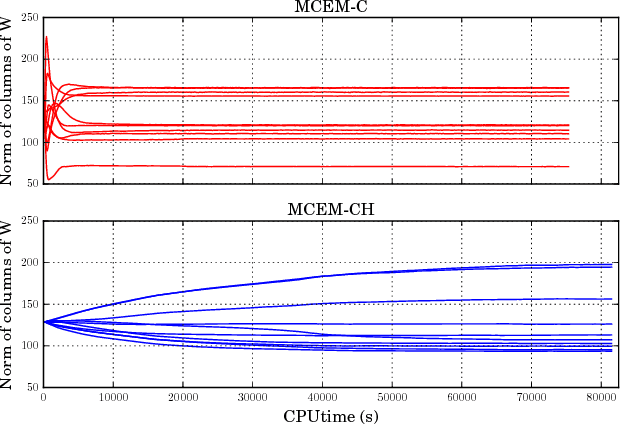
We present novel understandings of the Gamma-Poisson (GaP) model, a probabilistic matrix factorization model for count data. We show that GaP can be rewritten free of the score/activation matrix. This gives us new insights about the estimation of the topic/dictionary matrix by maximum marginal likelihood estimation. In particular, this explains the robustness of this estimator to over-specified values of the factorization rank, especially its ability to automatically prune irrelevant dictionary columns, as empirically observed in previous work. The marginalization of the activation matrix leads in turn to a new Monte Carlo Expectation-Maximization algorithm with favorable properties.