 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst do no harm: counterfactual objective functions for safe & ethical AI
Apr 27, 2022
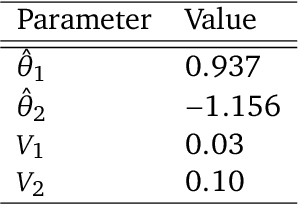
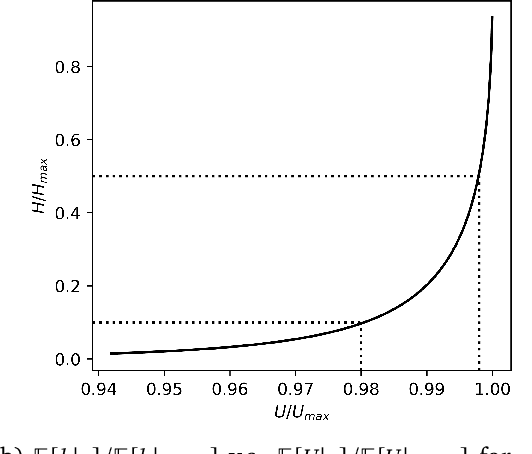
To act safely and ethically in the real world, agents must be able to reason about harm and avoid harmful actions. In this paper we develop the first statistical definition of harm and a framework for factoring harm into algorithmic decisions. We argue that harm is fundamentally a counterfactual quantity, and show that standard machine learning algorithms are guaranteed to pursue harmful policies in certain environments. To resolve this, we derive a family of counterfactual objective functions that robustly mitigate for harm. We demonstrate our approach with a statistical model for identifying optimal drug doses. While identifying optimal doses using the causal treatment effect results in harmful treatment decisions, our counterfactual algorithm identifies doses that are far less harmful without sacrificing efficacy. Our results show that counterfactual reasoning is a key ingredient for safe and ethical AI.
SaLinA: Sequential Learning of Agents
Oct 15, 2021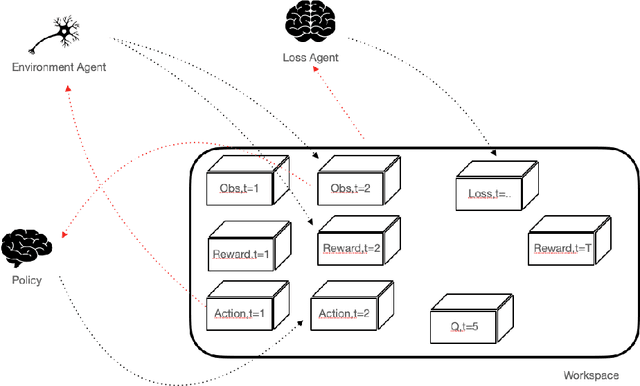


SaLinA is a simple library that makes implementing complex sequential learning models easy, including reinforcement learning algorithms. It is built as an extension of PyTorch: algorithms coded with \SALINA{} can be understood in few minutes by PyTorch users and modified easily. Moreover, SaLinA naturally works with multiple CPUs and GPUs at train and test time, thus being a good fit for the large-scale training use cases. In comparison to existing RL libraries, SaLinA has a very low adoption cost and capture a large variety of settings (model-based RL, batch RL, hierarchical RL, multi-agent RL, etc.). But SaLinA does not only target RL practitioners, it aims at providing sequential learning capabilities to any deep learning programmer.
Masking schemes for universal marginalisers
Jan 16, 2020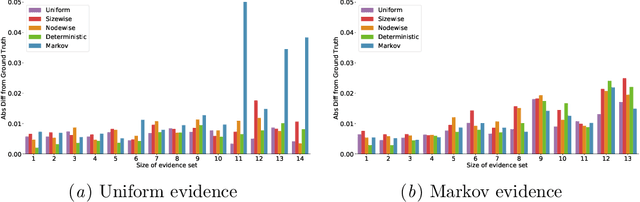
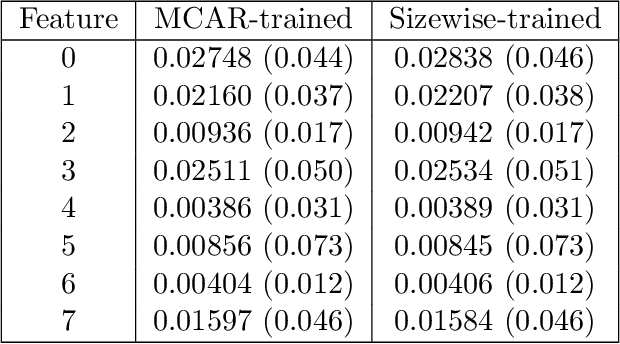

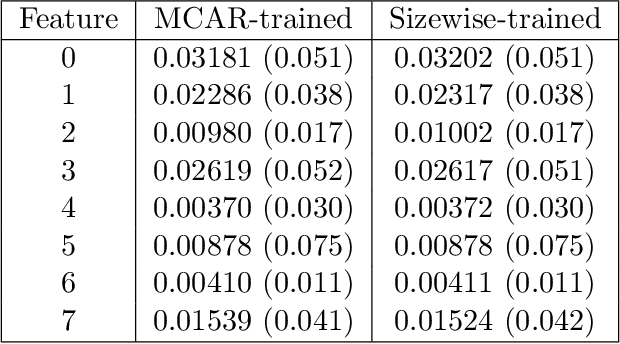
We consider the effect of structure-agnostic and structure-dependent masking schemes when training a universal marginaliser (arXiv:1711.00695) in order to learn conditional distributions of the form $P(x_i |\mathbf x_{\mathbf b})$, where $x_i$ is a given random variable and $\mathbf x_{\mathbf b}$ is some arbitrary subset of all random variables of the generative model of interest. In other words, we mimic the self-supervised training of a denoising autoencoder, where a dataset of unlabelled data is used as partially observed input and the neural approximator is optimised to minimise reconstruction loss. We focus on studying the underlying process of the partially observed data---how good is the neural approximator at learning all conditional distributions when the observation process at prediction time differs from the masking process during training? We compare networks trained with different masking schemes in terms of their predictive performance and generalisation properties.