 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst do no harm: counterfactual objective functions for safe & ethical AI
Paper and Code
Apr 27, 2022
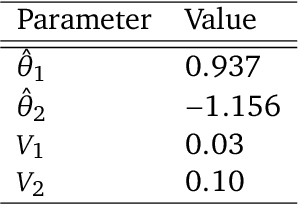
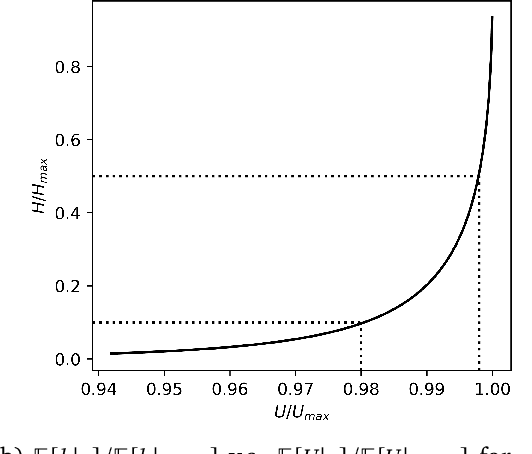
To act safely and ethically in the real world, agents must be able to reason about harm and avoid harmful actions. In this paper we develop the first statistical definition of harm and a framework for factoring harm into algorithmic decisions. We argue that harm is fundamentally a counterfactual quantity, and show that standard machine learning algorithms are guaranteed to pursue harmful policies in certain environments. To resolve this, we derive a family of counterfactual objective functions that robustly mitigate for harm. We demonstrate our approach with a statistical model for identifying optimal drug doses. While identifying optimal doses using the causal treatment effect results in harmful treatment decisions, our counterfactual algorithm identifies doses that are far less harmful without sacrificing efficacy. Our results show that counterfactual reasoning is a key ingredient for safe and ethical AI.