 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Procedural Content Generation Benchmark: An Open-source Testbed for Generative Challenges in Games
Mar 27, 2025

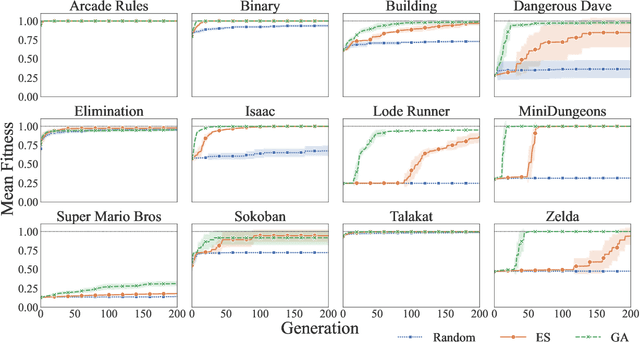

This paper introduces the Procedural Content Generation Benchmark for evaluating generative algorithms on different game content creation tasks. The benchmark comes with 12 game-related problems with multiple variants on each problem. Problems vary from creating levels of different kinds to creating rule sets for simple arcade games. Each problem has its own content representation, control parameters, and evaluation metrics for quality, diversity, and controllability. This benchmark is intended as a first step towards a standardized way of comparing generative algorithms. We use the benchmark to score three baseline algorithms: a random generator, an evolution strategy, and a genetic algorithm. Results show that some problems are easier to solve than others, as well as the impact the chosen objective has on quality, diversity, and controllability of the generated artifacts.
Affectively Framework: Towards Human-like Affect-Based Agents
Jul 25, 2024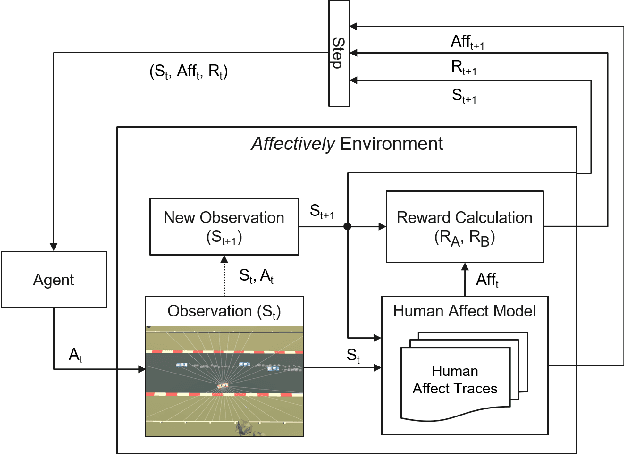

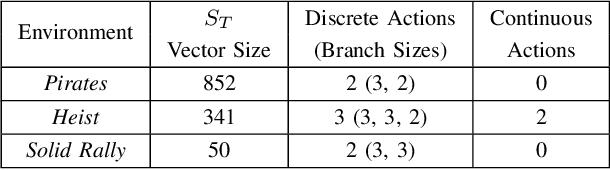

Game environments offer a unique opportunity for training virtual agents due to their interactive nature, which provides diverse play traces and affect labels. Despite their potential, no reinforcement learning framework incorporates human affect models as part of their observation space or reward mechanism. To address this, we present the \emph{Affectively Framework}, a set of Open-AI Gym environments that integrate affect as part of the observation space. This paper introduces the framework and its three game environments and provides baseline experiments to validate its effectiveness and potential.
Dynamic Quality-Diversity Search
Apr 07, 2024Evolutionary search via the quality-diversity (QD) paradigm can discover highly performing solutions in different behavioural niches, showing considerable potential in complex real-world scenarios such as evolutionary robotics. Yet most QD methods only tackle static tasks that are fixed over time, which is rarely the case in the real world. Unlike noisy environments, where the fitness of an individual changes slightly at every evaluation, dynamic environments simulate tasks where external factors at unknown and irregular intervals alter the performance of the individual with a severity that is unknown a priori. Literature on optimisation in dynamic environments is extensive, yet such environments have not been explored in the context of QD search. This paper introduces a novel and generalisable Dynamic QD methodology that aims to keep the archive of past solutions updated in the case of environment changes. Secondly, we present a novel characterisation of dynamic environments that can be easily applied to well-known benchmarks, with minor interventions to move them from a static task to a dynamic one. Our Dynamic QD intervention is applied on MAP-Elites and CMA-ME, two powerful QD algorithms, and we test the dynamic variants on different dynamic tasks.
Large Language Models and Games: A Survey and Roadmap
Feb 28, 2024Recent years have seen an explosive increase in research on large language models (LLMs), and accompanying public engagement on the topic. While starting as a niche area within natural language processing, LLMs have shown remarkable potential across a broad range of applications and domains, including games. This paper surveys the current state of the art across the various applications of LLMs in and for games, and identifies the different roles LLMs can take within a game. Importantly, we discuss underexplored areas and promising directions for future uses of LLMs in games and we reconcile the potential and limitations of LLMs within the games domain. As the first comprehensive survey and roadmap at the intersection of LLMs and games, we are hopeful that this paper will serve as the basis for groundbreaking research and innovation in this exciting new field.
Preference-Learning Emitters for Mixed-Initiative Quality-Diversity Algorithms
Oct 25, 2022

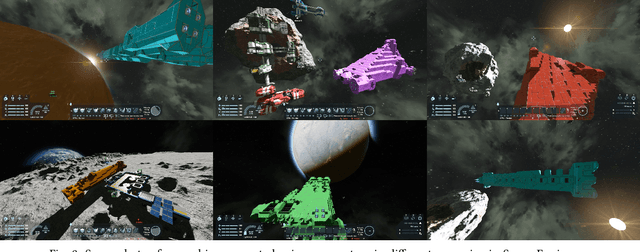
In mixed-initiative co-creation tasks, where a human and a machine jointly create items, it is valuable for the generative system to provide multiple relevant suggestions to the designer. Quality-diversity algorithms have been commonly used for this, as they can provide diverse suggestions that are representative of salient areas of the solution space, showcasing solutions with both high fitness and different properties that the designer might be interested in. Since these suggestions are what drives the search process, it is important that they provide the right inspiration for the designer, as well as not stray too far away from the search trajectory, i.e., they should be aligned with what the designer is looking for. Additionally, in most cases, many interactions with the system are required before the designer is content with a solution. In this work, we tackle both of these problems with an interactive constrained MAP-Elites system by crafting emitters that are able to learn the preferences of the designer and use them in automated hidden steps. By learning such preferences, we remain aligned with the designer's intentions, and by applying automatic steps, we generate more solutions per system interaction, giving a larger number of choices to the designer and speeding up the search process. We propose a general framework for preference-learning emitters and test it on a procedural content generation task in the video game Space Engineers. In an internal study, we show that preference-learning emitters allow users to more quickly find relevant solutions.
Surrogate Infeasible Fitness Acquirement FI-2Pop for Procedural Content Generation
May 12, 2022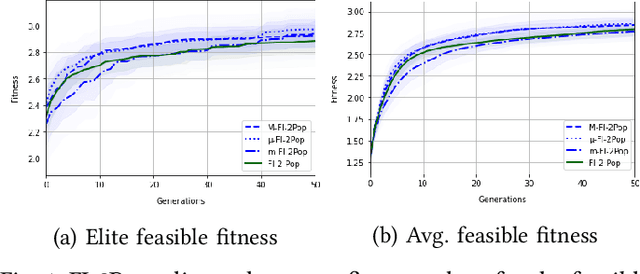
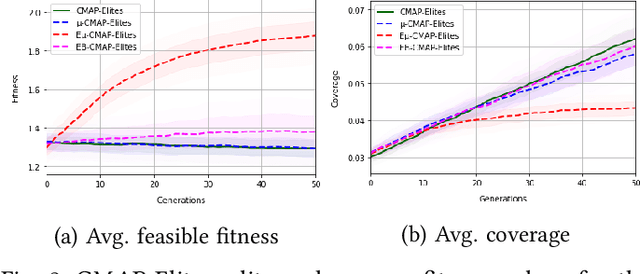

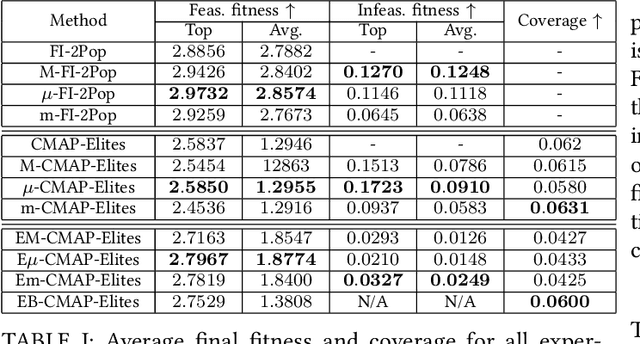
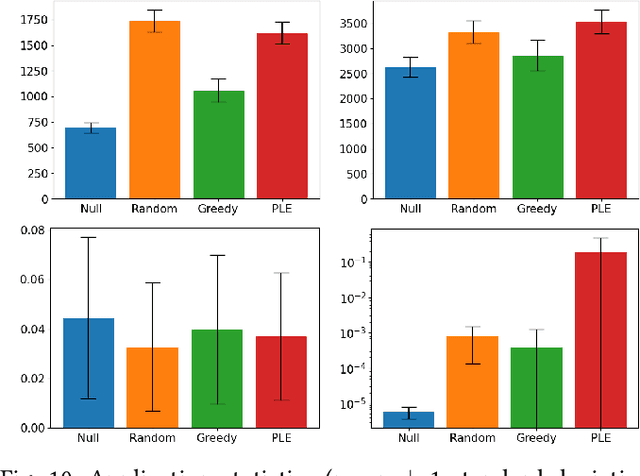
When generating content for video games using procedural content generation (PCG), the goal is to create functional assets of high quality. Prior work has commonly leveraged the feasible-infeasible two-population (FI-2Pop) constrained optimisation algorithm for PCG, sometimes in combination with the multi-dimensional archive of phenotypic-elites (MAP-Elites) algorithm for finding a set of diverse solutions. However, the fitness function for the infeasible population only takes into account the number of constraints violated. In this paper we present a variant of FI-2Pop in which a surrogate model is trained to predict the fitness of feasible children from infeasible parents, weighted by the probability of producing feasible children. This drives selection towards higher-fitness, feasible solutions. We demonstrate our method on the task of generating spaceships for Space Engineers, showing improvements over both standard FI-2Pop, and the more recent multi-emitter constrained MAP-Elites algorithm.