 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotions as Ambiguity-aware Ordinal Representations
Aug 27, 2025Emotions are inherently ambiguous and dynamic phenomena, yet existing continuous emotion recognition approaches either ignore their ambiguity or treat ambiguity as an independent and static variable over time. Motivated by this gap in the literature, in this paper we introduce ambiguity-aware ordinal emotion representations, a novel framework that captures both the ambiguity present in emotion annotation and the inherent temporal dynamics of emotional traces. Specifically, we propose approaches that model emotion ambiguity through its rate of change. We evaluate our framework on two affective corpora -- RECOLA and GameVibe -- testing our proposed approaches on both bounded (arousal, valence) and unbounded (engagement) continuous traces. Our results demonstrate that ordinal representations outperform conventional ambiguity-aware models on unbounded labels, achieving the highest Concordance Correlation Coefficient (CCC) and Signed Differential Agreement (SDA) scores, highlighting their effectiveness in modeling the traces' dynamics. For bounded traces, ordinal representations excel in SDA, revealing their superior ability to capture relative changes of annotated emotion traces.
The Procedural Content Generation Benchmark: An Open-source Testbed for Generative Challenges in Games
Mar 27, 2025This paper introduces the Procedural Content Generation Benchmark for evaluating generative algorithms on different game content creation tasks. The benchmark comes with 12 game-related problems with multiple variants on each problem. Problems vary from creating levels of different kinds to creating rule sets for simple arcade games. Each problem has its own content representation, control parameters, and evaluation metrics for quality, diversity, and controllability. This benchmark is intended as a first step towards a standardized way of comparing generative algorithms. We use the benchmark to score three baseline algorithms: a random generator, an evolution strategy, and a genetic algorithm. Results show that some problems are easier to solve than others, as well as the impact the chosen objective has on quality, diversity, and controllability of the generated artifacts.
Can Large Language Models Capture Video Game Engagement?
Feb 05, 2025



Can out-of-the-box pretrained Large Language Models (LLMs) detect human affect successfully when observing a video? To address this question, for the first time, we evaluate comprehensively the capacity of popular LLMs to annotate and successfully predict continuous affect annotations of videos when prompted by a sequence of text and video frames in a multimodal fashion. Particularly in this paper, we test LLMs' ability to correctly label changes of in-game engagement in 80 minutes of annotated videogame footage from 20 first-person shooter games of the GameVibe corpus. We run over 2,400 experiments to investigate the impact of LLM architecture, model size, input modality, prompting strategy, and ground truth processing method on engagement prediction. Our findings suggest that while LLMs rightfully claim human-like performance across multiple domains, they generally fall behind capturing continuous experience annotations provided by humans. We examine some of the underlying causes for the relatively poor overall performance, highlight the cases where LLMs exceed expectations, and draw a roadmap for the further exploration of automated emotion labelling via LLMs.
Affectively Framework: Towards Human-like Affect-Based Agents
Jul 25, 2024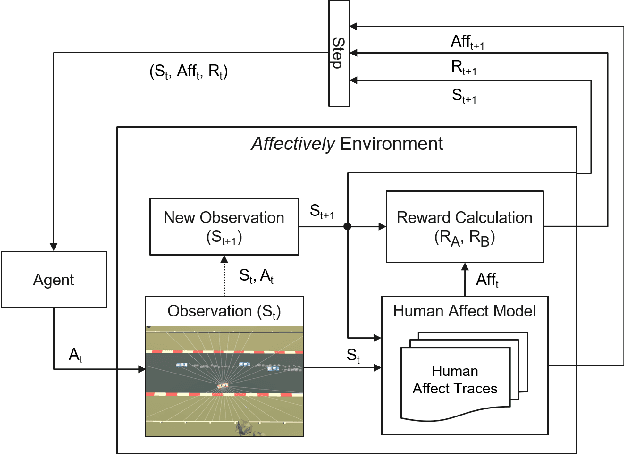

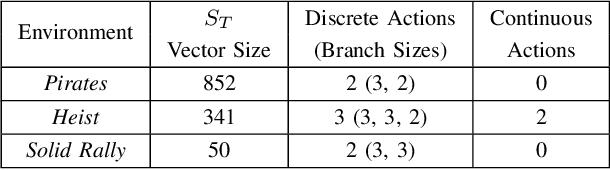

Game environments offer a unique opportunity for training virtual agents due to their interactive nature, which provides diverse play traces and affect labels. Despite their potential, no reinforcement learning framework incorporates human affect models as part of their observation space or reward mechanism. To address this, we present the \emph{Affectively Framework}, a set of Open-AI Gym environments that integrate affect as part of the observation space. This paper introduces the framework and its three game environments and provides baseline experiments to validate its effectiveness and potential.
Open-Ended Evolution for Minecraft Building Generation
Sep 07, 2022



This paper proposes a procedural content generator which evolves Minecraft buildings according to an open-ended and intrinsic definition of novelty. To realize this goal we evaluate individuals' novelty in the latent space using a 3D autoencoder, and alternate between phases of exploration and transformation. During exploration the system evolves multiple populations of CPPNs through CPPN-NEAT and constrained novelty search in the latent space (defined by the current autoencoder). We apply a set of repair and constraint functions to ensure candidates adhere to basic structural rules and constraints during evolution. During transformation, we reshape the boundaries of the latent space to identify new interesting areas of the solution space by retraining the autoencoder with novel content. In this study we evaluate five different approaches for training the autoencoder during transformation and its impact on populations' quality and diversity during evolution. Our results show that by retraining the autoencoder we can achieve better open-ended complexity compared to a static model, which is further improved when retraining using larger datasets of individuals with diverse complexities.
Play with Emotion: Affect-Driven Reinforcement Learning
Aug 26, 2022
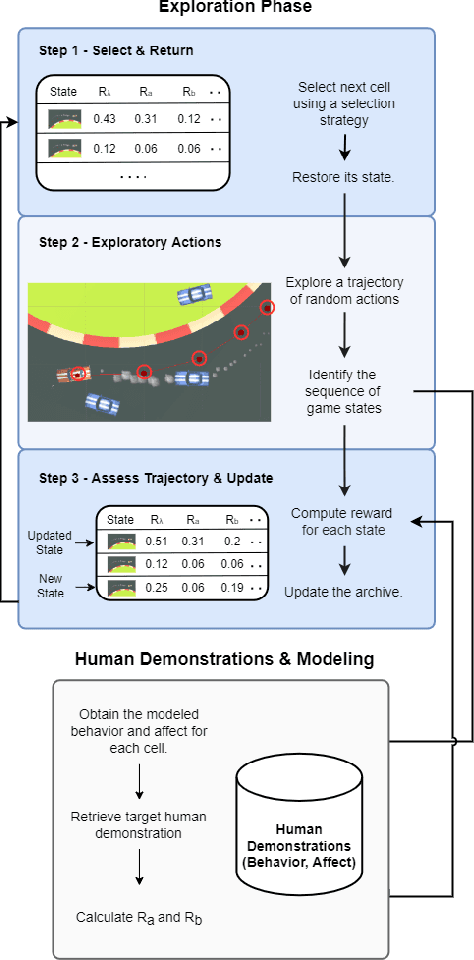


This paper introduces a paradigm shift by viewing the task of affect modeling as a reinforcement learning (RL) process. According to the proposed paradigm, RL agents learn a policy (i.e. affective interaction) by attempting to maximize a set of rewards (i.e. behavioral and affective patterns) via their experience with their environment (i.e. context). Our hypothesis is that RL is an effective paradigm for interweaving affect elicitation and manifestation with behavioral and affective demonstrations. Importantly, our second hypothesis-building on Damasio's somatic marker hypothesis-is that emotion can be the facilitator of decision-making. We test our hypotheses in a racing game by training Go-Blend agents to model human demonstrations of arousal and behavior; Go-Blend is a modified version of the Go-Explore algorithm which has recently showcased supreme performance in hard exploration tasks. We first vary the arousal-based reward function and observe agents that can effectively display a palette of affect and behavioral patterns according to the specified reward. Then we use arousal-based state selection mechanisms in order to bias the strategies that Go-Blend explores. Our findings suggest that Go-Blend not only is an efficient affect modeling paradigm but, more importantly, affect-driven RL improves exploration and yields higher performing agents, validating Damasio's hypothesis in the domain of games.
Go-Blend behavior and affect
Sep 24, 2021

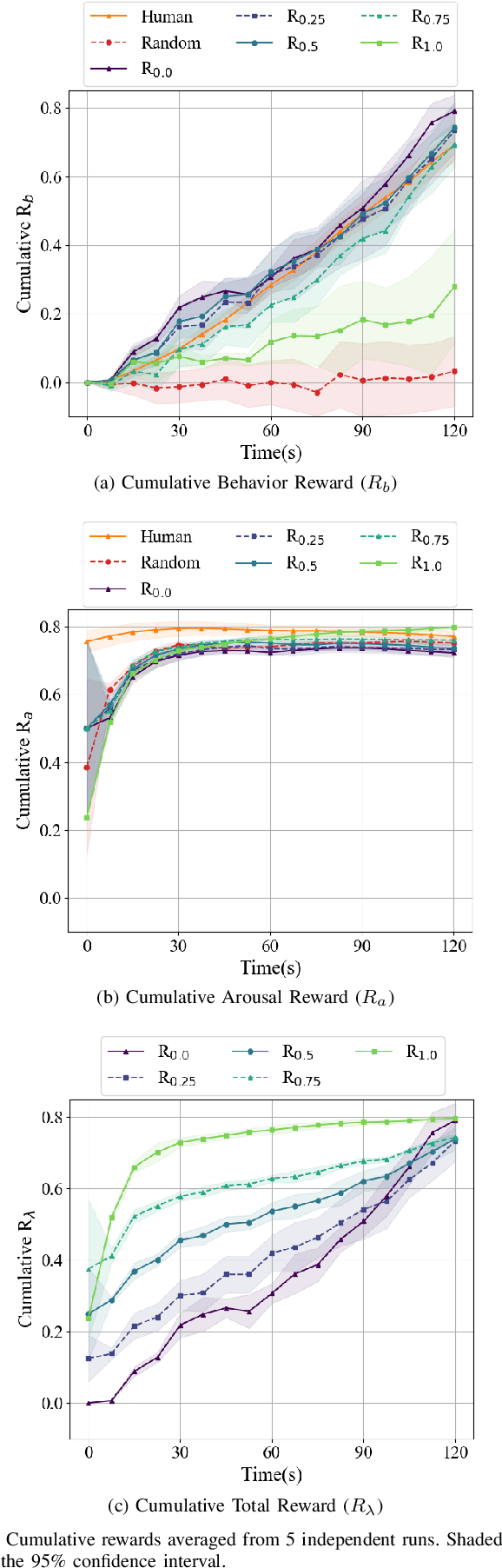

This paper proposes a paradigm shift for affective computing by viewing the affect modeling task as a reinforcement learning process. According to our proposed framework the context (environment) and the actions of an agent define the common representation that interweaves behavior and affect. To realise this framework we build on recent advances in reinforcement learning and use a modified version of the Go-Explore algorithm which has showcased supreme performance in hard exploration tasks. In this initial study, we test our framework in an arcade game by training Go-Explore agents to both play optimally and attempt to mimic human demonstrations of arousal. We vary the degree of importance between optimal play and arousal imitation and create agents that can effectively display a palette of affect and behavioral patterns. Our Go-Explore implementation not only introduces a new paradigm for affect modeling; it empowers believable AI-based game testing by providing agents that can blend and express a multitude of behavioral and affective patterns.