 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlay with Emotion: Affect-Driven Reinforcement Learning
Paper and Code
Aug 26, 2022
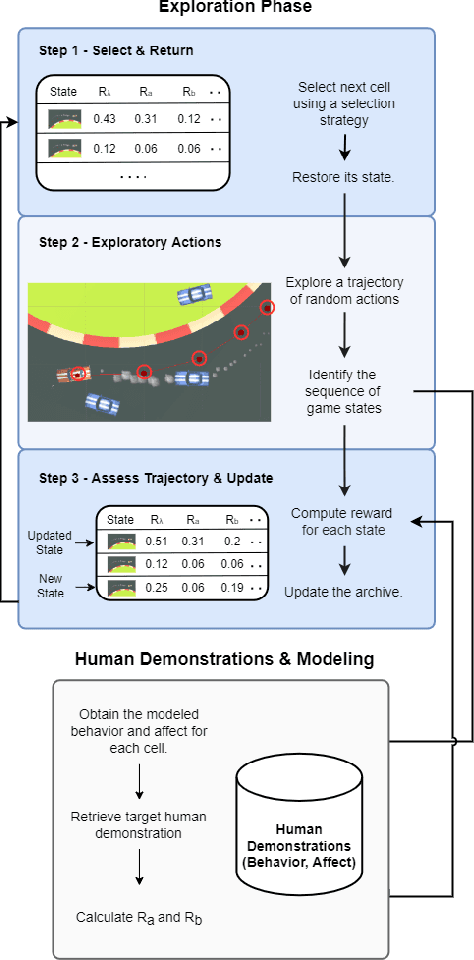


This paper introduces a paradigm shift by viewing the task of affect modeling as a reinforcement learning (RL) process. According to the proposed paradigm, RL agents learn a policy (i.e. affective interaction) by attempting to maximize a set of rewards (i.e. behavioral and affective patterns) via their experience with their environment (i.e. context). Our hypothesis is that RL is an effective paradigm for interweaving affect elicitation and manifestation with behavioral and affective demonstrations. Importantly, our second hypothesis-building on Damasio's somatic marker hypothesis-is that emotion can be the facilitator of decision-making. We test our hypotheses in a racing game by training Go-Blend agents to model human demonstrations of arousal and behavior; Go-Blend is a modified version of the Go-Explore algorithm which has recently showcased supreme performance in hard exploration tasks. We first vary the arousal-based reward function and observe agents that can effectively display a palette of affect and behavioral patterns according to the specified reward. Then we use arousal-based state selection mechanisms in order to bias the strategies that Go-Blend explores. Our findings suggest that Go-Blend not only is an efficient affect modeling paradigm but, more importantly, affect-driven RL improves exploration and yields higher performing agents, validating Damasio's hypothesis in the domain of games.