 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Supervised Auxiliary Loss for Deep RL in Partially Observable Settings
Apr 17, 2021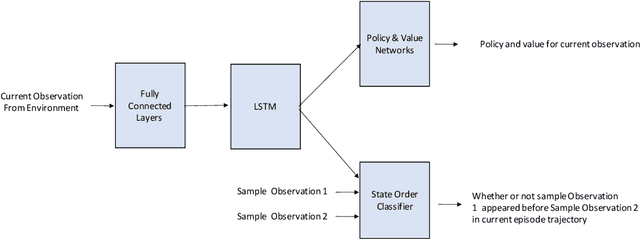


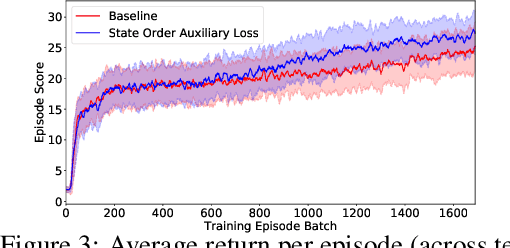
In this work we explore an auxiliary loss useful for reinforcement learning in environments where strong performing agents are required to be able to navigate a spatial environment. The auxiliary loss proposed is to minimize the classification error of a neural network classifier that predicts whether or not a pair of states sampled from the agents current episode trajectory are in order. The classifier takes as input a pair of states as well as the agent's memory. The motivation for this auxiliary loss is that there is a strong correlation with which of a pair of states is more recent in the agents episode trajectory and which of the two states is spatially closer to the agent. Our hypothesis is that learning features to answer this question encourages the agent to learn and internalize in memory representations of states that facilitate spatial reasoning. We tested this auxiliary loss on a navigation task in a gridworld and achieved 9.6% increase in accumulative episode reward compared to a strong baseline approach.
AI-QMIX: Attention and Imagination for Dynamic Multi-Agent Reinforcement Learning
Jun 07, 2020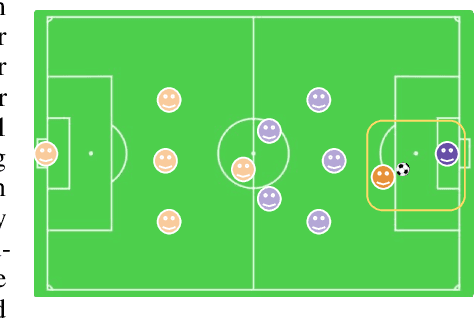

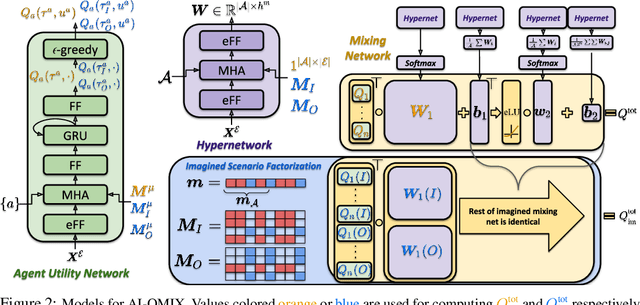
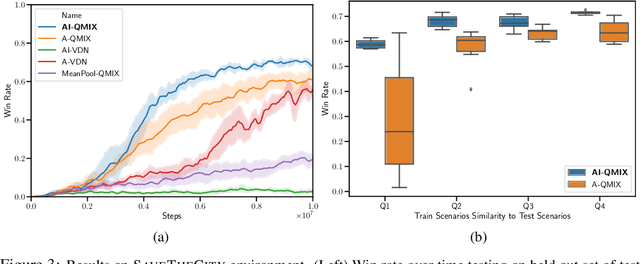
Real world multi-agent tasks often involve varying types and quantities of agents and non-agent entities. Agents frequently do not know a priori how many other agents and non-agent entities they will need to interact with in order to complete a given task, requiring agents to generalize across a combinatorial number of task configurations with each potentially requiring different strategies. In this work, we tackle the problem of multi-agent reinforcement learning (MARL) in such dynamic scenarios. We hypothesize that, while the optimal behaviors in these scenarios with varying quantities and types of agents/entities are diverse, they may share common patterns within sub-teams of agents that are combined to form team behavior. As such, we propose a method that can learn these sub-group relationships and how they can be combined, ultimately improving knowledge sharing and generalization across scenarios. This method, Attentive-Imaginative QMIX, extends QMIX for dynamic MARL in two ways: 1) an attention mechanism that enables model sharing across variable sized scenarios and 2) a training objective that improves learning across scenarios with varying combinations of agent/entity types by factoring the value function into imagined sub-scenarios. We validate our approach on both a novel grid-world task as well as a version of the StarCraft Multi-Agent Challenge minimally modified for the dynamic scenario setting. The results in these domains validate the effectiveness of the two new components in generalizing across dynamic configurations of agents and entities.
Multi-Agent Common Knowledge Reinforcement Learning
Nov 05, 2018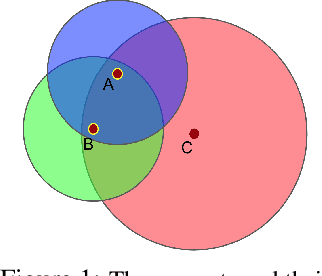

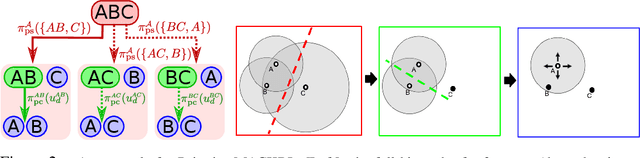
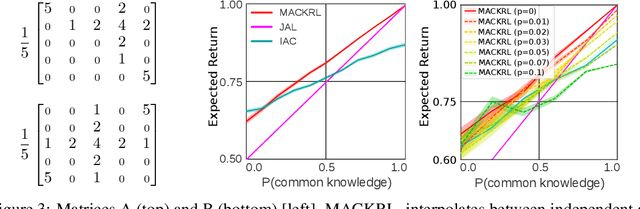
In multi-agent reinforcement learning, centralised policies can only be executed if agents have access to either the global state or an instantaneous communication channel. An alternative approach that circumvents this limitation is to use centralised training of a set of decentralised policies. However, such policies severely limit the agents' ability to coordinate. We propose multi-agent common knowledge reinforcement learning (MACKRL), which strikes a middle ground between these two extremes. Our approach is based on the insight that, even in partially observable settings, subsets of agents often have some common knowledge that they can exploit to coordinate their behaviour. Common knowledge can arise, e.g., if all agents can reliably observe things in their own field of view and know the field of view of other agents. Using this additional information, it is possible to find a centralised policy that conditions only on agents' common knowledge and that can be executed in a decentralised fashion. A resulting challenge is then to determine at what level agents should coordinate. While the common knowledge shared among all agents may not contain much valuable information, there may be subgroups of agents that share common knowledge useful for coordination. MACKRL addresses this challenge using a hierarchical approach: at each level, a controller can either select a joint action for the agents in a given subgroup, or propose a partition of the agents into smaller subgroups whose actions are then selected by controllers at the next level. While action selection involves sampling hierarchically, learning updates are based on the probability of the joint action, calculated by marginalising across the possible decisions of the hierarchy. We show promising results on both a proof-of-concept matrix game and a multi-agent version of StarCraft II Micromanagement.