 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-QMIX: Attention and Imagination for Dynamic Multi-Agent Reinforcement Learning
Paper and Code
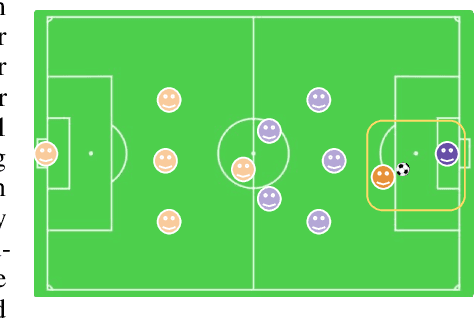

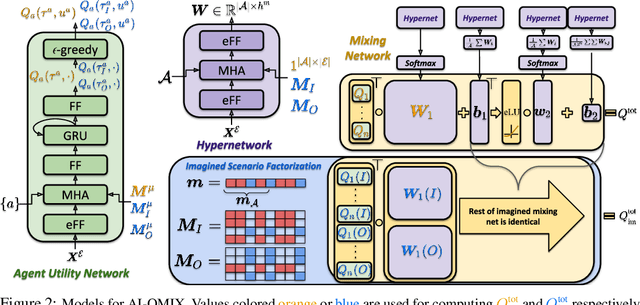
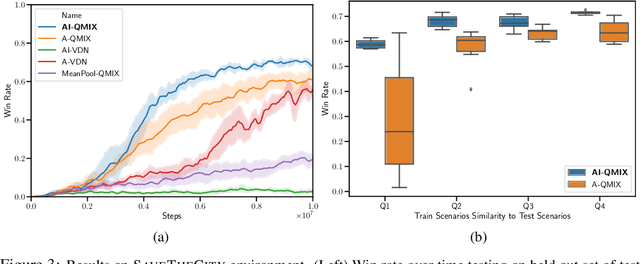
Real world multi-agent tasks often involve varying types and quantities of agents and non-agent entities. Agents frequently do not know a priori how many other agents and non-agent entities they will need to interact with in order to complete a given task, requiring agents to generalize across a combinatorial number of task configurations with each potentially requiring different strategies. In this work, we tackle the problem of multi-agent reinforcement learning (MARL) in such dynamic scenarios. We hypothesize that, while the optimal behaviors in these scenarios with varying quantities and types of agents/entities are diverse, they may share common patterns within sub-teams of agents that are combined to form team behavior. As such, we propose a method that can learn these sub-group relationships and how they can be combined, ultimately improving knowledge sharing and generalization across scenarios. This method, Attentive-Imaginative QMIX, extends QMIX for dynamic MARL in two ways: 1) an attention mechanism that enables model sharing across variable sized scenarios and 2) a training objective that improves learning across scenarios with varying combinations of agent/entity types by factoring the value function into imagined sub-scenarios. We validate our approach on both a novel grid-world task as well as a version of the StarCraft Multi-Agent Challenge minimally modified for the dynamic scenario setting. The results in these domains validate the effectiveness of the two new components in generalizing across dynamic configurations of agents and entities.