 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Common Knowledge Reinforcement Learning
Paper and Code
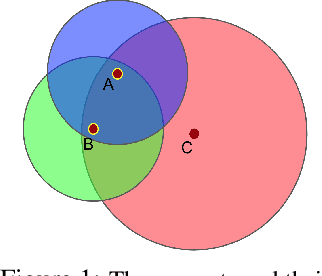

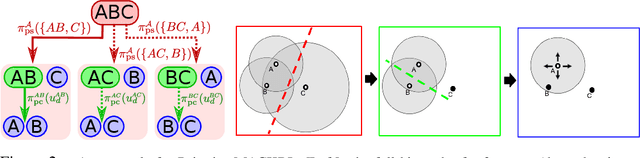
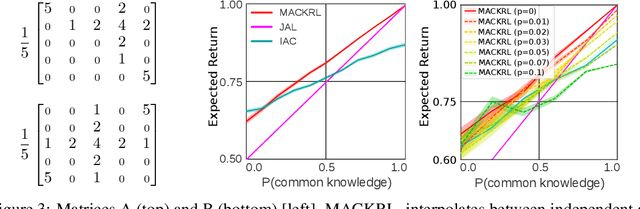
In multi-agent reinforcement learning, centralised policies can only be executed if agents have access to either the global state or an instantaneous communication channel. An alternative approach that circumvents this limitation is to use centralised training of a set of decentralised policies. However, such policies severely limit the agents' ability to coordinate. We propose multi-agent common knowledge reinforcement learning (MACKRL), which strikes a middle ground between these two extremes. Our approach is based on the insight that, even in partially observable settings, subsets of agents often have some common knowledge that they can exploit to coordinate their behaviour. Common knowledge can arise, e.g., if all agents can reliably observe things in their own field of view and know the field of view of other agents. Using this additional information, it is possible to find a centralised policy that conditions only on agents' common knowledge and that can be executed in a decentralised fashion. A resulting challenge is then to determine at what level agents should coordinate. While the common knowledge shared among all agents may not contain much valuable information, there may be subgroups of agents that share common knowledge useful for coordination. MACKRL addresses this challenge using a hierarchical approach: at each level, a controller can either select a joint action for the agents in a given subgroup, or propose a partition of the agents into smaller subgroups whose actions are then selected by controllers at the next level. While action selection involves sampling hierarchically, learning updates are based on the probability of the joint action, calculated by marginalising across the possible decisions of the hierarchy. We show promising results on both a proof-of-concept matrix game and a multi-agent version of StarCraft II Micromanagement.