 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Supervised Auxiliary Loss for Deep RL in Partially Observable Settings
Paper and Code
Apr 17, 2021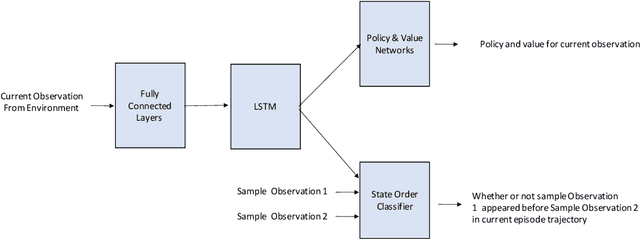


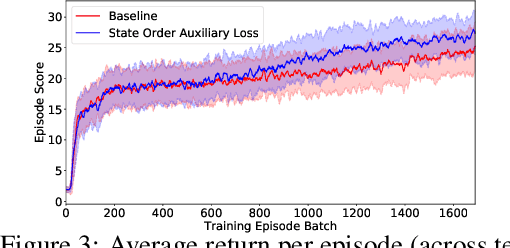
In this work we explore an auxiliary loss useful for reinforcement learning in environments where strong performing agents are required to be able to navigate a spatial environment. The auxiliary loss proposed is to minimize the classification error of a neural network classifier that predicts whether or not a pair of states sampled from the agents current episode trajectory are in order. The classifier takes as input a pair of states as well as the agent's memory. The motivation for this auxiliary loss is that there is a strong correlation with which of a pair of states is more recent in the agents episode trajectory and which of the two states is spatially closer to the agent. Our hypothesis is that learning features to answer this question encourages the agent to learn and internalize in memory representations of states that facilitate spatial reasoning. We tested this auxiliary loss on a navigation task in a gridworld and achieved 9.6% increase in accumulative episode reward compared to a strong baseline approach.