 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial-View Object View Synthesis via Filtered Inversion
Paper and Code
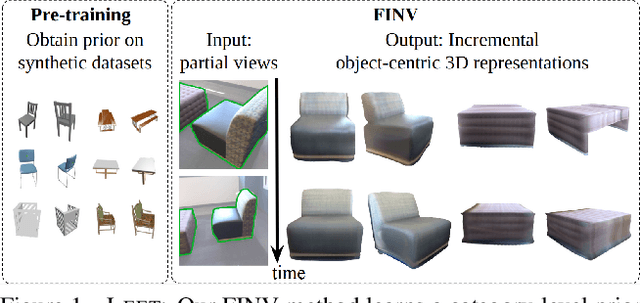
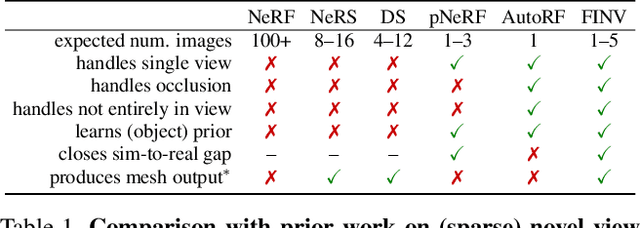
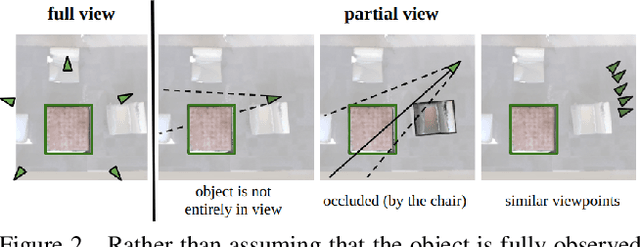
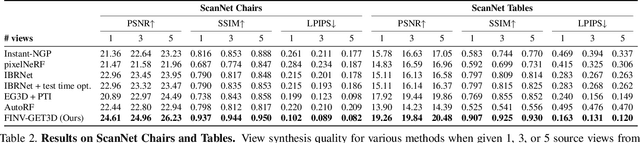
We propose Filtering Inversion (FINV), a learning framework and optimization process that predicts a renderable 3D object representation from one or few partial views. FINV addresses the challenge of synthesizing novel views of objects from partial observations, spanning cases where the object is not entirely in view, is partially occluded, or is only observed from similar views. To achieve this, FINV learns shape priors by training a 3D generative model. At inference, given one or more views of a novel real-world object, FINV first finds a set of latent codes for the object by inverting the generative model from multiple initial seeds. Maintaining the set of latent codes, FINV filters and resamples them after receiving each new observation, akin to particle filtering. The generator is then finetuned for each latent code on the available views in order to adapt to novel objects. We show that FINV successfully synthesizes novel views of real-world objects (e.g., chairs, tables, and cars), even if the generative prior is trained only on synthetic objects. The ability to address the sim-to-real problem allows FINV to be used for object categories without real-world datasets. FINV achieves state-of-the-art performance on multiple real-world datasets, recovers object shape and texture from partial and sparse views, is robust to occlusion, and is able to incrementally improve its representation with more observations.