 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRD: Adapting Differentiable Driving Policies to Distribution Shifts
Paper and Code
Oct 15, 2024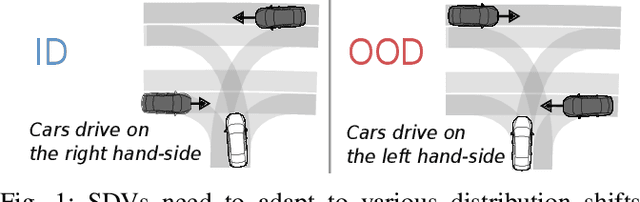
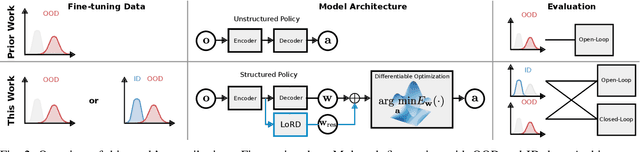

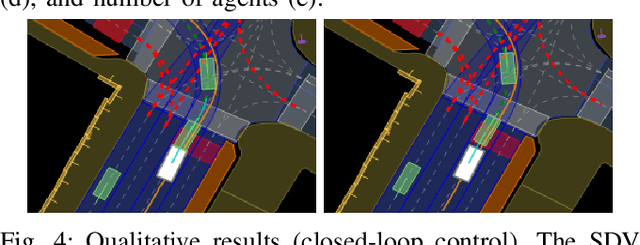
Distribution shifts between operational domains can severely affect the performance of learned models in self-driving vehicles (SDVs). While this is a well-established problem, prior work has mostly explored naive solutions such as fine-tuning, focusing on the motion prediction task. In this work, we explore novel adaptation strategies for differentiable autonomy stacks consisting of prediction, planning, and control, perform evaluation in closed-loop, and investigate the often-overlooked issue of catastrophic forgetting. Specifically, we introduce two simple yet effective techniques: a low-rank residual decoder (LoRD) and multi-task fine-tuning. Through experiments across three models conducted on two real-world autonomous driving datasets (nuPlan, exiD), we demonstrate the effectiveness of our methods and highlight a significant performance gap between open-loop and closed-loop evaluation in prior approaches. Our approach improves forgetting by up to 23.33% and the closed-loop OOD driving score by 8.83% in comparison to standard fine-tuning.