 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM-Guided Experience Replay
Feb 02, 2026Recent advances in Large Language Models (LLMs) and Vision-Language Models (VLMs) have enabled powerful semantic and multimodal reasoning capabilities, creating new opportunities to enhance sample efficiency, high-level planning, and interpretability in reinforcement learning (RL). While prior work has integrated LLMs and VLMs into various components of RL, the replay buffer, a core component for storing and reusing experiences, remains unexplored. We propose addressing this gap by leveraging VLMs to guide the prioritization of experiences in the replay buffer. Our key idea is to use a frozen, pre-trained VLM (requiring no fine-tuning) as an automated evaluator to identify and prioritize promising sub-trajectories from the agent's experiences. Across scenarios, including game-playing and robotics, spanning both discrete and continuous domains, agents trained with our proposed prioritization method achieve 11-52% higher average success rates and improve sample efficiency by 19-45% compared to previous approaches. https://esharony.me/projects/vlm-rb/
Learning Multiple Initial Solutions to Optimization Problems
Nov 04, 2024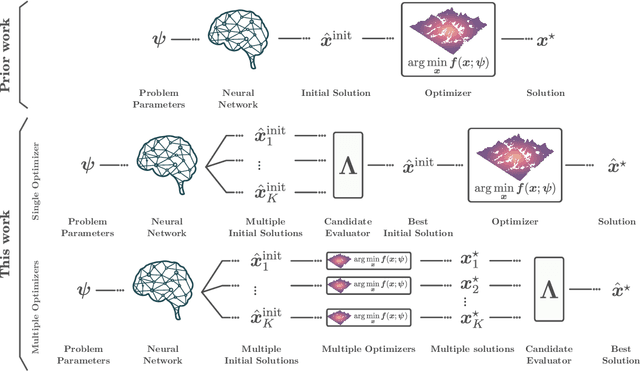
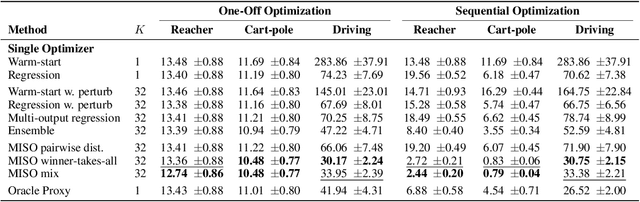
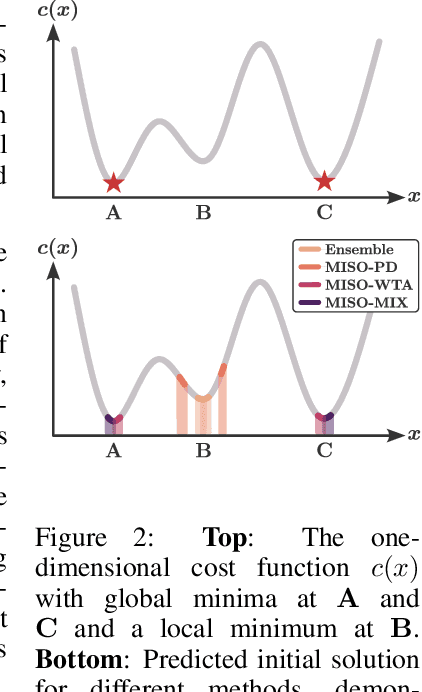

Sequentially solving similar optimization problems under strict runtime constraints is essential for many applications, such as robot control, autonomous driving, and portfolio management. The performance of local optimization methods in these settings is sensitive to the initial solution: poor initialization can lead to slow convergence or suboptimal solutions. To address this challenge, we propose learning to predict \emph{multiple} diverse initial solutions given parameters that define the problem instance. We introduce two strategies for utilizing multiple initial solutions: (i) a single-optimizer approach, where the most promising initial solution is chosen using a selection function, and (ii) a multiple-optimizers approach, where several optimizers, potentially run in parallel, are each initialized with a different solution, with the best solution chosen afterward. We validate our method on three optimal control benchmark tasks: cart-pole, reacher, and autonomous driving, using different optimizers: DDP, MPPI, and iLQR. We find significant and consistent improvement with our method across all evaluation settings and demonstrate that it efficiently scales with the number of initial solutions required. The code is available at $\href{https://github.com/EladSharony/miso}{\tt{https://github.com/EladSharony/miso}}$.