 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment to Focus: Guiding Latent Action Models in the Presence of Distractors
Feb 02, 2026Latent Action Models (LAMs) learn to extract action-relevant representations solely from raw observations, enabling reinforcement learning from unlabelled videos and significantly scaling available training data. However, LAMs face a critical challenge in disentangling action-relevant features from action-correlated noise (e.g., background motion). Failing to filter these distractors causes LAMs to capture spurious correlations and build sub-optimal latent action spaces. In this paper, we introduce MaskLAM -- a lightweight modification to LAM training to mitigate this issue by incorporating visual agent segmentation. MaskLAM utilises segmentation masks from pretrained foundation models to weight the LAM reconstruction loss, thereby prioritising salient information over background elements while requiring no architectural modifications. We demonstrate the effectiveness of our method on continuous-control MuJoCo tasks, modified with action-correlated background noise. Our approach yields up to a 4x increase in accrued rewards compared to standard baselines and a 3x improvement in the latent action quality, as evidenced by linear probe evaluation.
An Optimisation Framework for Unsupervised Environment Design
May 27, 2025For reinforcement learning agents to be deployed in high-risk settings, they must achieve a high level of robustness to unfamiliar scenarios. One method for improving robustness is unsupervised environment design (UED), a suite of methods aiming to maximise an agent's generalisability across configurations of an environment. In this work, we study UED from an optimisation perspective, providing stronger theoretical guarantees for practical settings than prior work. Whereas previous methods relied on guarantees if they reach convergence, our framework employs a nonconvex-strongly-concave objective for which we provide a provably convergent algorithm in the zero-sum setting. We empirically verify the efficacy of our method, outperforming prior methods in a number of environments with varying difficulties.
Adam on Local Time: Addressing Nonstationarity in RL with Relative Adam Timesteps
Dec 22, 2024In reinforcement learning (RL), it is common to apply techniques used broadly in machine learning such as neural network function approximators and momentum-based optimizers. However, such tools were largely developed for supervised learning rather than nonstationary RL, leading practitioners to adopt target networks, clipped policy updates, and other RL-specific implementation tricks to combat this mismatch, rather than directly adapting this toolchain for use in RL. In this paper, we take a different approach and instead address the effect of nonstationarity by adapting the widely used Adam optimiser. We first analyse the impact of nonstationary gradient magnitude -- such as that caused by a change in target network -- on Adam's update size, demonstrating that such a change can lead to large updates and hence sub-optimal performance. To address this, we introduce Adam-Rel. Rather than using the global timestep in the Adam update, Adam-Rel uses the local timestep within an epoch, essentially resetting Adam's timestep to 0 after target changes. We demonstrate that this avoids large updates and reduces to learning rate annealing in the absence of such increases in gradient magnitude. Evaluating Adam-Rel in both on-policy and off-policy RL, we demonstrate improved performance in both Atari and Craftax. We then show that increases in gradient norm occur in RL in practice, and examine the differences between our theoretical model and the observed data.
Multi-Modal Fusion by Meta-Initialization
Oct 10, 2022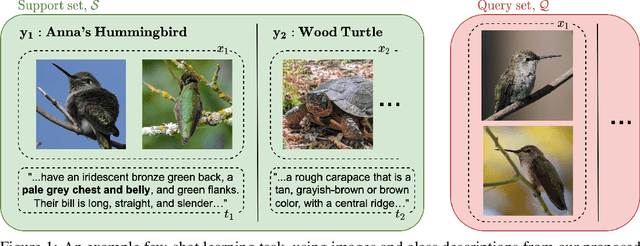
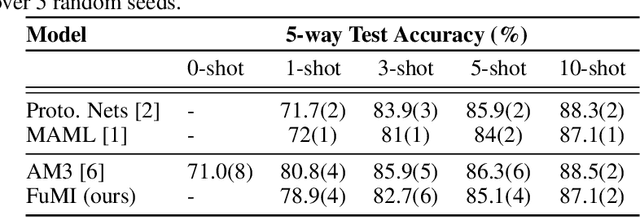
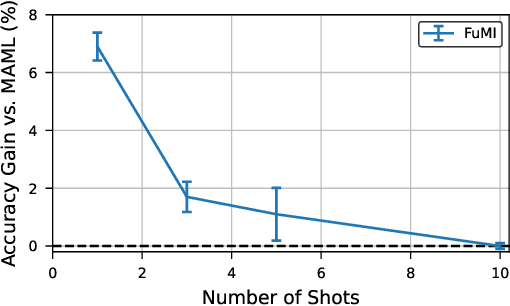
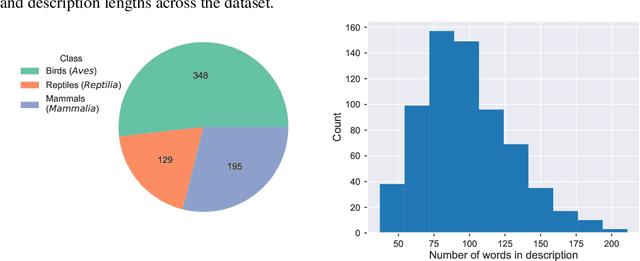
When experience is scarce, models may have insufficient information to adapt to a new task. In this case, auxiliary information - such as a textual description of the task - can enable improved task inference and adaptation. In this work, we propose an extension to the Model-Agnostic Meta-Learning algorithm (MAML), which allows the model to adapt using auxiliary information as well as task experience. Our method, Fusion by Meta-Initialization (FuMI), conditions the model initialization on auxiliary information using a hypernetwork, rather than learning a single, task-agnostic initialization. Furthermore, motivated by the shortcomings of existing multi-modal few-shot learning benchmarks, we constructed iNat-Anim - a large-scale image classification dataset with succinct and visually pertinent textual class descriptions. On iNat-Anim, FuMI significantly outperforms uni-modal baselines such as MAML in the few-shot regime. The code for this project and a dataset exploration tool for iNat-Anim are publicly available at https://github.com/s-a-malik/multi-few .