 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing the Distribution of Performance for Studying Statistical NLP Systems and Corpora
Jun 20, 2001



Statistical NLP systems are frequently evaluated and compared on the basis of their performances on a single split of training and test data. Results obtained using a single split are, however, subject to sampling noise. In this paper we argue in favour of reporting a distribution of performance figures, obtained by resampling the training data, rather than a single number. The additional information from distributions can be used to make statistically quantified statements about differences across parameter settings, systems, and corpora.
Applying System Combination to Base Noun Phrase Identification
Aug 17, 2000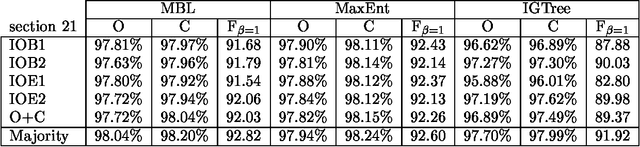
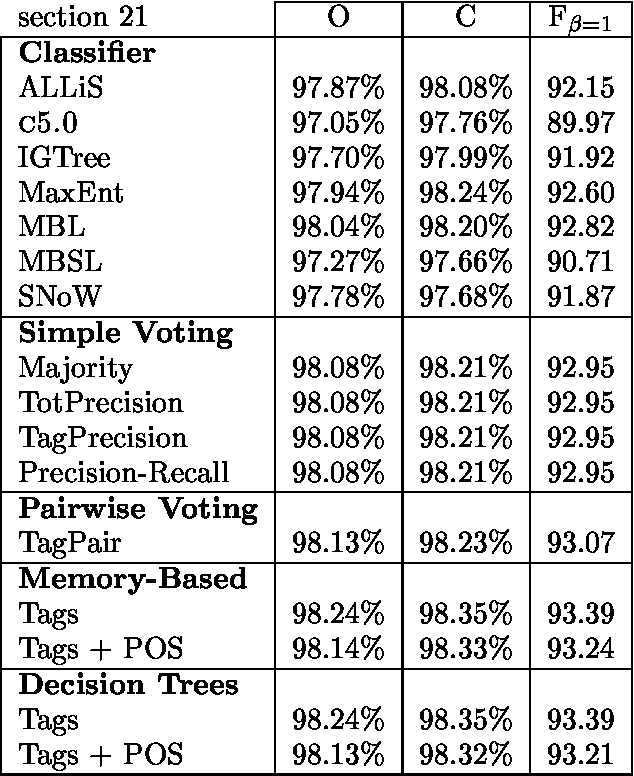

We use seven machine learning algorithms for one task: identifying base noun phrases. The results have been processed by different system combination methods and all of these outperformed the best individual result. We have applied the seven learners with the best combinator, a majority vote of the top five systems, to a standard data set and managed to improve the best published result for this data set.
* 7 pages
A Memory-Based Approach to Learning Shallow Natural Language Patterns
Apr 15, 1999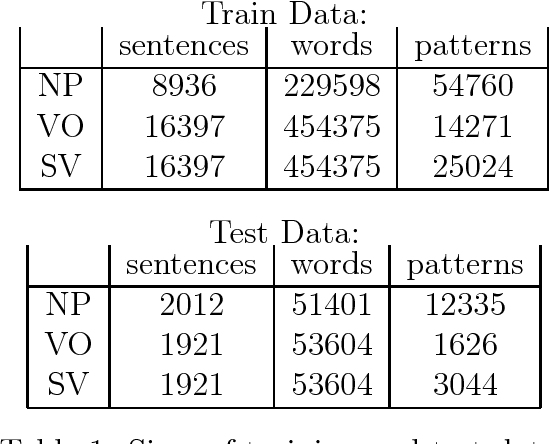
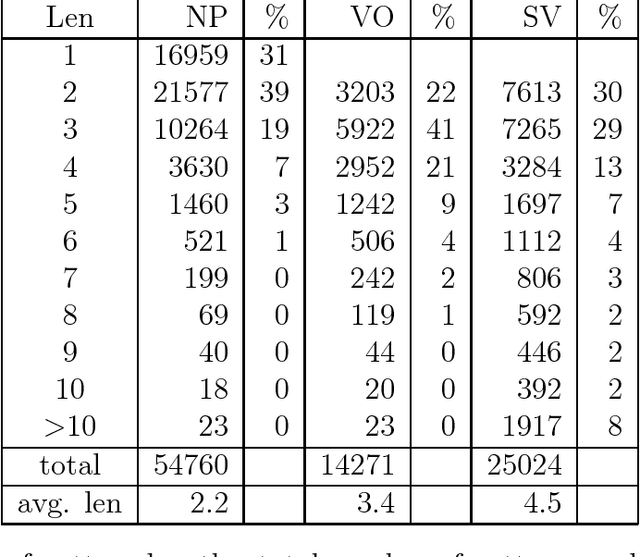
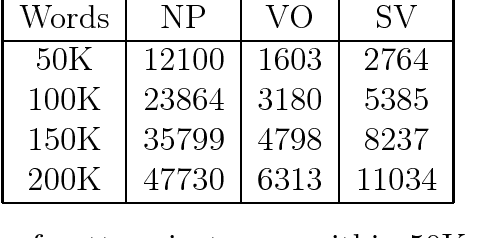
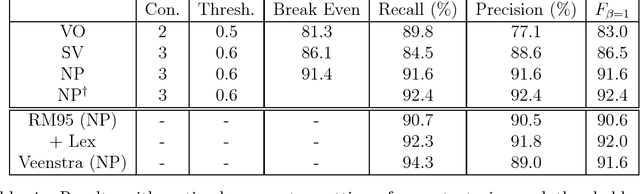
Recognizing shallow linguistic patterns, such as basic syntactic relationships between words, is a common task in applied natural language and text processing. The common practice for approaching this task is by tedious manual definition of possible pattern structures, often in the form of regular expressions or finite automata. This paper presents a novel memory-based learning method that recognizes shallow patterns in new text based on a bracketed training corpus. The training data are stored as-is, in efficient suffix-tree data structures. Generalization is performed on-line at recognition time by comparing subsequences of the new text to positive and negative evidence in the corpus. This way, no information in the training is lost, as can happen in other learning systems that construct a single generalized model at the time of training. The paper presents experimental results for recognizing noun phrase, subject-verb and verb-object patterns in English. Since the learning approach enables easy porting to new domains, we plan to apply it to syntactic patterns in other languages and to sub-language patterns for information extraction.