Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing the Distribution of Performance for Studying Statistical NLP Systems and Corpora
Paper and Code
Jun 20, 2001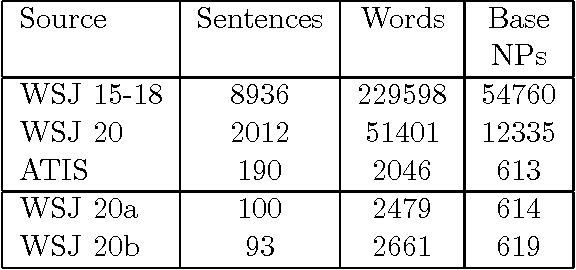



Statistical NLP systems are frequently evaluated and compared on the basis of their performances on a single split of training and test data. Results obtained using a single split are, however, subject to sampling noise. In this paper we argue in favour of reporting a distribution of performance figures, obtained by resampling the training data, rather than a single number. The additional information from distributions can be used to make statistically quantified statements about differences across parameter settings, systems, and corpora.
* To be presented in ACL/EACL Workshop on Evaluation for Language and
Dialogue Systems
View paper on