 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised Contextualization of Knowledge Graph Facts
Jul 08, 2018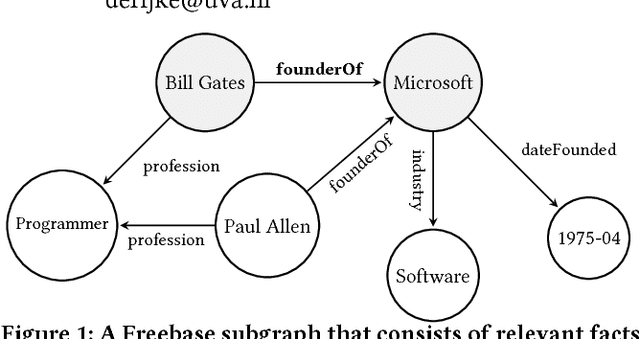
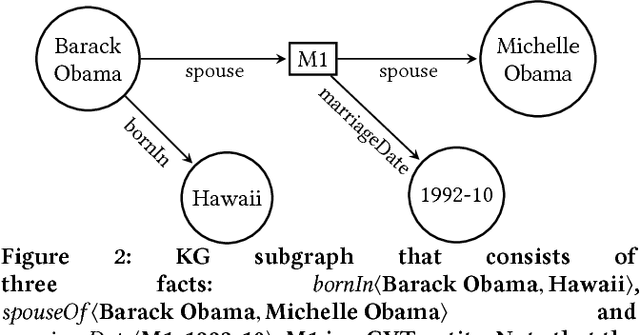
Knowledge graphs (KGs) model facts about the world, they consist of nodes (entities such as companies and people) that are connected by edges (relations such as founderOf). Facts encoded in KGs are frequently used by search applications to augment result pages. When presenting a KG fact to the user, providing other facts that are pertinent to that main fact can enrich the user experience and support exploratory information needs. KG fact contextualization is the task of augmenting a given KG fact with additional and useful KG facts. The task is challenging because of the large size of KGs, discovering other relevant facts even in a small neighborhood of the given fact results in an enormous amount of candidates. We introduce a neural fact contextualization method (NFCM) to address the KG fact contextualization task. NFCM first generates a set of candidate facts in the neighborhood of a given fact and then ranks the candidate facts using a supervised learning to rank model. The ranking model combines features that we automatically learn from data and that represent the query-candidate facts with a set of hand-crafted features we devised or adjusted for this task. In order to obtain the annotations required to train the learning to rank model at scale, we generate training data automatically using distant supervision on a large entity-tagged text corpus. We show that ranking functions learned on this data are effective at contextualizing KG facts. Evaluation using human assessors shows that it significantly outperforms several competitive baselines.
I Wish I Didn't Say That! Analyzing and Predicting Deleted Messages in Twitter
May 14, 2013


Twitter has become a major source of data for social media researchers. One important aspect of Twitter not previously considered are {\em deletions} -- removal of tweets from the stream. Deletions can be due to a multitude of reasons such as privacy concerns, rashness or attempts to undo public statements. We show how deletions can be automatically predicted ahead of time and analyse which tweets are likely to be deleted and how.
Learning Computational Grammars
Jul 15, 2001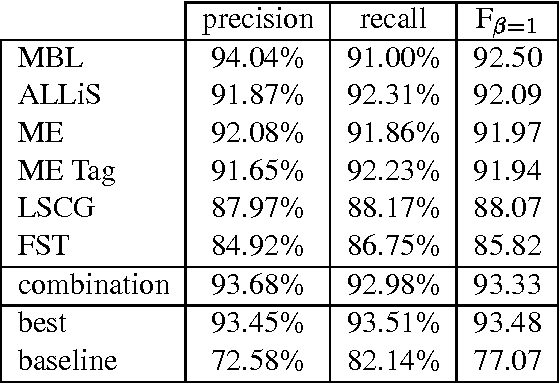
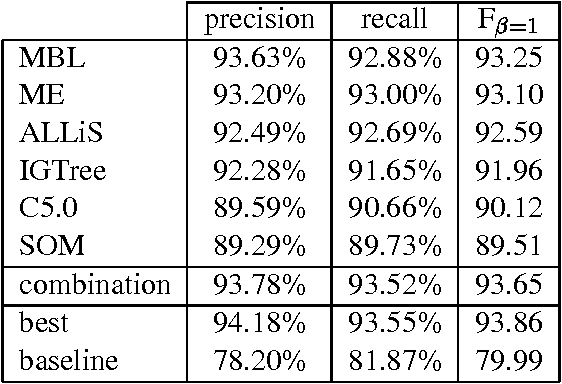
This paper reports on the "Learning Computational Grammars" (LCG) project, a postdoc network devoted to studying the application of machine learning techniques to grammars suitable for computational use. We were interested in a more systematic survey to understand the relevance of many factors to the success of learning, esp. the availability of annotated data, the kind of dependencies in the data, and the availability of knowledge bases (grammars). We focused on syntax, esp. noun phrase (NP) syntax.
Estimation of Stochastic Attribute-Value Grammars using an Informative Sample
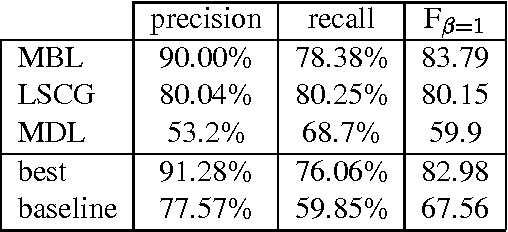
Aug 23, 2000

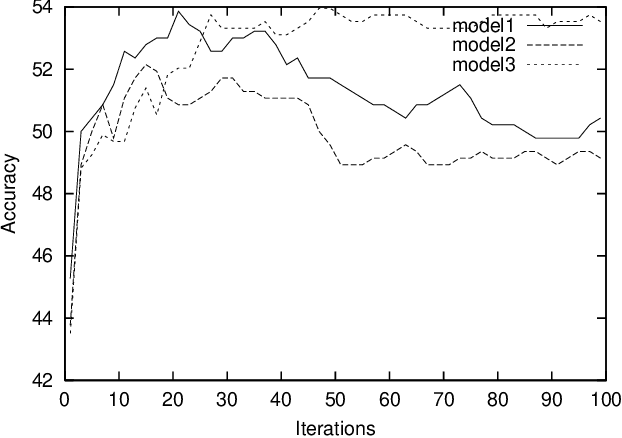

We argue that some of the computational complexity associated with estimation of stochastic attribute-value grammars can be reduced by training upon an informative subset of the full training set. Results using the parsed Wall Street Journal corpus show that in some circumstances, it is possible to obtain better estimation results using an informative sample than when training upon all the available material. Further experimentation demonstrates that with unlexicalised models, a Gaussian Prior can reduce overfitting. However, when models are lexicalised and contain overlapping features, overfitting does not seem to be a problem, and a Gaussian Prior makes minimal difference to performance. Our approach is applicable for situations when there are an infeasibly large number of parses in the training set, or else for when recovery of these parses from a packed representation is itself computationally expensive.
* 6 pages, 2 figures. Coling 2000, Saarbr\"{u}cken, Germany. pp 586--592
Learning Unification-Based Natural Language Grammars
Feb 03, 1995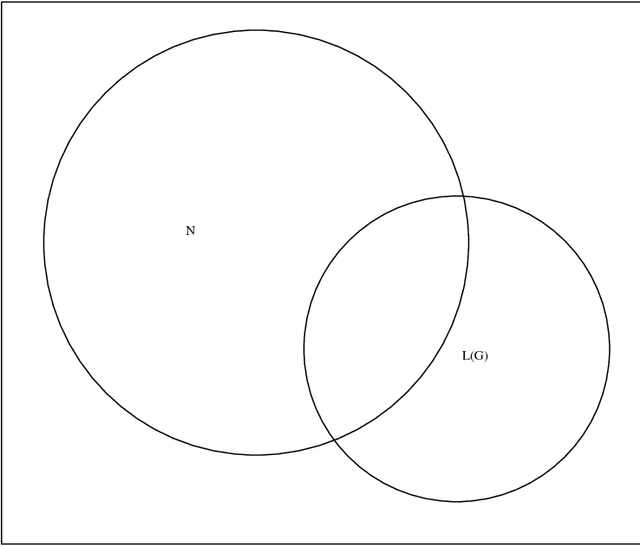
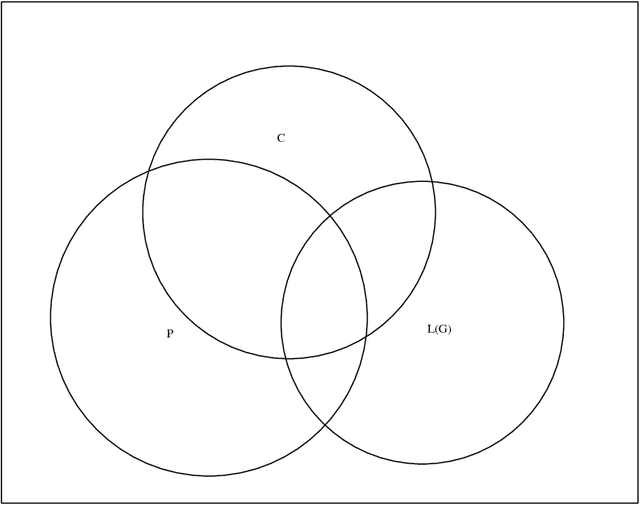
When parsing unrestricted language, wide-covering grammars often undergenerate. Undergeneration can be tackled either by sentence correction, or by grammar correction. This thesis concentrates upon automatic grammar correction (or machine learning of grammar) as a solution to the problem of undergeneration. Broadly speaking, grammar correction approaches can be classified as being either {\it data-driven}, or {\it model-based}. Data-driven learners use data-intensive methods to acquire grammar. They typically use grammar formalisms unsuited to the needs of practical text processing and cannot guarantee that the resulting grammar is adequate for subsequent semantic interpretation. That is, data-driven learners acquire grammars that generate strings that humans would judge to be grammatically ill-formed (they {\it overgenerate}) and fail to assign linguistically plausible parses. Model-based learners are knowledge-intensive and are reliant for success upon the completeness of a {\it model of grammaticality}. But in practice, the model will be incomplete. Given that in this thesis we deal with undergeneration by learning, we hypothesise that the combined use of data-driven and model-based learning would allow data-driven learning to compensate for model-based learning's incompleteness, whilst model-based learning would compensate for data-driven learning's unsoundness. We describe a system that we have used to test the hypothesis empirically. The system combines data-driven and model-based learning to acquire unification-based grammars that are more suitable for practical text parsing. Using the Spoken English Corpus as data, and by quantitatively measuring undergeneration, overgeneration and parse plausibility, we show that this hypothesis is correct.
Learning unification-based grammars using the Spoken English Corpus
Jun 28, 1994This paper describes a grammar learning system that combines model-based and data-driven learning within a single framework. Our results from learning grammars using the Spoken English Corpus (SEC) suggest that combined model-based and data-driven learning can produce a more plausible grammar than is the case when using either learning style isolation.
* 10 pages