 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiSee: Advancing Multi-Shot Explainable AI Using Case-based Recommendations
Aug 23, 2024



Explainable AI (XAI) can greatly enhance user trust and satisfaction in AI-assisted decision-making processes. Recent findings suggest that a single explainer may not meet the diverse needs of multiple users in an AI system; indeed, even individual users may require multiple explanations. This highlights the necessity for a "multi-shot" approach, employing a combination of explainers to form what we introduce as an "explanation strategy". Tailored to a specific user or a user group, an "explanation experience" describes interactions with personalised strategies designed to enhance their AI decision-making processes. The iSee platform is designed for the intelligent sharing and reuse of explanation experiences, using Case-based Reasoning to advance best practices in XAI. The platform provides tools that enable AI system designers, i.e. design users, to design and iteratively revise the most suitable explanation strategy for their AI system to satisfy end-user needs. All knowledge generated within the iSee platform is formalised by the iSee ontology for interoperability. We use a summative mixed methods study protocol to evaluate the usability and utility of the iSee platform with six design users across varying levels of AI and XAI expertise. Our findings confirm that the iSee platform effectively generalises across applications and its potential to promote the adoption of XAI best practices.
XEQ Scale for Evaluating XAI Experience Quality Grounded in Psychometric Theory
Jul 15, 2024Explainable Artificial Intelligence (XAI) aims to improve the transparency of autonomous decision-making through explanations. Recent literature has emphasised users' need for holistic "multi-shot" explanations and the ability to personalise their engagement with XAI systems. We refer to this user-centred interaction as an XAI Experience. Despite advances in creating XAI experiences, evaluating them in a user-centred manner has remained challenging. To address this, we introduce the XAI Experience Quality (XEQ) Scale (pronounced "Seek" Scale), for evaluating the user-centred quality of XAI experiences. Furthermore, XEQ quantifies the quality of experiences across four evaluation dimensions: learning, utility, fulfilment and engagement. These contributions extend the state-of-the-art of XAI evaluation, moving beyond the one-dimensional metrics frequently developed to assess single-shot explanations. In this paper, we present the XEQ scale development and validation process, including content validation with XAI experts as well as discriminant and construct validation through a large-scale pilot study. Out pilot study results offer strong evidence that establishes the XEQ Scale as a comprehensive framework for evaluating user-centred XAI experiences.
Supplier Recommendation in Online Procurement
Mar 02, 2024Supply chain optimization is key to a healthy and profitable business. Many companies use online procurement systems to agree contracts with suppliers. It is vital that the most competitive suppliers are invited to bid for such contracts. In this work, we propose a recommender system to assist with supplier discovery in road freight online procurement. Our system is able to provide personalized supplier recommendations, taking into account customer needs and preferences. This is a novel application of recommender systems, calling for design choices that fit the unique requirements of online procurement. Our preliminary results, using real-world data, are promising.
Enhancing Recommendation Diversity by Re-ranking with Large Language Models
Jan 21, 2024
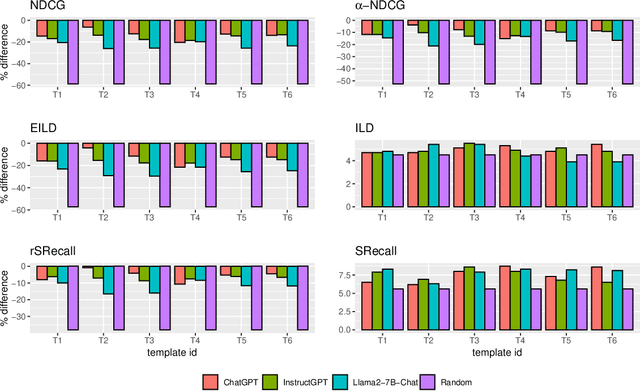


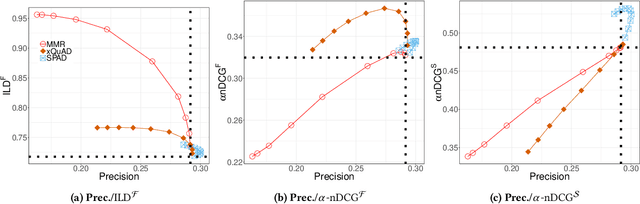
It has long been recognized that it is not enough for a Recommender System (RS) to provide recommendations based only on their relevance to users. Among many other criteria, the set of recommendations may need to be diverse in order to handle uncertainty and offer a meaningful choice. The literature reports many ways of measuring diversity and ways of improving the diversity of a set of recommendations, most notably by re-ranking and selecting from a larger set of candidate recommendations. Driven by promising insights from the literature on how to incorporate versatile Large Language Models (LLMs) into the RS pipeline, in this paper, we show how LLMs can be used for diversity re-ranking. We begin with an informal study that verifies that LLMs can be used for re-ranking tasks and do have some understanding of the concept of diversity. Then, we design a more rigorous methodology where LLMs are prompted to generate a diverse ranking from a candidate ranking using various prompt templates with different re-ranking instructions in a zero-shot fashion. We conduct comprehensive experiments testing state-of-the-art conversational LLMs from the GPT and Llama families. We compare their re-ranking capabilities with random re-ranking and various traditional re-ranking methods from the literature (MMR, xQuAD and RxQuAD). We find that LLM-based re-ranking outperforms random re-ranking across all the metrics that we use but does not perform as well as the traditional re-ranking methods. We gain insight into prompt design for this task (e.g.\ on the whole, it is better to prompt for diversity rather than a balance of diversity and relevance). Given that no special knowledge engineering is needed, we conclude that LLM-based re-ranking is a promising approach, and we highlight directions for future research. We open-source the code of our experiments for reproducibility.
A User-Centered Investigation of Personal Music Tours
Aug 16, 2022
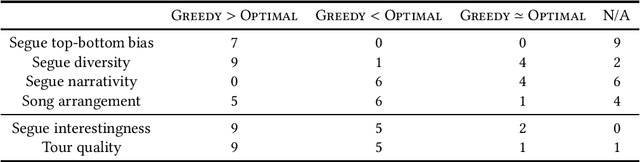
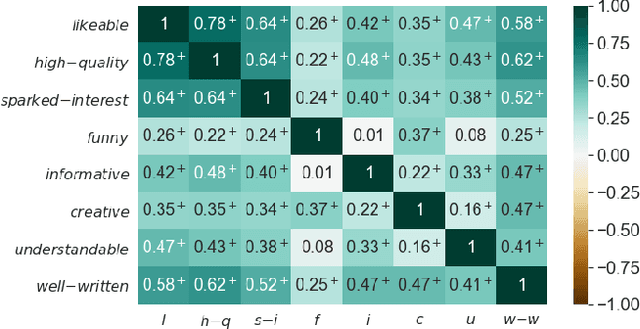
Streaming services use recommender systems to surface the right music to users. Playlists are a popular way to present music in a list-like fashion, ie as a plain list of songs. An alternative are tours, where the songs alternate segues, which explain the connections between consecutive songs. Tours address the user need of seeking background information about songs, and are found to be superior to playlists, given the right user context. In this work, we provide, for the first time, a user-centered evaluation of two tour-generation algorithms (Greedy and Optimal) using semi-structured interviews. We assess the algorithms, we discuss attributes of the tours that the algorithms produce, we identify which attributes are desirable and which are not, and we enumerate several possible improvements to the algorithms, along with practical suggestions on how to implement the improvements. Our main findings are that Greedy generates more likeable tours than Optimal, and that three important attributes of tours are segue diversity, song arrangement and song familiarity. More generally, we provide insights into how to present music to users, which could inform the design of user-centered recommender systems.
An Interpretable Music Similarity Measure Based on Path Interestingness
Aug 04, 2021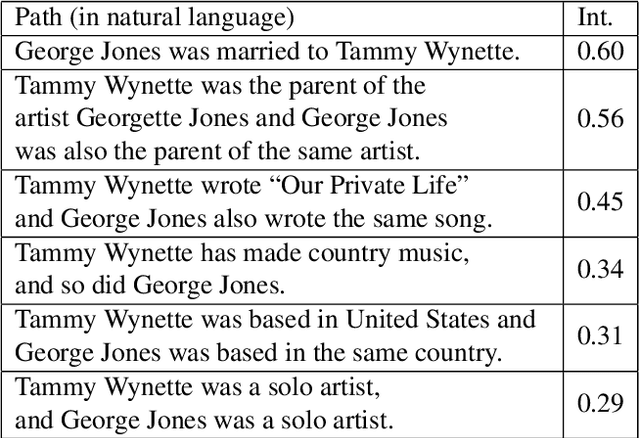

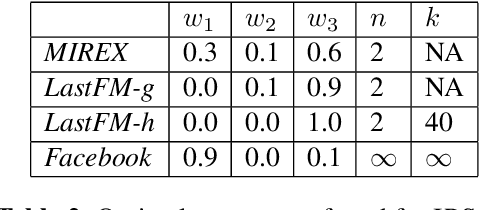
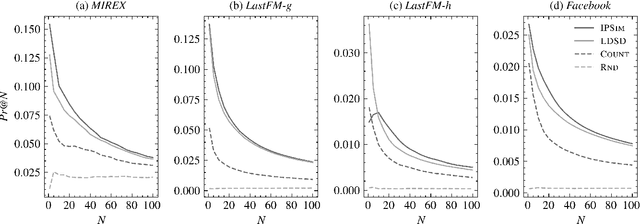
We introduce a novel and interpretable path-based music similarity measure. Our similarity measure assumes that items, such as songs and artists, and information about those items are represented in a knowledge graph. We find paths in the graph between a seed and a target item; we score those paths based on their interestingness; and we aggregate those scores to determine the similarity between the seed and the target. A distinguishing feature of our similarity measure is its interpretability. In particular, we can translate the most interesting paths into natural language, so that the causes of the similarity judgements can be readily understood by humans. We compare the accuracy of our similarity measure with other competitive path-based similarity baselines in two experimental settings and with four datasets. The results highlight the validity of our approach to music similarity, and demonstrate that path interestingness scores can be the basis of an accurate and interpretable similarity measure.
Generating Interesting Song-to-Song Segues With Dave
May 31, 2021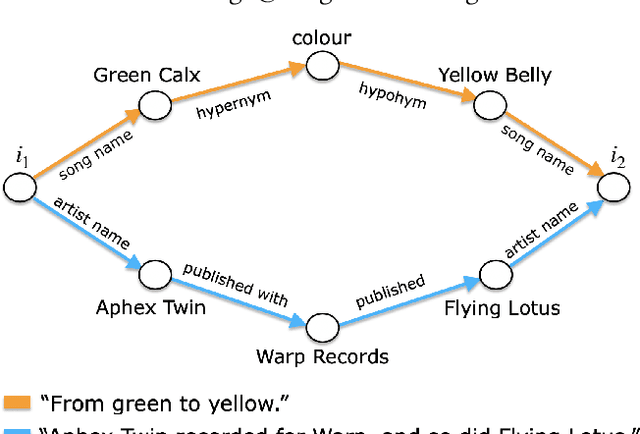


We introduce a novel domain-independent algorithm for generating interesting item-to-item textual connections, or segues. Pivotal to our contribution is the introduction of a scoring function for segues, based on their "interestingness". We provide an implementation of our algorithm in the music domain. We refer to our implementation as Dave. Dave is able to generate 1553 different types of segues, that can be broadly categorized as either informative or funny. We evaluate Dave by comparing it against a curated source of song-to-song segues, called The Chain. In the case of informative segues, we find that Dave can produce segues of the same quality, if not better, than those to be found in The Chain. And, we report positive correlation between the values produced by our scoring function and human perceptions of segue quality. The results highlight the validity of our method, and open future directions in the application of segues to recommender systems research.
Sudden Death: A New Way to Compare Recommendation Diversification
Jul 31, 2019

This paper describes problems with the current way we compare the diversity of different recommendation lists in offline experiments. We illustrate the problems with a case study. We propose the Sudden Death score as a new and better way of making these comparisons.
Denoising Dictionary Learning Against Adversarial Perturbations
Jan 07, 2018

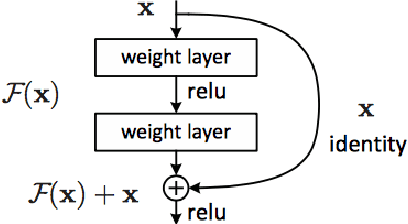

We propose denoising dictionary learning (DDL), a simple yet effective technique as a protection measure against adversarial perturbations. We examined denoising dictionary learning on MNIST and CIFAR10 perturbed under two different perturbation techniques, fast gradient sign (FGSM) and jacobian saliency maps (JSMA). We evaluated it against five different deep neural networks (DNN) representing the building blocks of most recent architectures indicating a successive progression of model complexity of each other. We show that each model tends to capture different representations based on their architecture. For each model we recorded its accuracy both on the perturbed test data previously misclassified with high confidence and on the denoised one after the reconstruction using dictionary learning. The reconstruction quality of each data point is assessed by means of PSNR (Peak Signal to Noise Ratio) and Structure Similarity Index (SSI). We show that after applying (DDL) the reconstruction of the original data point from a noisy
Learning unification-based grammars using the Spoken English Corpus
Jun 28, 1994This paper describes a grammar learning system that combines model-based and data-driven learning within a single framework. Our results from learning grammars using the Spoken English Corpus (SEC) suggest that combined model-based and data-driven learning can produce a more plausible grammar than is the case when using either learning style isolation.
* 10 pages