 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Recommendation Diversity by Re-ranking with Large Language Models
Jan 21, 2024
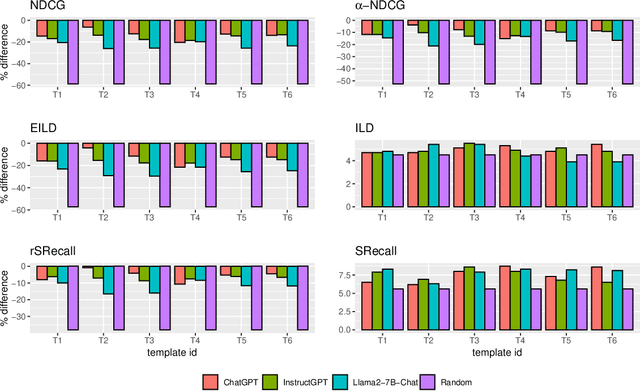


It has long been recognized that it is not enough for a Recommender System (RS) to provide recommendations based only on their relevance to users. Among many other criteria, the set of recommendations may need to be diverse in order to handle uncertainty and offer a meaningful choice. The literature reports many ways of measuring diversity and ways of improving the diversity of a set of recommendations, most notably by re-ranking and selecting from a larger set of candidate recommendations. Driven by promising insights from the literature on how to incorporate versatile Large Language Models (LLMs) into the RS pipeline, in this paper, we show how LLMs can be used for diversity re-ranking. We begin with an informal study that verifies that LLMs can be used for re-ranking tasks and do have some understanding of the concept of diversity. Then, we design a more rigorous methodology where LLMs are prompted to generate a diverse ranking from a candidate ranking using various prompt templates with different re-ranking instructions in a zero-shot fashion. We conduct comprehensive experiments testing state-of-the-art conversational LLMs from the GPT and Llama families. We compare their re-ranking capabilities with random re-ranking and various traditional re-ranking methods from the literature (MMR, xQuAD and RxQuAD). We find that LLM-based re-ranking outperforms random re-ranking across all the metrics that we use but does not perform as well as the traditional re-ranking methods. We gain insight into prompt design for this task (e.g.\ on the whole, it is better to prompt for diversity rather than a balance of diversity and relevance). Given that no special knowledge engineering is needed, we conclude that LLM-based re-ranking is a promising approach, and we highlight directions for future research. We open-source the code of our experiments for reproducibility.