 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA User-Centered Investigation of Personal Music Tours
Aug 16, 2022
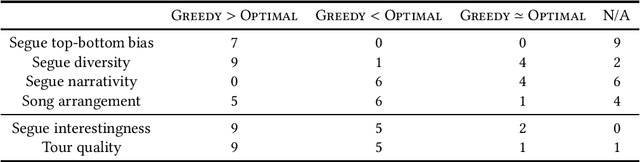
Streaming services use recommender systems to surface the right music to users. Playlists are a popular way to present music in a list-like fashion, ie as a plain list of songs. An alternative are tours, where the songs alternate segues, which explain the connections between consecutive songs. Tours address the user need of seeking background information about songs, and are found to be superior to playlists, given the right user context. In this work, we provide, for the first time, a user-centered evaluation of two tour-generation algorithms (Greedy and Optimal) using semi-structured interviews. We assess the algorithms, we discuss attributes of the tours that the algorithms produce, we identify which attributes are desirable and which are not, and we enumerate several possible improvements to the algorithms, along with practical suggestions on how to implement the improvements. Our main findings are that Greedy generates more likeable tours than Optimal, and that three important attributes of tours are segue diversity, song arrangement and song familiarity. More generally, we provide insights into how to present music to users, which could inform the design of user-centered recommender systems.
An Interpretable Music Similarity Measure Based on Path Interestingness
Aug 04, 2021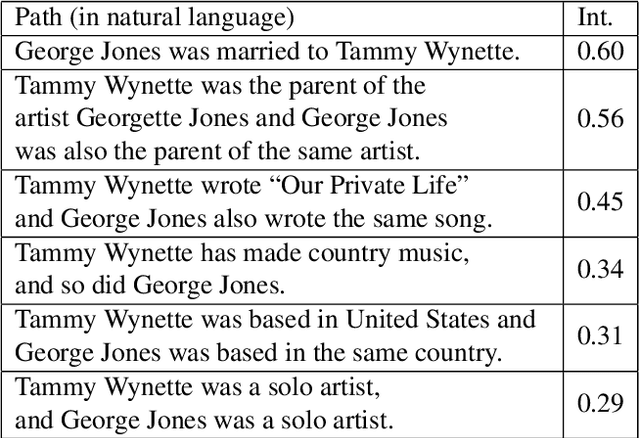

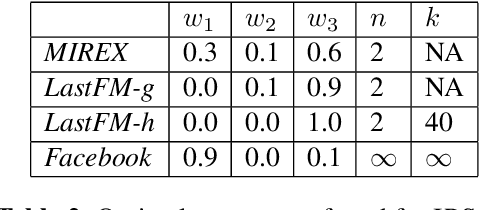
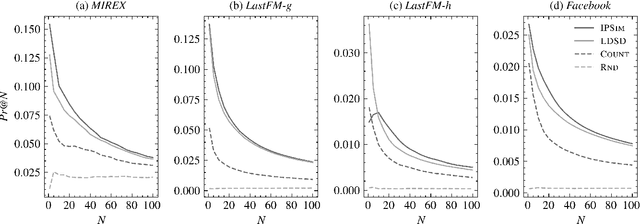
We introduce a novel and interpretable path-based music similarity measure. Our similarity measure assumes that items, such as songs and artists, and information about those items are represented in a knowledge graph. We find paths in the graph between a seed and a target item; we score those paths based on their interestingness; and we aggregate those scores to determine the similarity between the seed and the target. A distinguishing feature of our similarity measure is its interpretability. In particular, we can translate the most interesting paths into natural language, so that the causes of the similarity judgements can be readily understood by humans. We compare the accuracy of our similarity measure with other competitive path-based similarity baselines in two experimental settings and with four datasets. The results highlight the validity of our approach to music similarity, and demonstrate that path interestingness scores can be the basis of an accurate and interpretable similarity measure.
Generating Interesting Song-to-Song Segues With Dave
May 31, 2021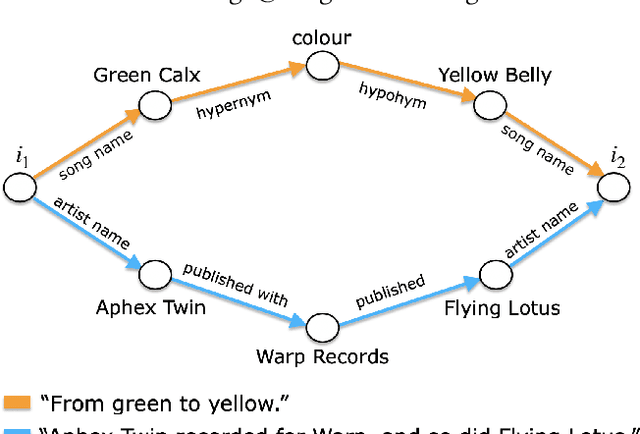

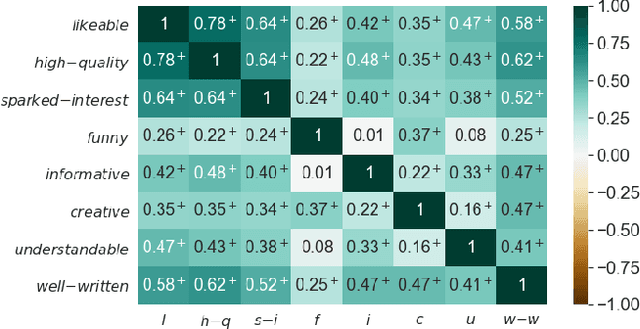

We introduce a novel domain-independent algorithm for generating interesting item-to-item textual connections, or segues. Pivotal to our contribution is the introduction of a scoring function for segues, based on their "interestingness". We provide an implementation of our algorithm in the music domain. We refer to our implementation as Dave. Dave is able to generate 1553 different types of segues, that can be broadly categorized as either informative or funny. We evaluate Dave by comparing it against a curated source of song-to-song segues, called The Chain. In the case of informative segues, we find that Dave can produce segues of the same quality, if not better, than those to be found in The Chain. And, we report positive correlation between the values produced by our scoring function and human perceptions of segue quality. The results highlight the validity of our method, and open future directions in the application of segues to recommender systems research.
On the instability of embeddings for recommender systems: the case of Matrix Factorization
Apr 12, 2021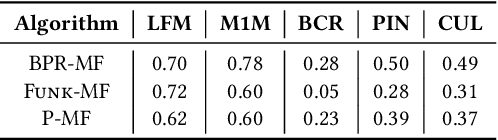
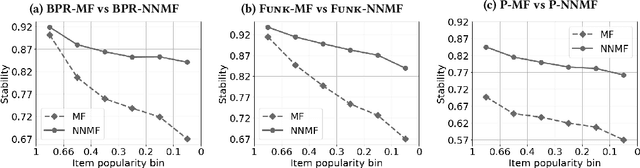
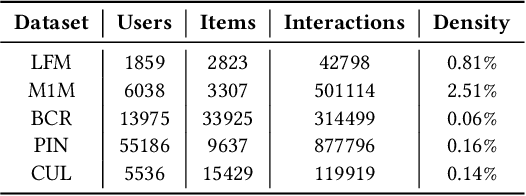
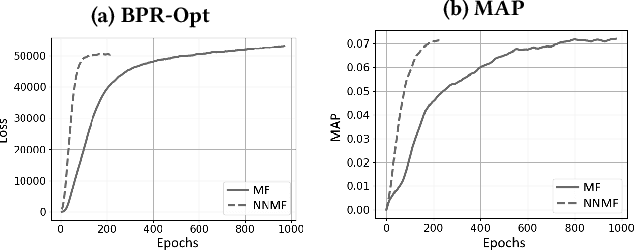
Most state-of-the-art top-N collaborative recommender systems work by learning embeddings to jointly represent users and items. Learned embeddings are considered to be effective to solve a variety of tasks. Among others, providing and explaining recommendations. In this paper we question the reliability of the embeddings learned by Matrix Factorization (MF). We empirically demonstrate that, by simply changing the initial values assigned to the latent factors, the same MF method generates very different embeddings of items and users, and we highlight that this effect is stronger for less popular items. To overcome these drawbacks, we present a generalization of MF, called Nearest Neighbors Matrix Factorization (NNMF). The new method propagates the information about items and users to their neighbors, speeding up the training procedure and extending the amount of information that supports recommendations and representations. We describe the NNMF variants of three common MF approaches, and with extensive experiments on five different datasets we show that they strongly mitigate the instability issues of the original MF versions and they improve the accuracy of recommendations on the long-tail.