 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-stage Ensemble Model for Cross-market Recommendation
Feb 17, 2022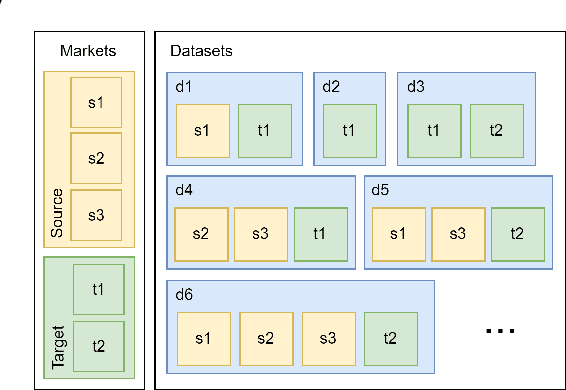
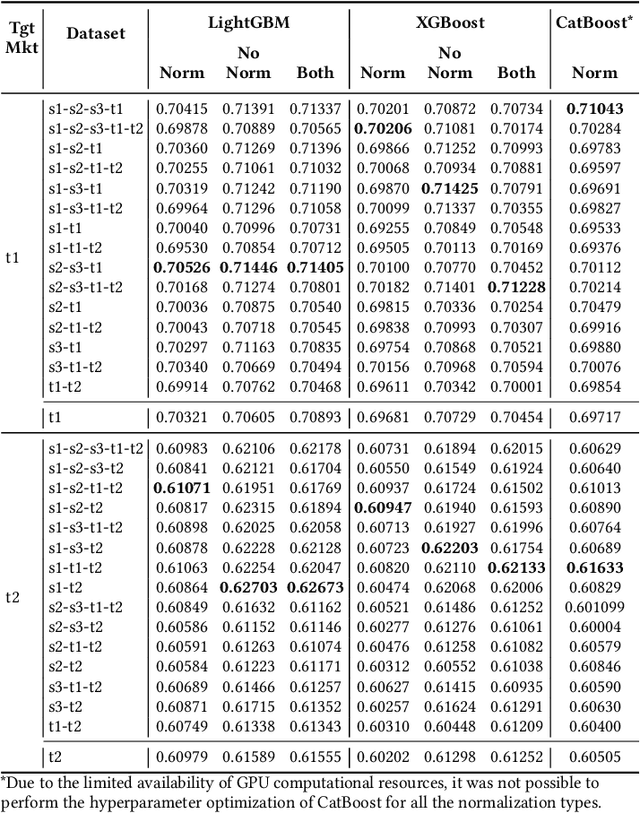
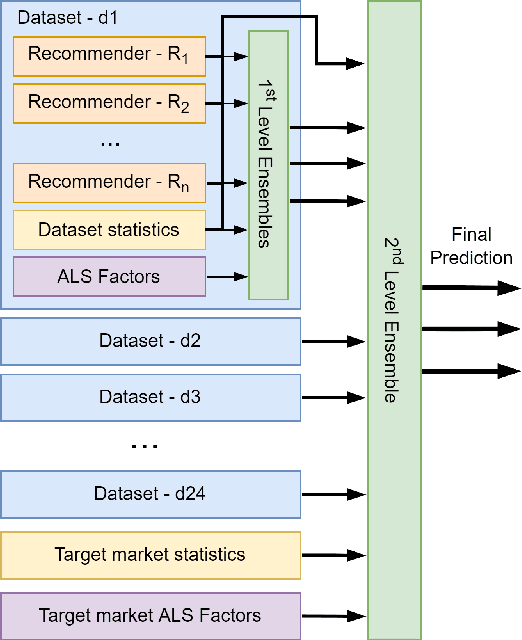

This paper describes the solution of our team PolimiRank for the WSDM Cup 2022 on cross-market recommendation. The goal of the competition is to effectively exploit the information extracted from different markets to improve the ranking accuracy of recommendations on two target markets. Our model consists in a multi-stage approach based on the combination of data belonging to different markets. In the first stage, state-of-the-art recommenders are used to predict scores for user-item couples, which are ensembled in the following 2 stages, employing a simple linear combination and more powerful Gradient Boosting Decision Tree techniques. Our team ranked 4th in the final leaderboard.
On the instability of embeddings for recommender systems: the case of Matrix Factorization
Apr 12, 2021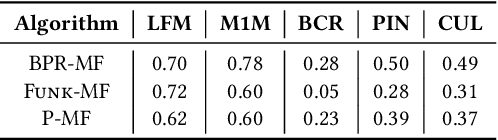
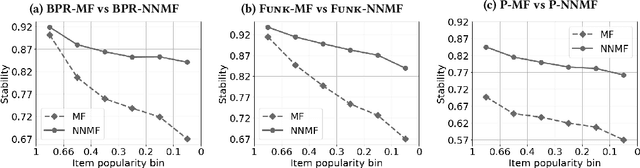
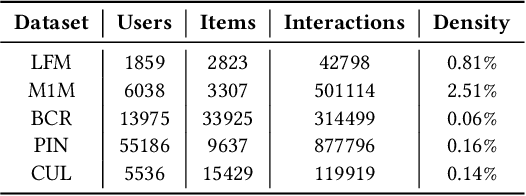
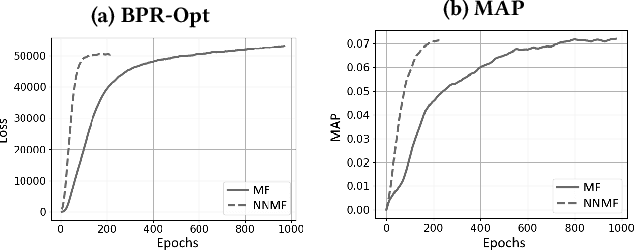
Most state-of-the-art top-N collaborative recommender systems work by learning embeddings to jointly represent users and items. Learned embeddings are considered to be effective to solve a variety of tasks. Among others, providing and explaining recommendations. In this paper we question the reliability of the embeddings learned by Matrix Factorization (MF). We empirically demonstrate that, by simply changing the initial values assigned to the latent factors, the same MF method generates very different embeddings of items and users, and we highlight that this effect is stronger for less popular items. To overcome these drawbacks, we present a generalization of MF, called Nearest Neighbors Matrix Factorization (NNMF). The new method propagates the information about items and users to their neighbors, speeding up the training procedure and extending the amount of information that supports recommendations and representations. We describe the NNMF variants of three common MF approaches, and with extensive experiments on five different datasets we show that they strongly mitigate the instability issues of the original MF versions and they improve the accuracy of recommendations on the long-tail.
A novel graph-based model for hybrid recommendations in cold-start scenarios
Aug 31, 2018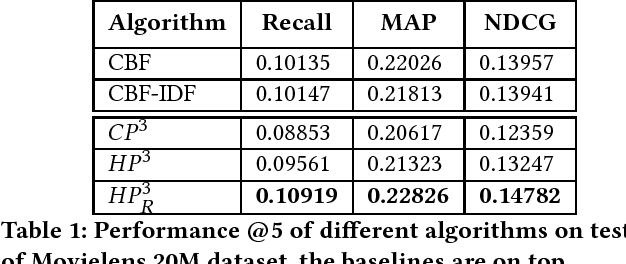
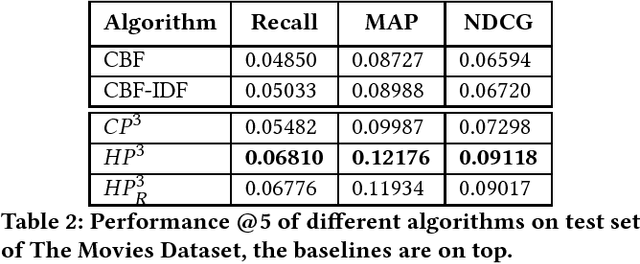
Cold-start is a very common and still open problem in the Recommender Systems literature. Since cold start items do not have any interaction, collaborative algorithms are not applicable. One of the main strategies is to use pure or hybrid content-based approaches, which usually yield to lower recommendation quality than collaborative ones. Some techniques to optimize performance of this type of approaches have been studied in recent past. One of them is called feature weighting, which assigns to every feature a real value, called weight, that estimates its importance. Statistical techniques for feature weighting commonly used in Information Retrieval, like TF-IDF, have been adapted for Recommender Systems, but they often do not provide sufficient quality improvements. More recent approaches, FBSM and LFW, estimate weights by leveraging collaborative information via machine learning, in order to learn the importance of a feature based on other users opinions. This type of models have shown promising results compared to classic statistical analyzes cited previously. We propose a novel graph, feature-based machine learning model to face the cold-start item scenario, learning the relevance of features from probabilities of item-based collaborative filtering algorithms.