 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePitRSDNet: Predicting Intra-operative Remaining Surgery Duration in Endoscopic Pituitary Surgery
Sep 25, 2024



Accurate intra-operative Remaining Surgery Duration (RSD) predictions allow for anaesthetists to more accurately decide when to administer anaesthetic agents and drugs, as well as to notify hospital staff to send in the next patient. Therefore RSD plays an important role in improving patient care and minimising surgical theatre costs via efficient scheduling. In endoscopic pituitary surgery, it is uniquely challenging due to variable workflow sequences with a selection of optional steps contributing to high variability in surgery duration. This paper presents PitRSDNet for predicting RSD during pituitary surgery, a spatio-temporal neural network model that learns from historical data focusing on workflow sequences. PitRSDNet integrates workflow knowledge into RSD prediction in two forms: 1) multi-task learning for concurrently predicting step and RSD; and 2) incorporating prior steps as context in temporal learning and inference. PitRSDNet is trained and evaluated on a new endoscopic pituitary surgery dataset with 88 videos to show competitive performance improvements over previous statistical and machine learning methods. The findings also highlight how PitRSDNet improve RSD precision on outlier cases utilising the knowledge of prior steps.
FedFT: Improving Communication Performance for Federated Learning with Frequency Space Transformation
Sep 08, 2024



Communication efficiency is a widely recognised research problem in Federated Learning (FL), with recent work focused on developing techniques for efficient compression, distribution and aggregation of model parameters between clients and the server. Particularly within distributed systems, it is important to balance the need for computational cost and communication efficiency. However, existing methods are often constrained to specific applications and are less generalisable. In this paper, we introduce FedFT (federated frequency-space transformation), a simple yet effective methodology for communicating model parameters in a FL setting. FedFT uses Discrete Cosine Transform (DCT) to represent model parameters in frequency space, enabling efficient compression and reducing communication overhead. FedFT is compatible with various existing FL methodologies and neural architectures, and its linear property eliminates the need for multiple transformations during federated aggregation. This methodology is vital for distributed solutions, tackling essential challenges like data privacy, interoperability, and energy efficiency inherent to these environments. We demonstrate the generalisability of the FedFT methodology on four datasets using comparative studies with three state-of-the-art FL baselines (FedAvg, FedProx, FedSim). Our results demonstrate that using FedFT to represent the differences in model parameters between communication rounds in frequency space results in a more compact representation compared to representing the entire model in frequency space. This leads to a reduction in communication overhead, while keeping accuracy levels comparable and in some cases even improving it. Our results suggest that this reduction can range from 5% to 30% per client, depending on dataset.
iSee: Advancing Multi-Shot Explainable AI Using Case-based Recommendations
Aug 23, 2024



Explainable AI (XAI) can greatly enhance user trust and satisfaction in AI-assisted decision-making processes. Recent findings suggest that a single explainer may not meet the diverse needs of multiple users in an AI system; indeed, even individual users may require multiple explanations. This highlights the necessity for a "multi-shot" approach, employing a combination of explainers to form what we introduce as an "explanation strategy". Tailored to a specific user or a user group, an "explanation experience" describes interactions with personalised strategies designed to enhance their AI decision-making processes. The iSee platform is designed for the intelligent sharing and reuse of explanation experiences, using Case-based Reasoning to advance best practices in XAI. The platform provides tools that enable AI system designers, i.e. design users, to design and iteratively revise the most suitable explanation strategy for their AI system to satisfy end-user needs. All knowledge generated within the iSee platform is formalised by the iSee ontology for interoperability. We use a summative mixed methods study protocol to evaluate the usability and utility of the iSee platform with six design users across varying levels of AI and XAI expertise. Our findings confirm that the iSee platform effectively generalises across applications and its potential to promote the adoption of XAI best practices.
XEQ Scale for Evaluating XAI Experience Quality Grounded in Psychometric Theory
Jul 15, 2024Explainable Artificial Intelligence (XAI) aims to improve the transparency of autonomous decision-making through explanations. Recent literature has emphasised users' need for holistic "multi-shot" explanations and the ability to personalise their engagement with XAI systems. We refer to this user-centred interaction as an XAI Experience. Despite advances in creating XAI experiences, evaluating them in a user-centred manner has remained challenging. To address this, we introduce the XAI Experience Quality (XEQ) Scale (pronounced "Seek" Scale), for evaluating the user-centred quality of XAI experiences. Furthermore, XEQ quantifies the quality of experiences across four evaluation dimensions: learning, utility, fulfilment and engagement. These contributions extend the state-of-the-art of XAI evaluation, moving beyond the one-dimensional metrics frequently developed to assess single-shot explanations. In this paper, we present the XEQ scale development and validation process, including content validation with XAI experts as well as discriminant and construct validation through a large-scale pilot study. Out pilot study results offer strong evidence that establishes the XEQ Scale as a comprehensive framework for evaluating user-centred XAI experiences.
Tell me more: Intent Fulfilment Framework for Enhancing User Experiences in Conversational XAI
May 16, 2024The evolution of Explainable Artificial Intelligence (XAI) has emphasised the significance of meeting diverse user needs. The approaches to identifying and addressing these needs must also advance, recognising that explanation experiences are subjective, user-centred processes that interact with users towards a better understanding of AI decision-making. This paper delves into the interrelations in multi-faceted XAI and examines how different types of explanations collaboratively meet users' XAI needs. We introduce the Intent Fulfilment Framework (IFF) for creating explanation experiences. The novelty of this paper lies in recognising the importance of "follow-up" on explanations for obtaining clarity, verification and/or substitution. Moreover, the Explanation Experience Dialogue Model integrates the IFF and "Explanation Followups" to provide users with a conversational interface for exploring their explanation needs, thereby creating explanation experiences. Quantitative and qualitative findings from our comparative user study demonstrate the impact of the IFF in improving user engagement, the utility of the AI system and the overall user experience. Overall, we reinforce the principle that "one explanation does not fit all" to create explanation experiences that guide the complex interaction through conversation.
Towards Feasible Counterfactual Explanations: A Taxonomy Guided Template-based NLG Method
Oct 03, 2023



Counterfactual Explanations (cf-XAI) describe the smallest changes in feature values necessary to change an outcome from one class to another. However, many cf-XAI methods neglect the feasibility of those changes. In this paper, we introduce a novel approach for presenting cf-XAI in natural language (Natural-XAI), giving careful consideration to actionable and comprehensible aspects while remaining cognizant of immutability and ethical concerns. We present three contributions to this endeavor. Firstly, through a user study, we identify two types of themes present in cf-XAI composed by humans: content-related, focusing on how features and their values are included from both the counterfactual and the query perspectives; and structure-related, focusing on the structure and terminology used for describing necessary value changes. Secondly, we introduce a feature actionability taxonomy with four clearly defined categories, to streamline the explanation presentation process. Using insights from the user study and our taxonomy, we created a generalisable template-based natural language generation (NLG) method compatible with existing explainers like DICE, NICE, and DisCERN, to produce counterfactuals that address the aforementioned limitations of existing approaches. Finally, we conducted a second user study to assess the performance of our taxonomy-guided NLG templates on three domains. Our findings show that the taxonomy-guided Natural-XAI approach (n-XAI^T) received higher user ratings across all dimensions, with significantly improved results in the majority of the domains assessed for articulation, acceptability, feasibility, and sensitivity dimensions.
Behaviour Trees for Conversational Explanation Experiences
Nov 11, 2022



Explainable AI (XAI) has the potential to make a significant impact on building trust and improving the satisfaction of users who interact with an AI system for decision-making. There is an abundance of explanation techniques in literature to address this need. Recently, it has been shown that a user is likely to have multiple explanation needs that should be addressed by a constellation of explanation techniques which we refer to as an explanation strategy. This paper focuses on how users interact with an XAI system to fulfil these multiple explanation needs satisfied by an explanation strategy. For this purpose, the paper introduces the concept of an "explanation experience" - as episodes of user interactions captured by the XAI system when explaining the decisions made by its AI system. In this paper, we explore how to enable and capture explanation experiences through conversational interactions. We model the interactive explanation experience as a dialogue model. Specifically, Behaviour Trees (BT) are used to model conversational pathways and chatbot behaviours. A BT dialogue model is easily personalised by dynamically extending or modifying it to attend to different user needs and explanation strategies. An evaluation with a real-world use case shows that BTs have a number of properties that lend naturally to modelling and capturing explanation experiences; as compared to traditionally used state transition models.
Clinical Dialogue Transcription Error Correction using Seq2Seq Models
May 26, 2022
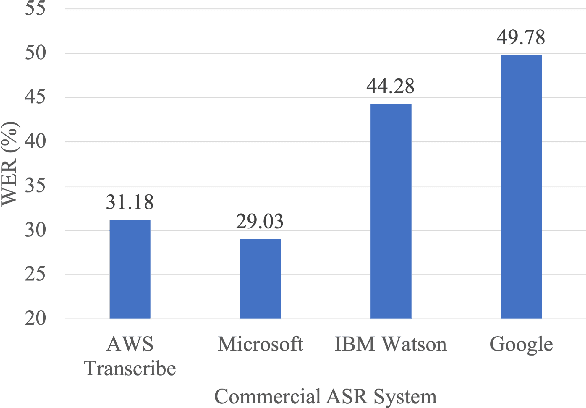
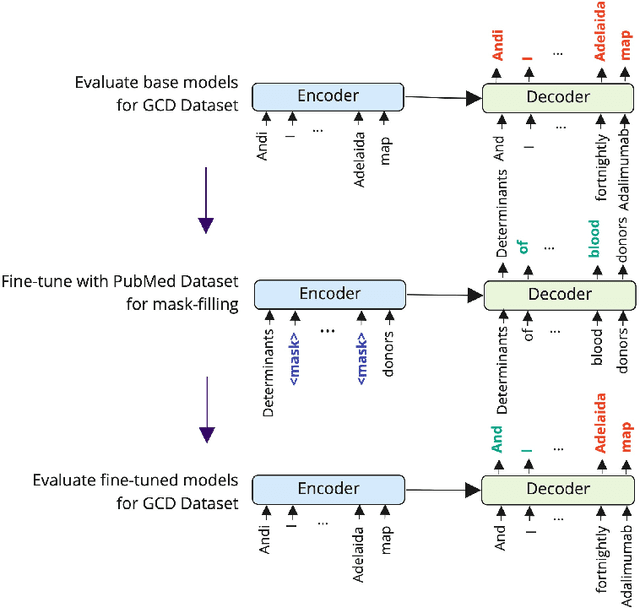

Good communication is critical to good healthcare. Clinical dialogue is a conversation between health practitioners and their patients, with the explicit goal of obtaining and sharing medical information. This information contributes to medical decision-making regarding the patient and plays a crucial role in their healthcare journey. The reliance on note taking and manual scribing processes are extremely inefficient and leads to manual transcription errors when digitizing notes. Automatic Speech Recognition (ASR) plays a significant role in speech-to-text applications, and can be directly used as a text generator in conversational applications. However, recording clinical dialogue presents a number of general and domain-specific challenges. In this paper, we present a seq2seq learning approach for ASR transcription error correction of clinical dialogues. We introduce a new Gastrointestinal Clinical Dialogue (GCD) Dataset which was gathered by healthcare professionals from a NHS Inflammatory Bowel Disease clinic and use this in a comparative study with four commercial ASR systems. Using self-supervision strategies, we fine-tune a seq2seq model on a mask-filling task using a domain-specific PubMed dataset which we have shared publicly for future research. The BART model fine-tuned for mask-filling was able to correct transcription errors and achieve lower word error rates for three out of four commercial ASR outputs.
DisCERN:Discovering Counterfactual Explanations using Relevance Features from Neighbourhoods
Sep 13, 2021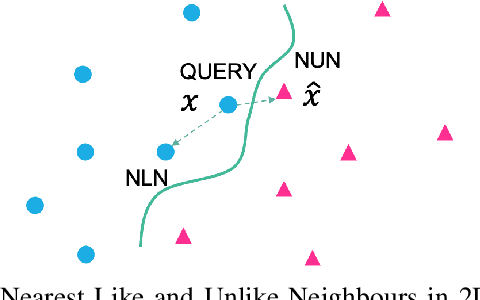
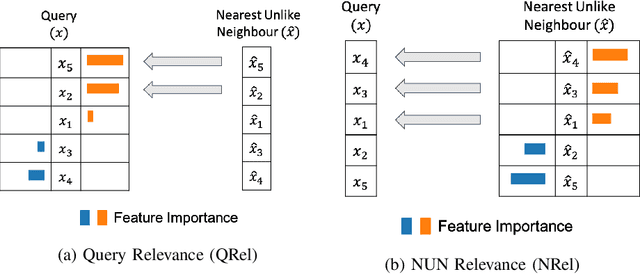
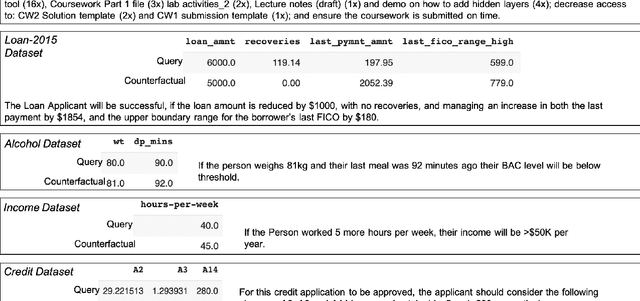

Counterfactual explanations focus on "actionable knowledge" to help end-users understand how a machine learning outcome could be changed to a more desirable outcome. For this purpose a counterfactual explainer needs to discover input dependencies that relate to outcome changes. Identifying the minimum subset of feature changes needed to action an output change in the decision is an interesting challenge for counterfactual explainers. The DisCERN algorithm introduced in this paper is a case-based counter-factual explainer. Here counterfactuals are formed by replacing feature values from a nearest unlike neighbour (NUN) until an actionable change is observed. We show how widely adopted feature relevance-based explainers (i.e. LIME, SHAP), can inform DisCERN to identify the minimum subset of "actionable features". We demonstrate our DisCERN algorithm on five datasets in a comparative study with the widely used optimisation-based counterfactual approach DiCE. Our results demonstrate that DisCERN is an effective strategy to minimise actionable changes necessary to create good counterfactual explanations.
Learning-to-Learn Personalised Human Activity Recognition Models
Jun 12, 2020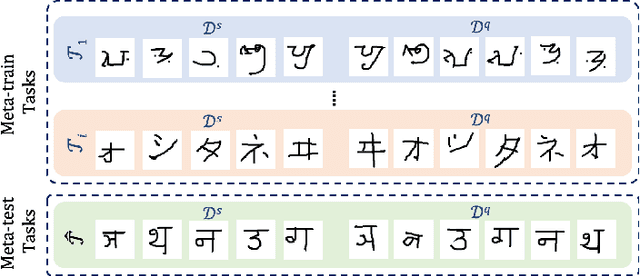

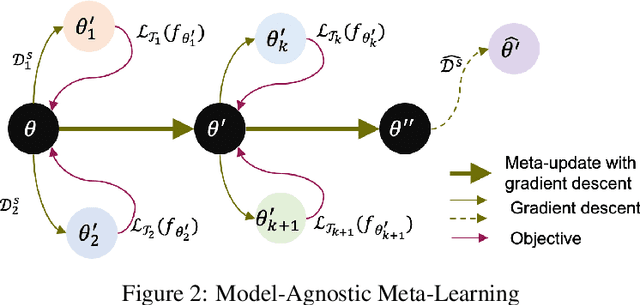

Human Activity Recognition~(HAR) is the classification of human movement, captured using one or more sensors either as wearables or embedded in the environment~(e.g. depth cameras, pressure mats). State-of-the-art methods of HAR rely on having access to a considerable amount of labelled data to train deep architectures with many train-able parameters. This becomes prohibitive when tasked with creating models that are sensitive to personal nuances in human movement, explicitly present when performing exercises. In addition, it is not possible to collect training data to cover all possible subjects in the target population. Accordingly, learning personalised models with few data remains an interesting challenge for HAR research. We present a meta-learning methodology for learning to learn personalised HAR models for HAR; with the expectation that the end-user need only provides a few labelled data but can benefit from the rapid adaptation of a generic meta-model. We introduce two algorithms, Personalised MAML and Personalised Relation Networks inspired by existing Meta-Learning algorithms but optimised for learning HAR models that are adaptable to any person in health and well-being applications. A comparative study shows significant performance improvements against the state-of-the-art Deep Learning algorithms and the Few-shot Meta-Learning algorithms in multiple HAR domains.