 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimation of Stochastic Attribute-Value Grammars using an Informative Sample
Paper and Code
Aug 23, 2000

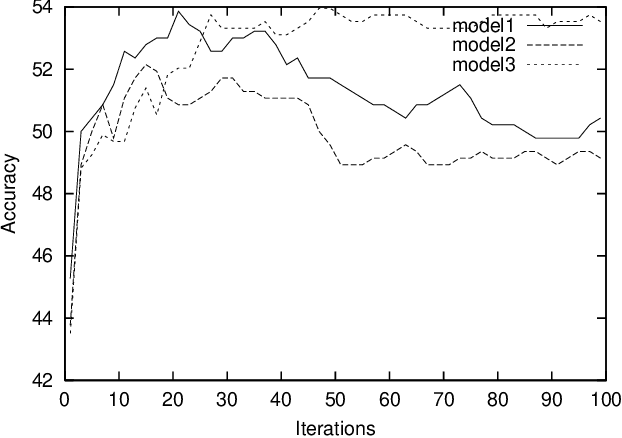

We argue that some of the computational complexity associated with estimation of stochastic attribute-value grammars can be reduced by training upon an informative subset of the full training set. Results using the parsed Wall Street Journal corpus show that in some circumstances, it is possible to obtain better estimation results using an informative sample than when training upon all the available material. Further experimentation demonstrates that with unlexicalised models, a Gaussian Prior can reduce overfitting. However, when models are lexicalised and contain overlapping features, overfitting does not seem to be a problem, and a Gaussian Prior makes minimal difference to performance. Our approach is applicable for situations when there are an infeasibly large number of parses in the training set, or else for when recovery of these parses from a packed representation is itself computationally expensive.