 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Interpretability in Generative AI Through Search-Based Data Influence Analysis
Apr 02, 2025Generative AI models offer powerful capabilities but often lack transparency, making it difficult to interpret their output. This is critical in cases involving artistic or copyrighted content. This work introduces a search-inspired approach to improve the interpretability of these models by analysing the influence of training data on their outputs. Our method provides observational interpretability by focusing on a model's output rather than on its internal state. We consider both raw data and latent-space embeddings when searching for the influence of data items in generated content. We evaluate our method by retraining models locally and by demonstrating the method's ability to uncover influential subsets in the training data. This work lays the groundwork for future extensions, including user-based evaluations with domain experts, which is expected to improve observational interpretability further.
WeLa-VAE: Learning Alternative Disentangled Representations Using Weak Labels
Aug 22, 2020
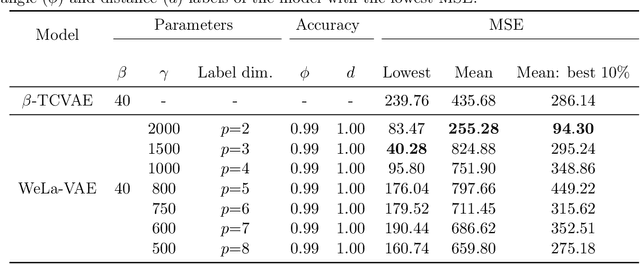
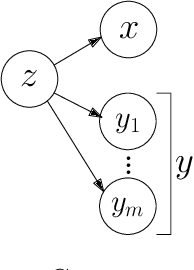
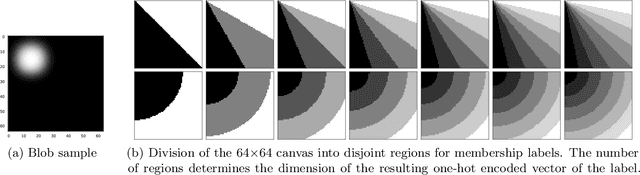
Learning disentangled representations without supervision or inductive biases, often leads to non-interpretable or undesirable representations. On the other hand, strict supervision requires detailed knowledge of the true generative factors, which is not always possible. In this paper, we consider weak supervision by means of high-level labels that are not assumed to be explicitly related to the ground truth factors. Such labels, while being easier to acquire, can also be used as inductive biases for algorithms to learn more interpretable or alternative disentangled representations. To this end, we propose WeLa-VAE, a variational inference framework where observations and labels share the same latent variables, which involves the maximization of a modified variational lower bound and total correlation regularization. Our method is a generalization of TCVAE, adding only one extra hyperparameter. We experiment on a dataset generated by Cartesian coordinates and we show that, while a TCVAE learns a factorized Cartesian representation, given weak labels of distance and angle, WeLa-VAE is able to learn and disentangle a polar representation. This is achieved without the need of refined labels or having to adjust the number of layers, the optimization parameters, or the total correlation hyperparameter.
Unsupervised Severe Weather Detection Via Joint Representation Learning Over Textual and Weather Data
May 14, 2020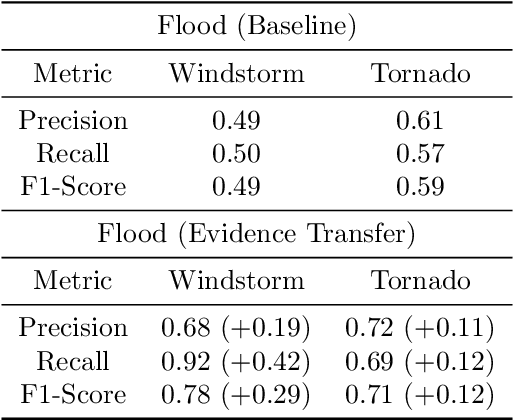
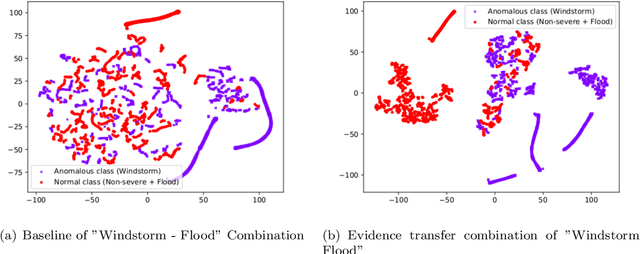
When observing a phenomenon, severe cases or anomalies are often characterised by deviation from the expected data distribution. However, non-deviating data samples may also implicitly lead to severe outcomes. In the case of unsupervised severe weather detection, these data samples can lead to mispredictions, since the predictors of severe weather are often not directly observed as features. We posit that incorporating external or auxiliary information, such as the outcome of an external task or an observation, can improve the decision boundaries of an unsupervised detection algorithm. In this paper, we increase the effectiveness of a clustering method to detect cases of severe weather by learning augmented and linearly separable latent representations.We evaluate our solution against three individual cases of severe weather, namely windstorms, floods and tornado outbreaks.
Learning Improved Representations by Transferring Incomplete Evidence Across Heterogeneous Tasks
Dec 22, 2019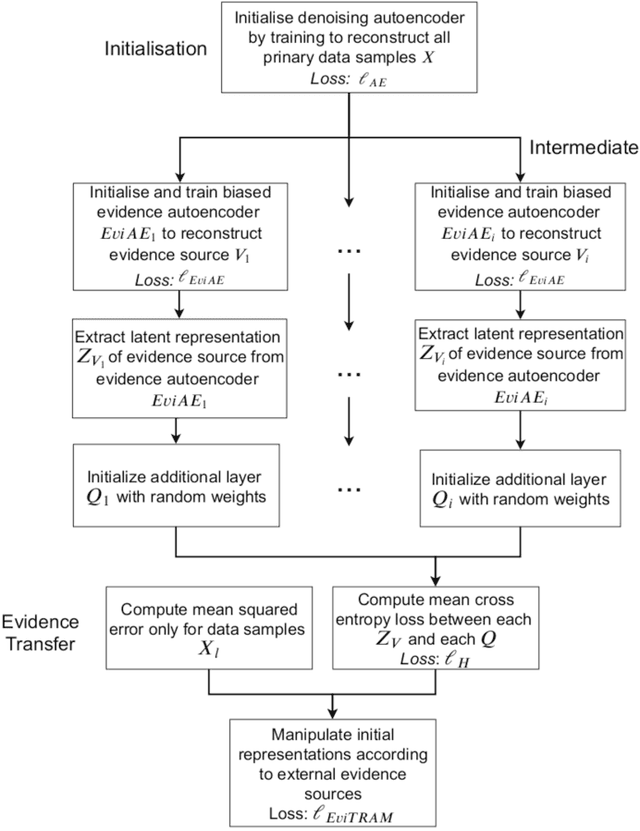
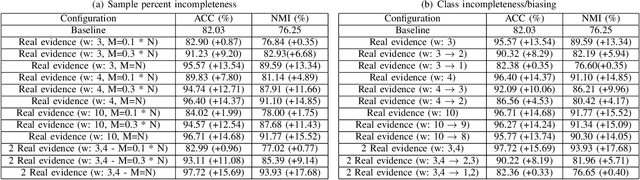
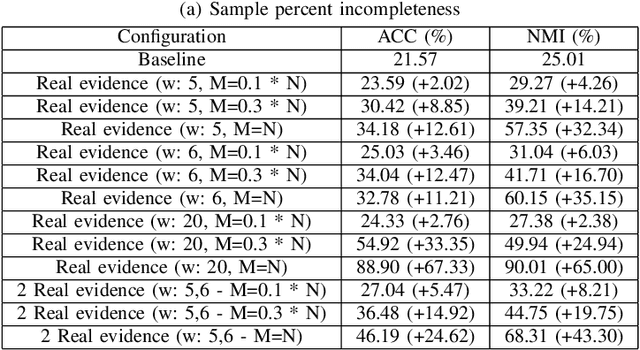
Acquiring ground truth labels for unlabelled data can be a costly procedure, since it often requires manual labour that is error-prone. Consequently, the available amount of labelled data is increasingly reduced due to the limitations of manual data labelling. It is possible to increase the amount of labelled data samples by performing automated labelling or crowd-sourcing the annotation procedure. However, they often introduce noise or uncertainty in the labelset, that leads to decreased performance of supervised deep learning methods. On the other hand, weak supervision methods remain robust during noisy labelsets or can be effective even with low amounts of labelled data. In this paper we evaluate the effectiveness of a representation learning method that uses external categorical evidence called "Evidence Transfer", against low amount of corresponding evidence termed as incomplete evidence. Evidence transfer is a robust solution against external unknown categorical evidence that can introduce noise or uncertainty. In our experimental evaluation, evidence transfer proves to be effective and robust against different levels of incompleteness, for two types of incomplete evidence.
Evidence Transfer for Improving Clustering Tasks Using External Categorical Evidence
Nov 09, 2018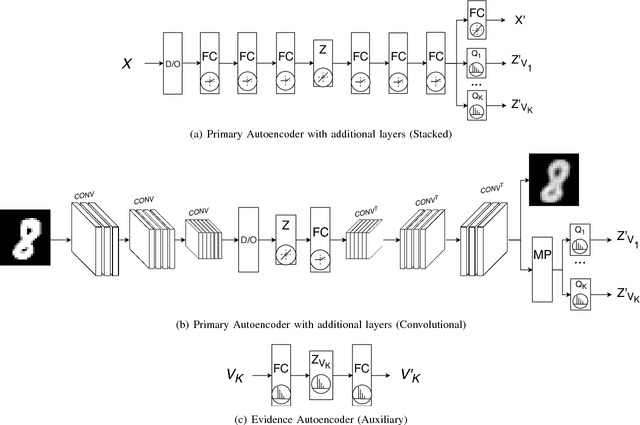

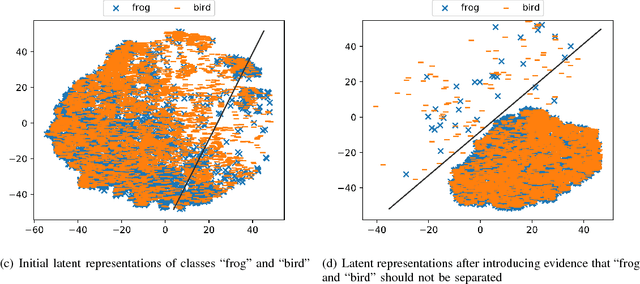

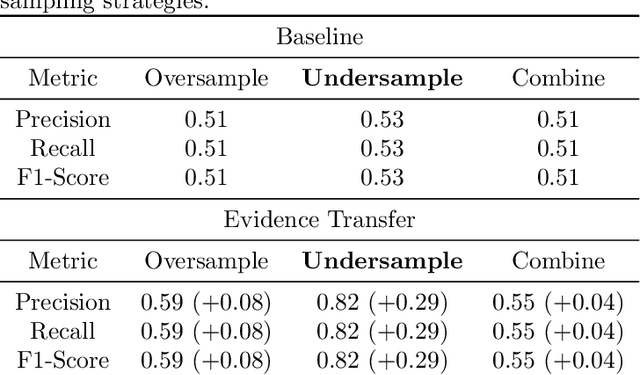
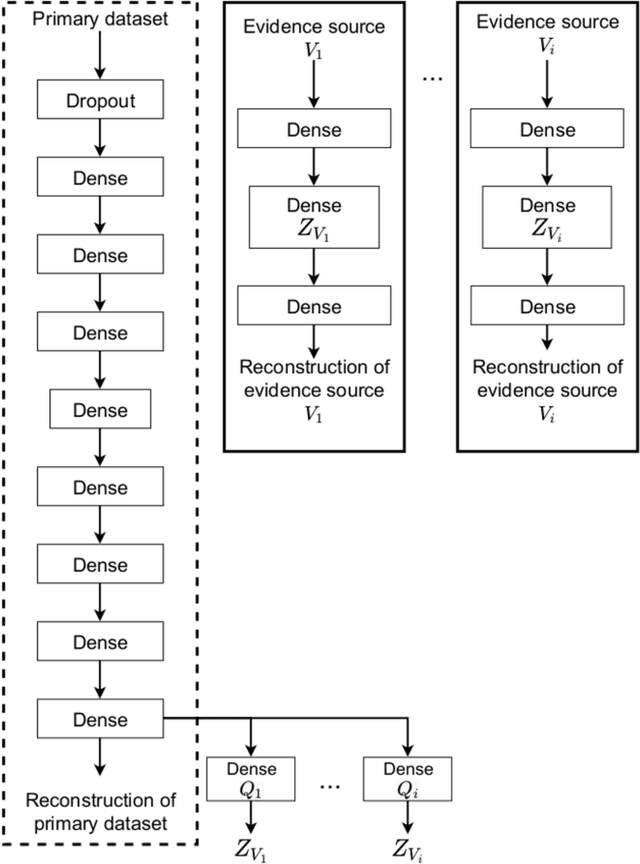
In this paper we introduce evidence transfer for clustering, a deep learning method that can incrementally manipulate the latent representations of an autoencoder, according to external categorical evidence, in order to improve a clustering outcome. It is deployed on a baseline solution to reduce the cross entropy between the external evidence and an extension of the latent space. By evidence transfer we define the process by which the categorical outcome of an external, auxiliary task is exploited to improve a primary task, in this case representation learning for clustering. Our proposed method makes no assumptions regarding the categorical evidence presented, nor the structure of the latent space. We compare our method, against the baseline solution by performing k-means clustering before and after its deployment. Experiments with three different kinds of evidence show that our method effectively manipulates the latent representations when introduced with real corresponding evidence, while remaining robust when presented with low quality evidence.
ANNETT-O: An Ontology for Describing Artificial Neural Network Evaluation, Topology and Training
May 10, 2018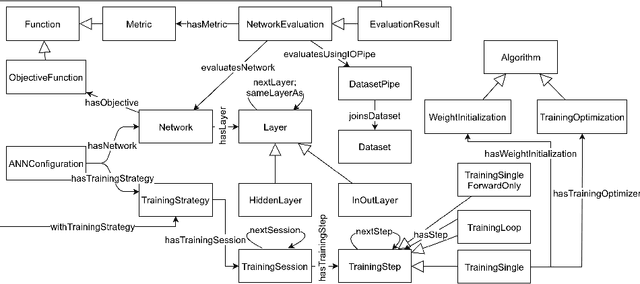
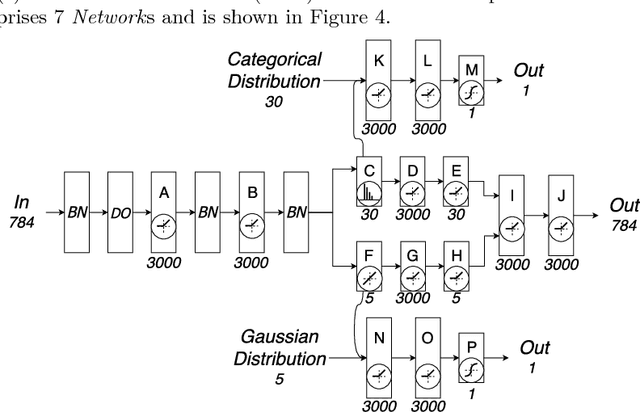

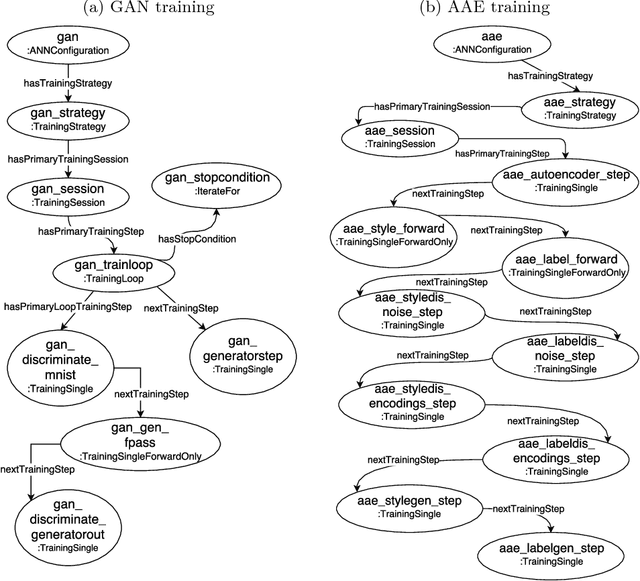
Deep learning models, while effective and versatile, are becoming increasingly complex, often including multiple overlapping networks of arbitrary depths, multiple objectives and non-intuitive training methodologies. This makes it increasingly difficult for researchers and practitioners to design, train and understand them. In this paper we present ANNETT-O, a much-needed, generic and computer-actionable vocabulary for researchers and practitioners to describe their deep learning configurations, training procedures and experiments. The proposed ontology focuses on topological, training and evaluation aspects of complex deep neural configurations, while keeping peripheral entities more succinct. Knowledge bases implementing ANNETT-O can support a wide variety of queries, providing relevant insights to users. In addition to a detailed description of the ontology, we demonstrate its suitability to the task via a number of hypothetical use-cases of increasing complexity.