 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating the resolution of flight conflicts: Deep reinforcement learning in service of air traffic controllers
Jun 15, 2022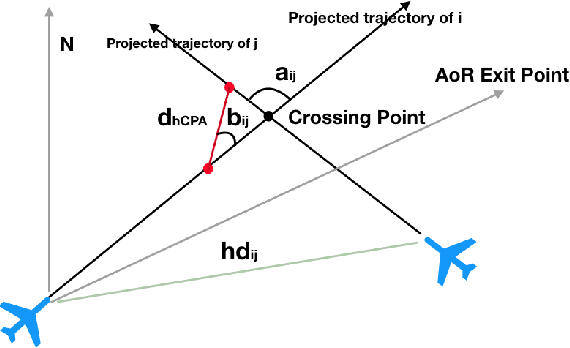
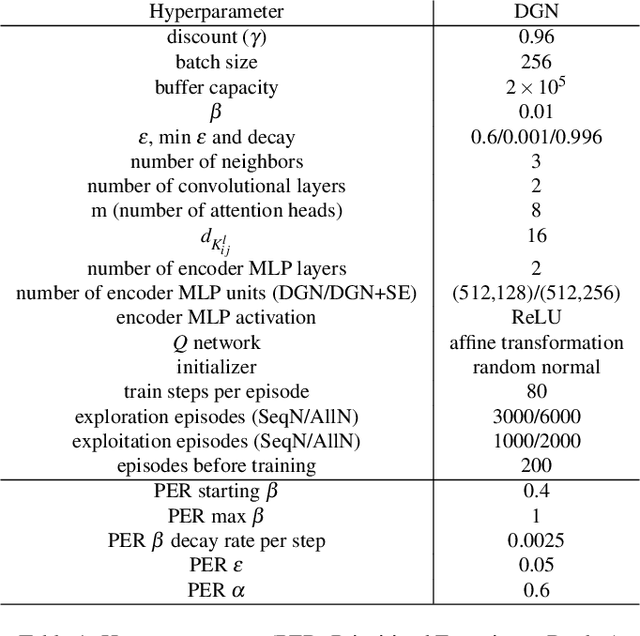
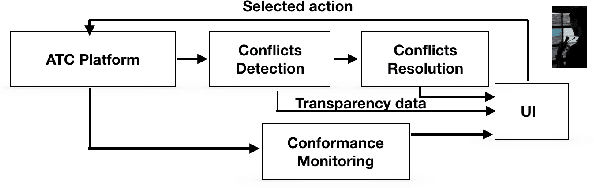

Dense and complex air traffic scenarios require higher levels of automation than those exhibited by tactical conflict detection and resolution (CD\&R) tools that air traffic controllers (ATCO) use today. However, the air traffic control (ATC) domain, being safety critical, requires AI systems to which operators are comfortable to relinquishing control, guaranteeing operational integrity and automation adoption. Two major factors towards this goal are quality of solutions, and transparency in decision making. This paper proposes using a graph convolutional reinforcement learning method operating in a multiagent setting where each agent (flight) performs a CD\&R task, jointly with other agents. We show that this method can provide high-quality solutions with respect to stakeholders interests (air traffic controllers and airspace users), addressing operational transparency issues.
Data-driven prediction of Air Traffic Controllers reactions to resolving conflicts
May 19, 2022
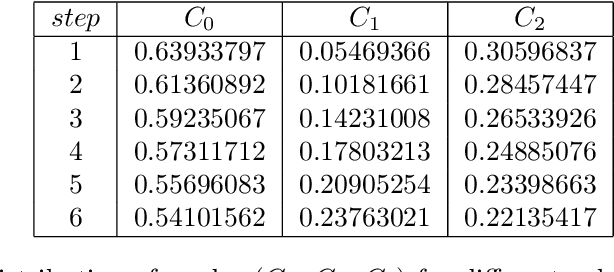
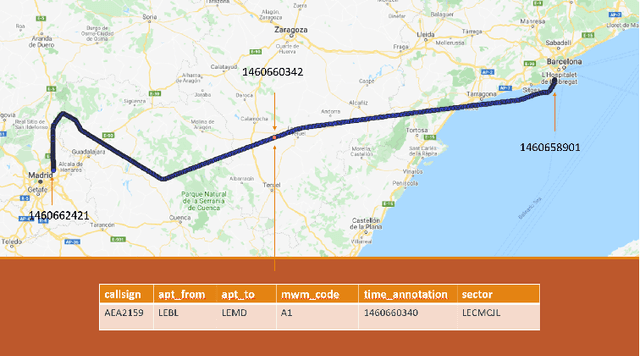
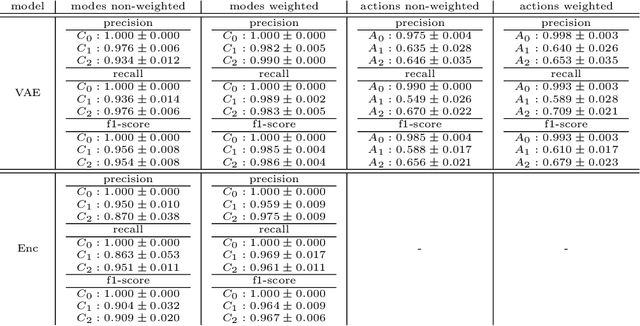
With the aim to enhance automation in conflict detection and resolution (CD&R) tasks in the Air Traffic Management domain, in this paper we propose deep learning techniques (DL) that can learn models of Air Traffic Controllers' (ATCO) reactions in resolving conflicts that can violate separation minimum constraints among aircraft trajectories: This implies learning when the ATCO will react towards resolving a conflict, and how he/she will react. Timely reactions, to which this paper aims, focus on when do reactions happen, aiming to predict the trajectory points, as the trajectory evolves, that the ATCO issues a conflict resolution action, while also predicting the type of resolution action (if any). Towards this goal, the paper formulates the ATCO reactions prediction problem for CD&R, and presents DL methods that can model ATCO timely reactions and evaluates these methods in real-world data sets, showing their efficacy in prediction with very high accuracy.
Data Driven Aircraft Trajectory Prediction with Deep Imitation Learning
May 16, 2020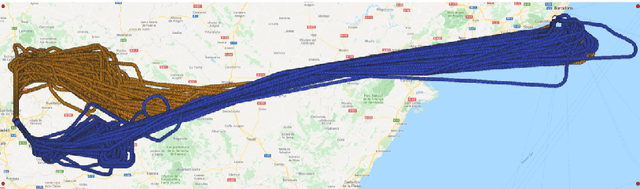
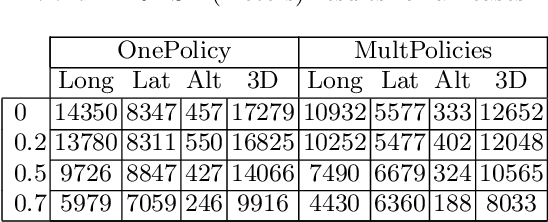
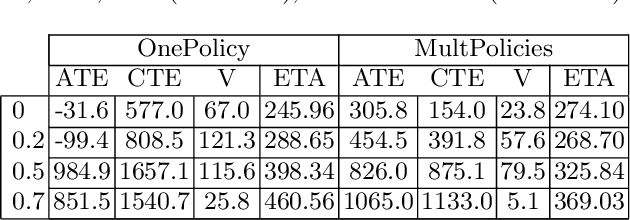
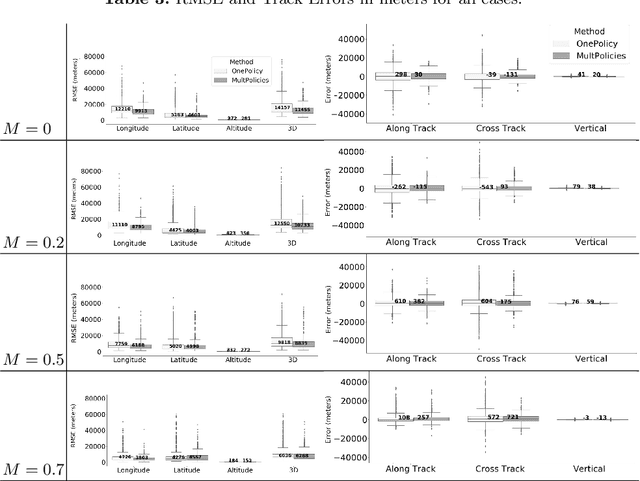
The current Air Traffic Management (ATM) system worldwide has reached its limits in terms of predictability, efficiency and cost effectiveness. Different initiatives worldwide propose trajectory-oriented transformations that require high fidelity aircraft trajectory planning and prediction capabilities, supporting the trajectory life cycle at all stages efficiently. Recently proposed data-driven trajectory prediction approaches provide promising results. In this paper we approach the data-driven trajectory prediction problem as an imitation learning task, where we aim to imitate experts "shaping" the trajectory. Towards this goal we present a comprehensive framework comprising the Generative Adversarial Imitation Learning state of the art method, in a pipeline with trajectory clustering and classification methods. This approach, compared to other approaches, can provide accurate predictions for the whole trajectory (i.e. with a prediction horizon until reaching the destination) both at the pre-tactical (i.e. starting at the departure airport at a specific time instant) and at the tactical (i.e. from any state while flying) stages, compared to state of the art approaches.
Resolving Congestions in the Air Traffic Management Domain via Multiagent Reinforcement Learning Methods
Dec 14, 2019
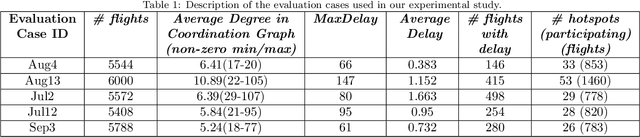
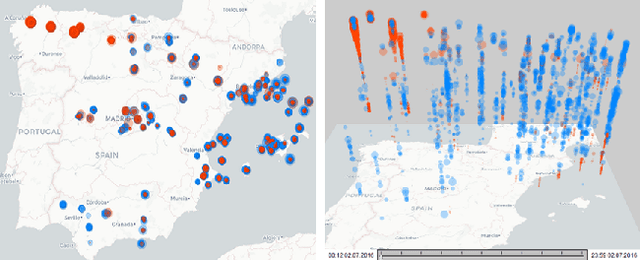
In this article, we report on the efficiency and effectiveness of multiagent reinforcement learning methods (MARL) for the computation of flight delays to resolve congestion problems in the Air Traffic Management (ATM) domain. Specifically, we aim to resolve cases where demand of airspace use exceeds capacity (demand-capacity problems), via imposing ground delays to flights at the pre-tactical stage of operations (i.e. few days to few hours before operation). Casting this into the multiagent domain, agents, representing flights, need to decide on own delays w.r.t. own preferences, having no information about others' payoffs, preferences and constraints, while they plan to execute their trajectories jointly with others, adhering to operational constraints. Specifically, we formalize the problem as a multiagent Markov Decision Process (MA-MDP) and we show that it can be considered as a Markov game in which interacting agents need to reach an equilibrium: What makes the problem more interesting is the dynamic setting in which agents operate, which is also due to the unforeseen, emergent effects of their decisions in the whole system. We propose collaborative multiagent reinforcement learning methods to resolve demand-capacity imbalances: Extensive experimental study on real-world cases, shows the potential of the proposed approaches in resolving problems, while advanced visualizations provide detailed views towards understanding the quality of solutions provided.