 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to maintain safety through expert demonstrations in settings with unknown constraints: A Q-learning perspective
Feb 27, 2026Given a set of trajectories demonstrating the execution of a task safely in a constrained MDP with observable rewards but with unknown constraints and non-observable costs, we aim to find a policy that maximizes the likelihood of demonstrated trajectories trading the balance between being conservative and increasing significantly the likelihood of high-rewarding trajectories but with potentially unsafe steps. Having these objectives, we aim towards learning a policy that maximizes the probability of the most $promising$ trajectories with respect to the demonstrations. In so doing, we formulate the ``promise" of individual state-action pairs in terms of $Q$ values, which depend on task-specific rewards as well as on the assessment of states' safety, mixing expectations in terms of rewards and safety. This entails a safe Q-learning perspective of the inverse learning problem under constraints: The devised Safe $Q$ Inverse Constrained Reinforcement Learning (SafeQIL) algorithm is compared to state-of-the art inverse constraint reinforcement learning algorithms to a set of challenging benchmark tasks, showing its merits.
* Accepted for publication at AAMAS 2026
Leveraging LLMs for Collaborative Ontology Engineering in Parkinson Disease Monitoring and Alerting
Dec 16, 2025This paper explores the integration of Large Language Models (LLMs) in the engineering of a Parkinson's Disease (PD) monitoring and alerting ontology through four key methodologies: One Shot (OS) prompt techniques, Chain of Thought (CoT) prompts, X-HCOME, and SimX-HCOME+. The primary objective is to determine whether LLMs alone can create comprehensive ontologies and, if not, whether human-LLM collaboration can achieve this goal. Consequently, the paper assesses the effectiveness of LLMs in automated ontology development and the enhancement achieved through human-LLM collaboration. Initial ontology generation was performed using One Shot (OS) and Chain of Thought (CoT) prompts, demonstrating the capability of LLMs to autonomously construct ontologies for PD monitoring and alerting. However, these outputs were not comprehensive and required substantial human refinement to enhance their completeness and accuracy. X-HCOME, a hybrid ontology engineering approach that combines human expertise with LLM capabilities, showed significant improvements in ontology comprehensiveness. This methodology resulted in ontologies that are very similar to those constructed by experts. Further experimentation with SimX-HCOME+, another hybrid methodology emphasizing continuous human supervision and iterative refinement, highlighted the importance of ongoing human involvement. This approach led to the creation of more comprehensive and accurate ontologies. Overall, the paper underscores the potential of human-LLM collaboration in advancing ontology engineering, particularly in complex domains like PD. The results suggest promising directions for future research, including the development of specialized GPT models for ontology construction.
Learning safe, constrained policies via imitation learning: Connection to Probabilistic Inference and a Naive Algorithm
Jul 09, 2025This article introduces an imitation learning method for learning maximum entropy policies that comply with constraints demonstrated by expert trajectories executing a task. The formulation of the method takes advantage of results connecting performance to bounds for the KL-divergence between demonstrated and learned policies, and its objective is rigorously justified through a connection to a probabilistic inference framework for reinforcement learning, incorporating the reinforcement learning objective and the objective to abide by constraints in an entropy maximization setting. The proposed algorithm optimizes the learning objective with dual gradient descent, supporting effective and stable training. Experiments show that the proposed method can learn effective policy models for constraints-abiding behaviour, in settings with multiple constraints of different types, accommodating different modalities of demonstrated behaviour, and with abilities to generalize.
Explainable Deep Reinforcement Learning: State of the Art and Challenges
Jan 24, 2023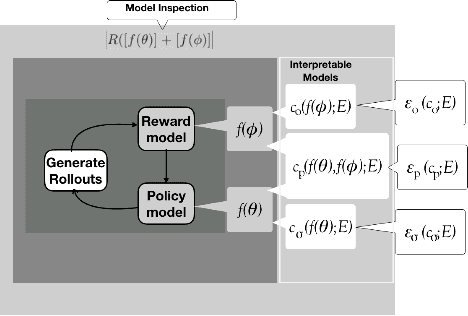
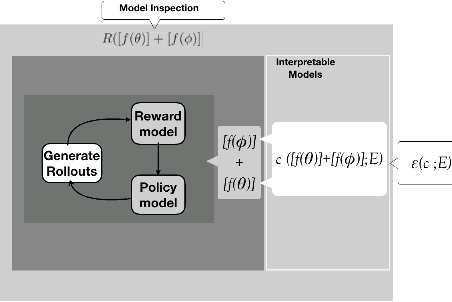
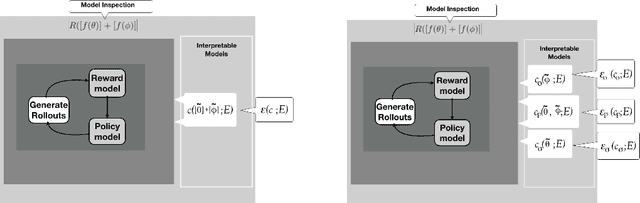
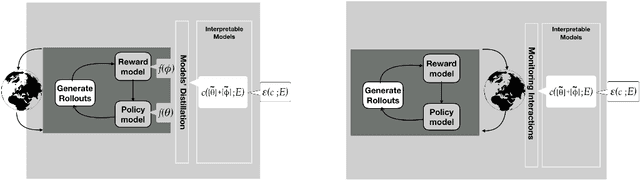
Interpretability, explainability and transparency are key issues to introducing Artificial Intelligence methods in many critical domains: This is important due to ethical concerns and trust issues strongly connected to reliability, robustness, auditability and fairness, and has important consequences towards keeping the human in the loop in high levels of automation, especially in critical cases for decision making, where both (human and the machine) play important roles. While the research community has given much attention to explainability of closed (or black) prediction boxes, there are tremendous needs for explainability of closed-box methods that support agents to act autonomously in the real world. Reinforcement learning methods, and especially their deep versions, are such closed-box methods. In this article we aim to provide a review of state of the art methods for explainable deep reinforcement learning methods, taking also into account the needs of human operators - i.e., of those that take the actual and critical decisions in solving real-world problems. We provide a formal specification of the deep reinforcement learning explainability problems, and we identify the necessary components of a general explainable reinforcement learning framework. Based on these, we provide a comprehensive review of state of the art methods, categorizing them in classes according to the paradigm they follow, the interpretable models they use, and the surface representation of explanations provided. The article concludes identifying open questions and important challenges.
Data-driven prediction of Air Traffic Controllers reactions to resolving conflicts
May 19, 2022
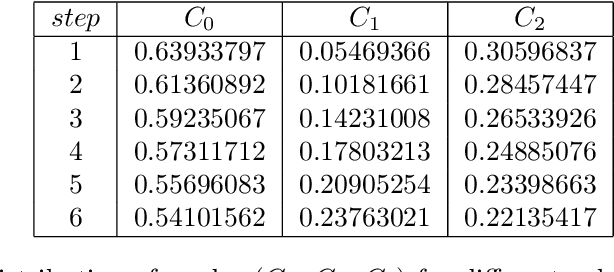
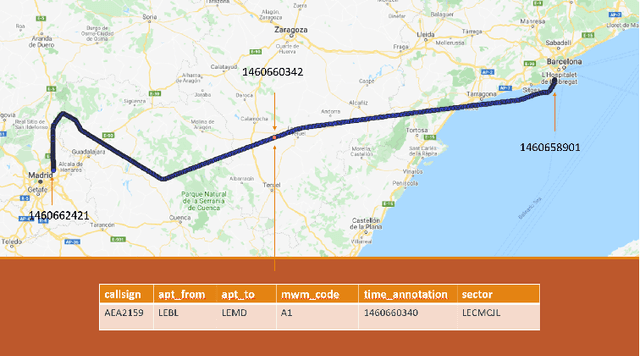
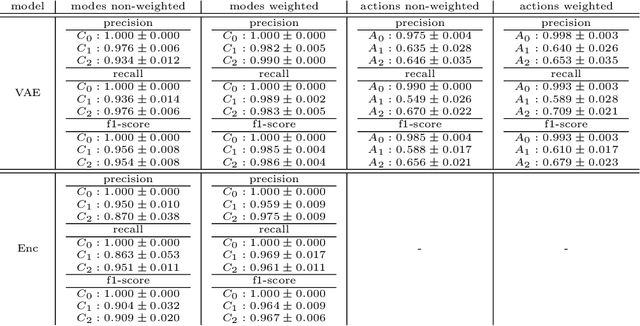
With the aim to enhance automation in conflict detection and resolution (CD&R) tasks in the Air Traffic Management domain, in this paper we propose deep learning techniques (DL) that can learn models of Air Traffic Controllers' (ATCO) reactions in resolving conflicts that can violate separation minimum constraints among aircraft trajectories: This implies learning when the ATCO will react towards resolving a conflict, and how he/she will react. Timely reactions, to which this paper aims, focus on when do reactions happen, aiming to predict the trajectory points, as the trajectory evolves, that the ATCO issues a conflict resolution action, while also predicting the type of resolution action (if any). Towards this goal, the paper formulates the ATCO reactions prediction problem for CD&R, and presents DL methods that can model ATCO timely reactions and evaluates these methods in real-world data sets, showing their efficacy in prediction with very high accuracy.
Data Driven Aircraft Trajectory Prediction with Deep Imitation Learning
May 16, 2020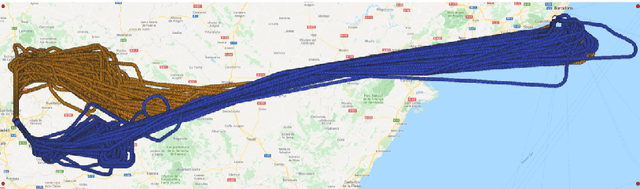
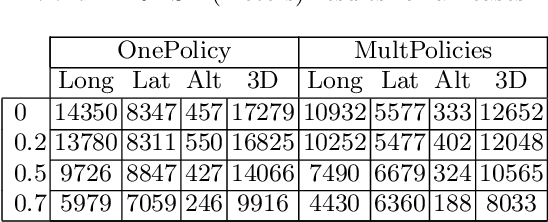
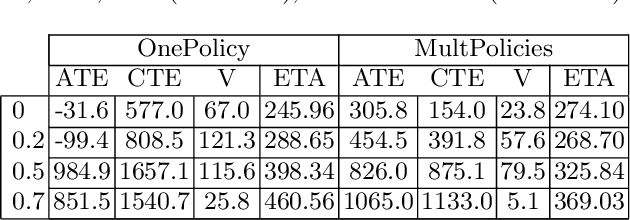
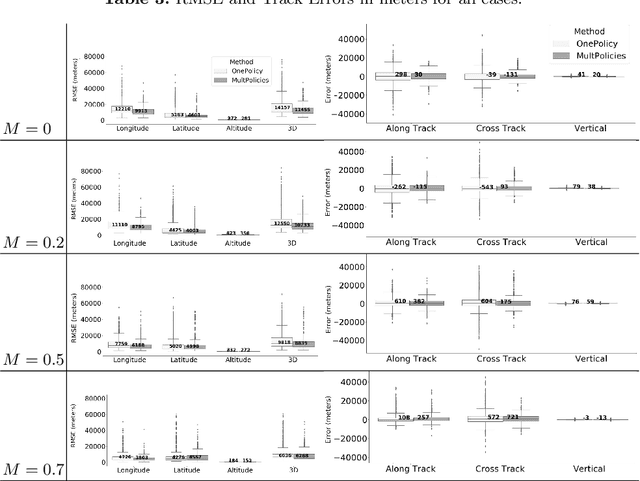
The current Air Traffic Management (ATM) system worldwide has reached its limits in terms of predictability, efficiency and cost effectiveness. Different initiatives worldwide propose trajectory-oriented transformations that require high fidelity aircraft trajectory planning and prediction capabilities, supporting the trajectory life cycle at all stages efficiently. Recently proposed data-driven trajectory prediction approaches provide promising results. In this paper we approach the data-driven trajectory prediction problem as an imitation learning task, where we aim to imitate experts "shaping" the trajectory. Towards this goal we present a comprehensive framework comprising the Generative Adversarial Imitation Learning state of the art method, in a pipeline with trajectory clustering and classification methods. This approach, compared to other approaches, can provide accurate predictions for the whole trajectory (i.e. with a prediction horizon until reaching the destination) both at the pre-tactical (i.e. starting at the departure airport at a specific time instant) and at the tactical (i.e. from any state while flying) stages, compared to state of the art approaches.
Resolving Congestions in the Air Traffic Management Domain via Multiagent Reinforcement Learning Methods
Dec 14, 2019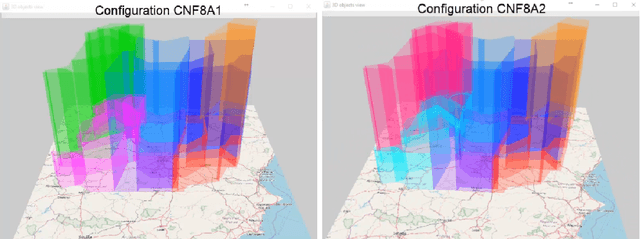
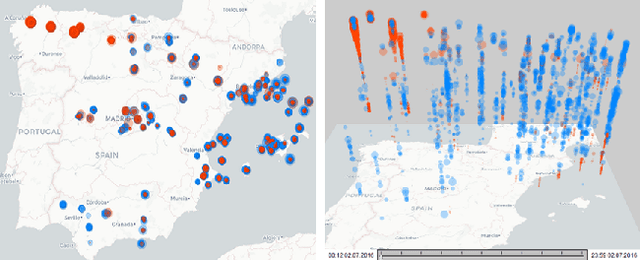
In this article, we report on the efficiency and effectiveness of multiagent reinforcement learning methods (MARL) for the computation of flight delays to resolve congestion problems in the Air Traffic Management (ATM) domain. Specifically, we aim to resolve cases where demand of airspace use exceeds capacity (demand-capacity problems), via imposing ground delays to flights at the pre-tactical stage of operations (i.e. few days to few hours before operation). Casting this into the multiagent domain, agents, representing flights, need to decide on own delays w.r.t. own preferences, having no information about others' payoffs, preferences and constraints, while they plan to execute their trajectories jointly with others, adhering to operational constraints. Specifically, we formalize the problem as a multiagent Markov Decision Process (MA-MDP) and we show that it can be considered as a Markov game in which interacting agents need to reach an equilibrium: What makes the problem more interesting is the dynamic setting in which agents operate, which is also due to the unforeseen, emergent effects of their decisions in the whole system. We propose collaborative multiagent reinforcement learning methods to resolve demand-capacity imbalances: Extensive experimental study on real-world cases, shows the potential of the proposed approaches in resolving problems, while advanced visualizations provide detailed views towards understanding the quality of solutions provided.
Combining Ontologies with Correspondences and Link Relations: The E-SHIQ Representation Framework
Oct 09, 2013
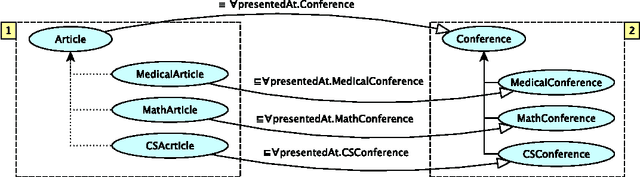

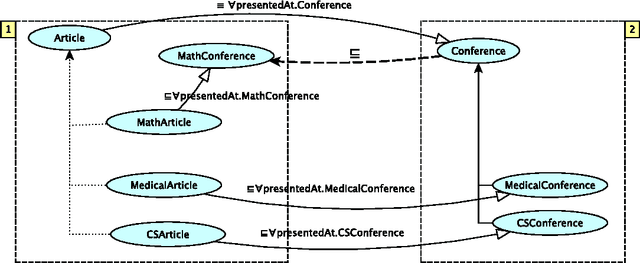
Combining knowledge and beliefs of autonomous peers in distributed settings, is a ma- jor challenge. In this paper we consider peers that combine ontologies and reason jointly with their coupled knowledge. Ontologies are within the SHIQ fragment of Description Logics. Although there are several representation frameworks for modular Description Log- ics, each one makes crucial assumptions concerning the subjectivity of peers' knowledge, the relation between the domains over which ontologies are interpreted, the expressivity of the constructors used for combining knowledge, and the way peers share their knowledge. However in settings where autonomous peers can evolve and extend their knowledge and beliefs independently from others, these assumptions may not hold. In this article, we moti- vate the need for a representation framework that allows peers to combine their knowledge in various ways, maintaining the subjectivity of their own knowledge and beliefs, and that reason collaboratively, constructing a tableau that is distributed among them, jointly. The paper presents the proposed E-SHIQ representation framework, the implementation of the E-SHIQ distributed tableau reasoner, and discusses the efficiency of this reasoner.
Probabilistic Event Calculus for Event Recognition
Aug 15, 2013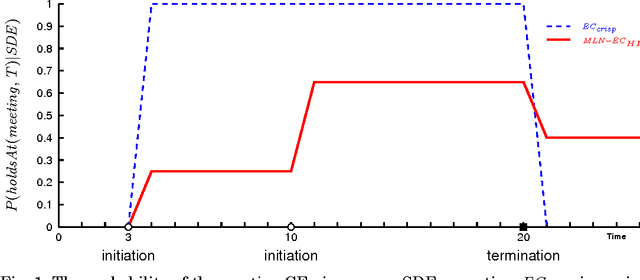
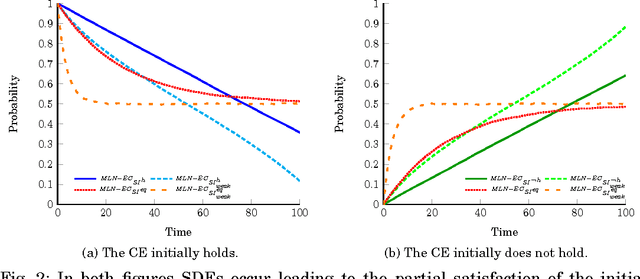
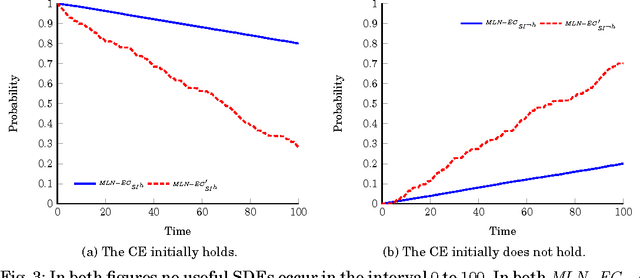
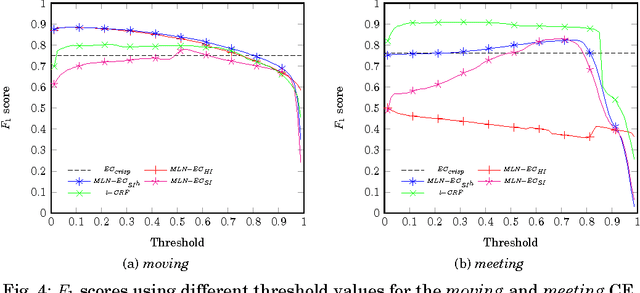
Symbolic event recognition systems have been successfully applied to a variety of application domains, extracting useful information in the form of events, allowing experts or other systems to monitor and respond when significant events are recognised. In a typical event recognition application, however, these systems often have to deal with a significant amount of uncertainty. In this paper, we address the issue of uncertainty in logic-based event recognition by extending the Event Calculus with probabilistic reasoning. Markov Logic Networks are a natural candidate for our logic-based formalism. However, the temporal semantics of the Event Calculus introduce a number of challenges for the proposed model. We show how and under what assumptions we can overcome these problems. Additionally, we study how probabilistic modelling changes the behaviour of the formalism, affecting its key property, the inertia of fluents. Furthermore, we demonstrate the advantages of the probabilistic Event Calculus through examples and experiments in the domain of activity recognition, using a publicly available dataset for video surveillance.