 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Agentic AI System for Multi-Framework Communication Coding
Dec 09, 2025Clinical communication is central to patient outcomes, yet large-scale human annotation of patient-provider conversation remains labor-intensive, inconsistent, and difficult to scale. Existing approaches based on large language models typically rely on single-task models that lack adaptability, interpretability, and reliability, especially when applied across various communication frameworks and clinical domains. In this study, we developed a Multi-framework Structured Agentic AI system for Clinical Communication (MOSAIC), built on a LangGraph-based architecture that orchestrates four core agents, including a Plan Agent for codebook selection and workflow planning, an Update Agent for maintaining up-to-date retrieval databases, a set of Annotation Agents that applies codebook-guided retrieval-augmented generation (RAG) with dynamic few-shot prompting, and a Verification Agent that provides consistency checks and feedback. To evaluate performance, we compared MOSAIC outputs against gold-standard annotations created by trained human coders. We developed and evaluated MOSAIC using 26 gold standard annotated transcripts for training and 50 transcripts for testing, spanning rheumatology and OB/GYN domains. On the test set, MOSAIC achieved an overall F1 score of 0.928. Performance was highest in the Rheumatology subset (F1 = 0.962) and strongest for Patient Behavior (e.g., patients asking questions, expressing preferences, or showing assertiveness). Ablations revealed that MOSAIC outperforms baseline benchmarking.
Group Distributionally Robust Machine Learning under Group Level Distributional Uncertainty
Sep 10, 2025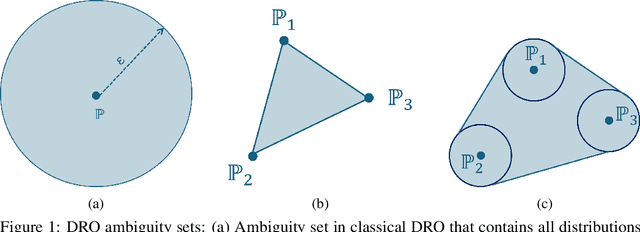

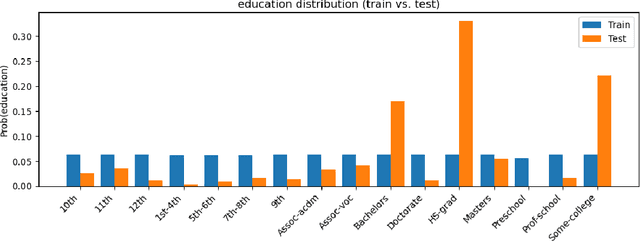
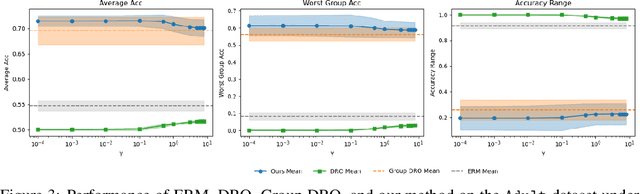
The performance of machine learning (ML) models critically depends on the quality and representativeness of the training data. In applications with multiple heterogeneous data generating sources, standard ML methods often learn spurious correlations that perform well on average but degrade performance for atypical or underrepresented groups. Prior work addresses this issue by optimizing the worst-group performance. However, these approaches typically assume that the underlying data distributions for each group can be accurately estimated using the training data, a condition that is frequently violated in noisy, non-stationary, and evolving environments. In this work, we propose a novel framework that relies on Wasserstein-based distributionally robust optimization (DRO) to account for the distributional uncertainty within each group, while simultaneously preserving the objective of improving the worst-group performance. We develop a gradient descent-ascent algorithm to solve the proposed DRO problem and provide convergence results. Finally, we validate the effectiveness of our method on real-world data.
FairPOT: Balancing AUC Performance and Fairness with Proportional Optimal Transport
Aug 05, 2025Fairness metrics utilizing the area under the receiver operator characteristic curve (AUC) have gained increasing attention in high-stakes domains such as healthcare, finance, and criminal justice. In these domains, fairness is often evaluated over risk scores rather than binary outcomes, and a common challenge is that enforcing strict fairness can significantly degrade AUC performance. To address this challenge, we propose Fair Proportional Optimal Transport (FairPOT), a novel, model-agnostic post-processing framework that strategically aligns risk score distributions across different groups using optimal transport, but does so selectively by transforming a controllable proportion, i.e., the top-lambda quantile, of scores within the disadvantaged group. By varying lambda, our method allows for a tunable trade-off between reducing AUC disparities and maintaining overall AUC performance. Furthermore, we extend FairPOT to the partial AUC setting, enabling fairness interventions to concentrate on the highest-risk regions. Extensive experiments on synthetic, public, and clinical datasets show that FairPOT consistently outperforms existing post-processing techniques in both global and partial AUC scenarios, often achieving improved fairness with slight AUC degradation or even positive gains in utility. The computational efficiency and practical adaptability of FairPOT make it a promising solution for real-world deployment.
Enabling Inclusive Systematic Reviews: Incorporating Preprint Articles with Large Language Model-Driven Evaluations
Mar 19, 2025Background. Systematic reviews in comparative effectiveness research require timely evidence synthesis. Preprints accelerate knowledge dissemination but vary in quality, posing challenges for systematic reviews. Methods. We propose AutoConfidence (automated confidence assessment), an advanced framework for predicting preprint publication, which reduces reliance on manual curation and expands the range of predictors, including three key advancements: (1) automated data extraction using natural language processing techniques, (2) semantic embeddings of titles and abstracts, and (3) large language model (LLM)-driven evaluation scores. Additionally, we employed two prediction models: a random forest classifier for binary outcome and a survival cure model that predicts both binary outcome and publication risk over time. Results. The random forest classifier achieved AUROC 0.692 with LLM-driven scores, improving to 0.733 with semantic embeddings and 0.747 with article usage metrics. The survival cure model reached AUROC 0.716 with LLM-driven scores, improving to 0.731 with semantic embeddings. For publication risk prediction, it achieved a concordance index of 0.658, increasing to 0.667 with semantic embeddings. Conclusion. Our study advances the framework for preprint publication prediction through automated data extraction and multiple feature integration. By combining semantic embeddings with LLM-driven evaluations, AutoConfidence enhances predictive performance while reducing manual annotation burden. The framework has the potential to facilitate systematic incorporation of preprint articles in evidence-based medicine, supporting researchers in more effective evaluation and utilization of preprint resources.
Distributionally Robust Clustered Federated Learning: A Case Study in Healthcare
Oct 09, 2024


In this paper, we address the challenge of heterogeneous data distributions in cross-silo federated learning by introducing a novel algorithm, which we term Cross-silo Robust Clustered Federated Learning (CS-RCFL). Our approach leverages the Wasserstein distance to construct ambiguity sets around each client's empirical distribution that capture possible distribution shifts in the local data, enabling evaluation of worst-case model performance. We then propose a model-agnostic integer fractional program to determine the optimal distributionally robust clustering of clients into coalitions so that possible biases in the local models caused by statistically heterogeneous client datasets are avoided, and analyze our method for linear and logistic regression models. Finally, we discuss a federated learning protocol that ensures the privacy of client distributions, a critical consideration, for instance, when clients are healthcare institutions. We evaluate our algorithm on synthetic and real-world healthcare data.