 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Enhancement Product Bundling: Bridging Interactive Graph and Large Language Model
Apr 15, 2026Product bundling boosts e-commerce revenue by recommending complementary item combinations. However, existing methods face two critical challenges: (1) collaborative filtering approaches struggle with cold-start items owing to dependency on historical interactions, and (2) LLMs lack inherent capability to model interactive graph directly. To bridge this gap, we propose a dual-enhancement method that integrates interactive graph learning and LLM-based semantic understanding for product bundling. Our method introduces a graph-to-text paradigm, which leverages a Dynamic Concept Binding Mechanism (DCBM) to translate graph structures into natural language prompts. The DCBM plays a critical role in aligning domain-specific entities with LLM tokenization, enabling effective comprehension of combinatorial constraints. Experiments on three benchmarks (POG, POG_dense, Steam) demonstrate 6.3%-26.5% improvements over state-of-the-art baselines.
Improve Decoding Factuality by Token-wise Cross Layer Entropy of Large Language Models
Feb 05, 2025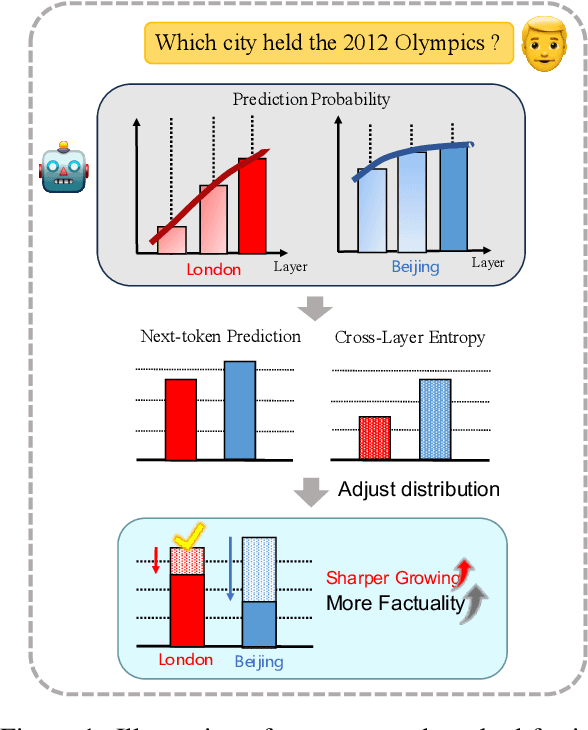
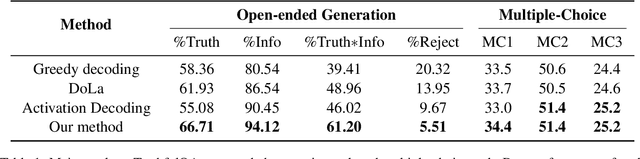
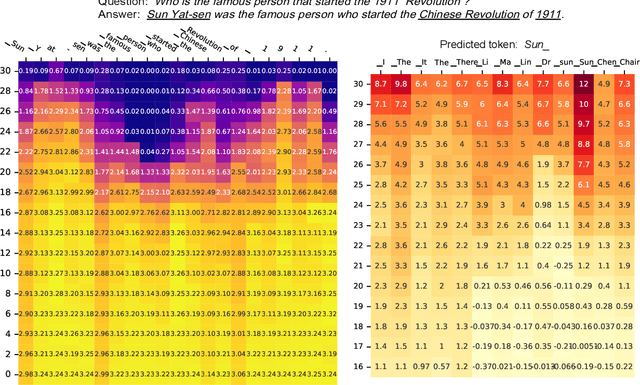
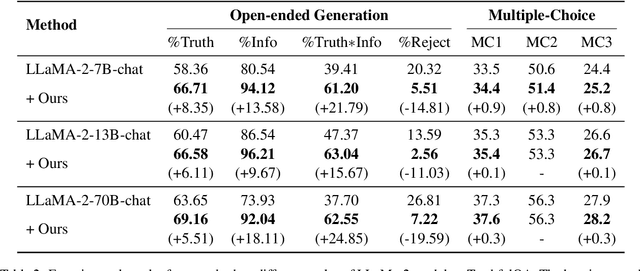
Despite their impressive capacities, Large language models (LLMs) often struggle with the hallucination issue of generating inaccurate or fabricated content even when they possess correct knowledge. In this paper, we extend the exploration of the correlation between hidden-state prediction changes and output factuality into a deeper, token-wise level. Based on the insights , we propose cross-layer Entropy eNhanced Decoding (END), a decoding method that mitigates hallucinations without requiring extra training. END leverages inner probability changes across layers to individually quantify the factual knowledge required for each candidate token, and adjusts the final predicting distribution to prioritize tokens with higher factuality. Experiments on both hallucination and QA benchmarks demonstrate that END significantly enhances the truthfulness and informativeness of generated content while maintaining robust QA accuracy. Moreover, our work provides a deeper perspective on understanding the correlations between inherent knowledge and output factuality.
Enhancing Large Language Model with Decomposed Reasoning for Emotion Cause Pair Extraction
Jan 31, 2024Emotion-Cause Pair Extraction (ECPE) involves extracting clause pairs representing emotions and their causes in a document. Existing methods tend to overfit spurious correlations, such as positional bias in existing benchmark datasets, rather than capturing semantic features. Inspired by recent work, we explore leveraging large language model (LLM) to address ECPE task without additional training. Despite strong capabilities, LLMs suffer from uncontrollable outputs, resulting in mediocre performance. To address this, we introduce chain-of-thought to mimic human cognitive process and propose the Decomposed Emotion-Cause Chain (DECC) framework. Combining inducing inference and logical pruning, DECC guides LLMs to tackle ECPE task. We further enhance the framework by incorporating in-context learning. Experiment results demonstrate the strength of DECC compared to state-of-the-art supervised fine-tuning methods. Finally, we analyze the effectiveness of each component and the robustness of the method in various scenarios, including different LLM bases, rebalanced datasets, and multi-pair extraction.
Constrained Sequence-to-Tree Generation for Hierarchical Text Classification
Apr 02, 2022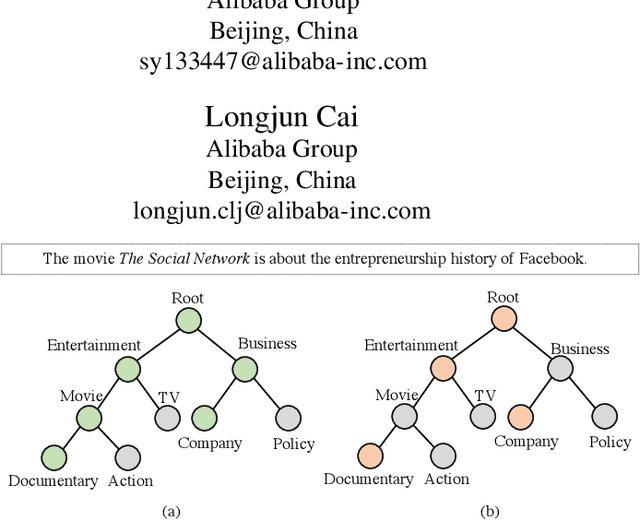

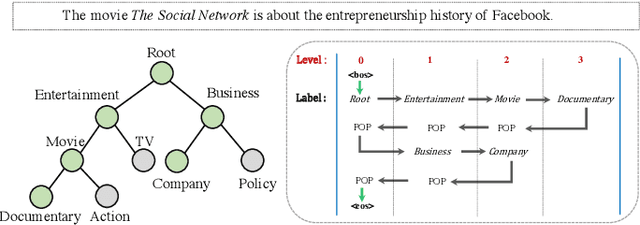
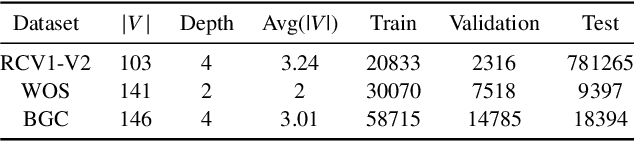
Hierarchical Text Classification (HTC) is a challenging task where a document can be assigned to multiple hierarchically structured categories within a taxonomy. The majority of prior studies consider HTC as a flat multi-label classification problem, which inevitably leads to "label inconsistency" problem. In this paper, we formulate HTC as a sequence generation task and introduce a sequence-to-tree framework (Seq2Tree) for modeling the hierarchical label structure. Moreover, we design a constrained decoding strategy with dynamic vocabulary to secure the label consistency of the results. Compared with previous works, the proposed approach achieves significant and consistent improvements on three benchmark datasets.
Hybrid Curriculum Learning for Emotion Recognition in Conversation
Dec 22, 2021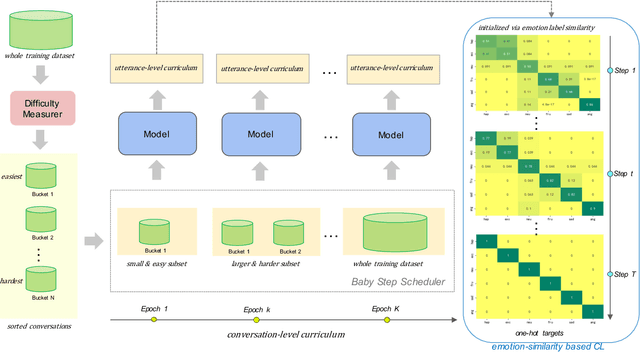
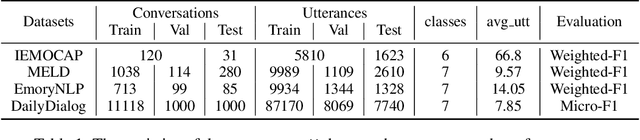
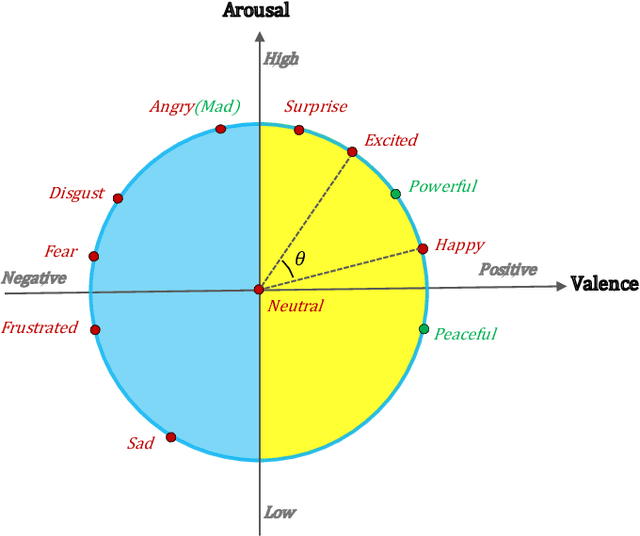
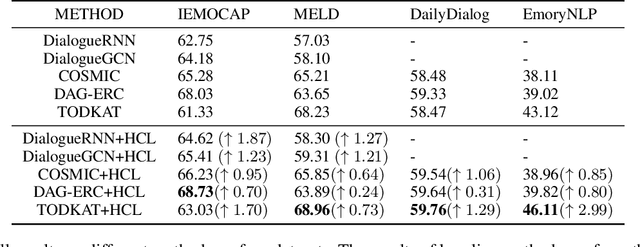
Emotion recognition in conversation (ERC) aims to detect the emotion label for each utterance. Motivated by recent studies which have proven that feeding training examples in a meaningful order rather than considering them randomly can boost the performance of models, we propose an ERC-oriented hybrid curriculum learning framework. Our framework consists of two curricula: (1) conversation-level curriculum (CC); and (2) utterance-level curriculum (UC). In CC, we construct a difficulty measurer based on "emotion shift" frequency within a conversation, then the conversations are scheduled in an "easy to hard" schema according to the difficulty score returned by the difficulty measurer. For UC, it is implemented from an emotion-similarity perspective, which progressively strengthens the model's ability in identifying the confusing emotions. With the proposed model-agnostic hybrid curriculum learning strategy, we observe significant performance boosts over a wide range of existing ERC models and we are able to achieve new state-of-the-art results on four public ERC datasets.
Reducing the Covariate Shift by Mirror Samples in Cross Domain Alignment
Oct 13, 2021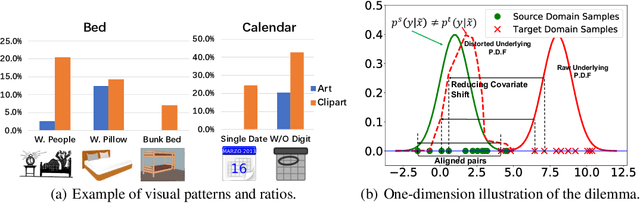
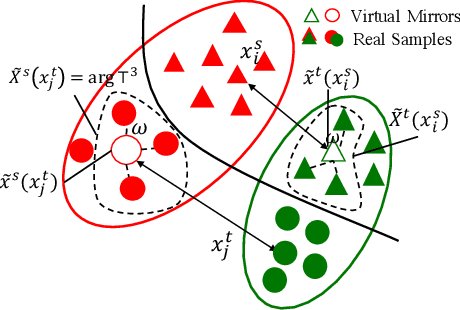

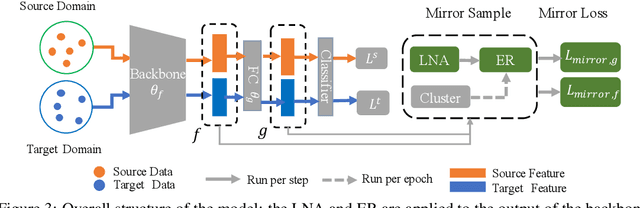
Eliminating the covariate shift cross domains is one of the common methods to deal with the issue of domain shift in visual unsupervised domain adaptation. However, current alignment methods, especially the prototype based or sample-level based methods neglect the structural properties of the underlying distribution and even break the condition of covariate shift. To relieve the limitations and conflicts, we introduce a novel concept named (virtual) mirror, which represents the equivalent sample in another domain. The equivalent sample pairs, named mirror pairs reflect the natural correspondence of the empirical distributions. Then a mirror loss, which aligns the mirror pairs cross domains, is constructed to enhance the alignment of the domains. The proposed method does not distort the internal structure of the underlying distribution. We also provide theoretical proof that the mirror samples and mirror loss have better asymptotic properties in reducing the domain shift. By applying the virtual mirror and mirror loss to the generic unsupervised domain adaptation model, we achieved consistent superior performance on several mainstream benchmarks.
Pairwise Emotional Relationship Recognition in Drama Videos: Dataset and Benchmark
Sep 23, 2021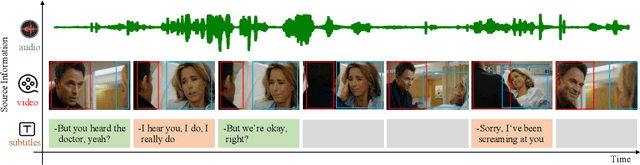
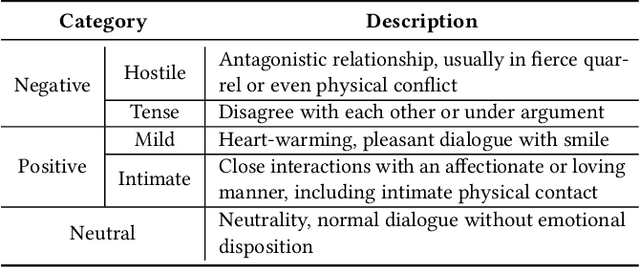
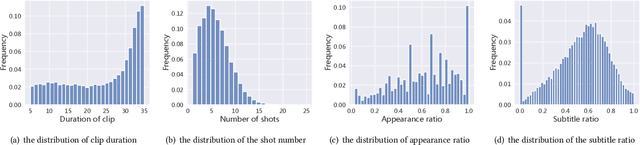
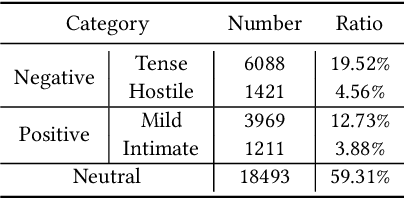
Recognizing the emotional state of people is a basic but challenging task in video understanding. In this paper, we propose a new task in this field, named Pairwise Emotional Relationship Recognition (PERR). This task aims to recognize the emotional relationship between the two interactive characters in a given video clip. It is different from the traditional emotion and social relation recognition task. Varieties of information, consisting of character appearance, behaviors, facial emotions, dialogues, background music as well as subtitles contribute differently to the final results, which makes the task more challenging but meaningful in developing more advanced multi-modal models. To facilitate the task, we develop a new dataset called Emotional RelAtionship of inTeractiOn (ERATO) based on dramas and movies. ERATO is a large-scale multi-modal dataset for PERR task, which has 31,182 video clips, lasting about 203 video hours. Different from the existing datasets, ERATO contains interaction-centric videos with multi-shots, varied video length, and multiple modalities including visual, audio and text. As a minor contribution, we propose a baseline model composed of Synchronous Modal-Temporal Attention (SMTA) unit to fuse the multi-modal information for the PERR task. In contrast to other prevailing attention mechanisms, our proposed SMTA can steadily improve the performance by about 1\%. We expect the ERATO as well as our proposed SMTA to open up a new way for PERR task in video understanding and further improve the research of multi-modal fusion methodology.
A Joint Training Dual-MRC Framework for Aspect Based Sentiment Analysis
Jan 04, 2021
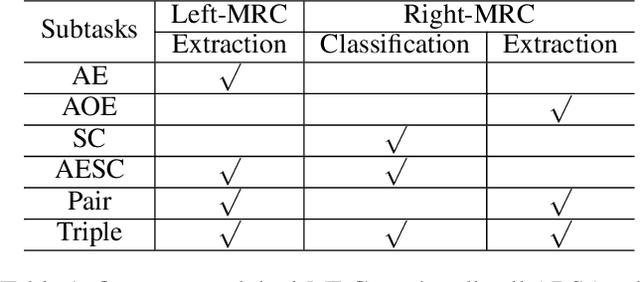
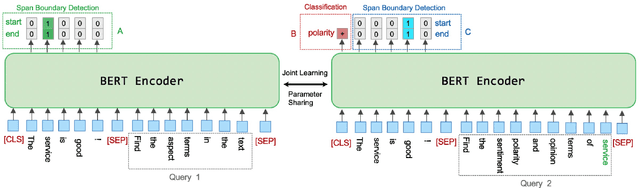

Aspect based sentiment analysis (ABSA) involves three fundamental subtasks: aspect term extraction, opinion term extraction, and aspect-level sentiment classification. Early works only focused on solving one of these subtasks individually. Some recent work focused on solving a combination of two subtasks, e.g., extracting aspect terms along with sentiment polarities or extracting the aspect and opinion terms pair-wisely. More recently, the triple extraction task has been proposed, i.e., extracting the (aspect term, opinion term, sentiment polarity) triples from a sentence. However, previous approaches fail to solve all subtasks in a unified end-to-end framework. In this paper, we propose a complete solution for ABSA. We construct two machine reading comprehension (MRC) problems, and solve all subtasks by joint training two BERT-MRC models with parameters sharing. We conduct experiments on these subtasks and results on several benchmark datasets demonstrate the effectiveness of our proposed framework, which significantly outperforms existing state-of-the-art methods.
ESA-ReID: Entropy-Based Semantic Feature Alignment for Person re-ID
Jul 09, 2020
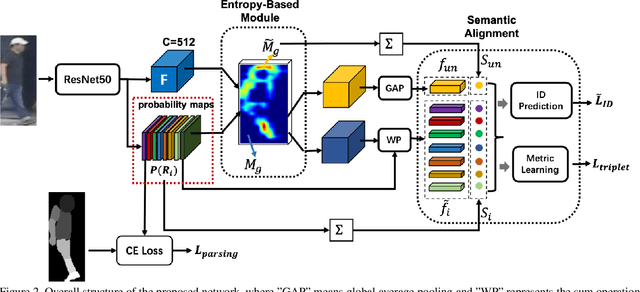
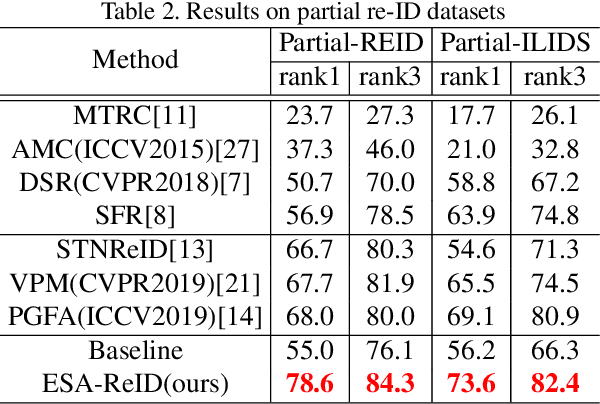
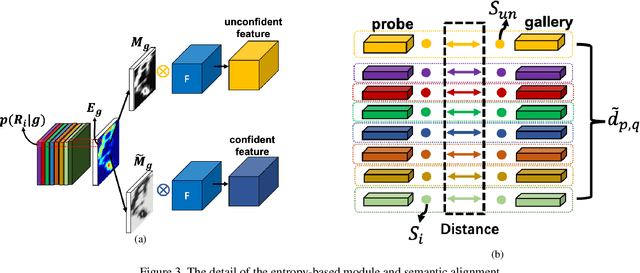
Person re-identification (re-ID) is a challenging task in real-world. Besides the typical application in surveillance system, re-ID also has significant values to improve the recall rate of people identification in content video (TV or Movies). However, the occlusion, shot angle variations and complicated background make it far away from application, especially in content video. In this paper we propose an entropy based semantic feature alignment model, which takes advantages of the detailed information of the human semantic feature. Considering the uncertainty of semantic segmentation, we introduce a semantic alignment with an entropy-based mask which can reduce the negative effects of mask segmentation errors. We construct a new re-ID dataset based on content videos with many cases of occlusion and body part missing, which will be released in future. Extensive studies on both existing datasets and the new dataset demonstrate the superior performance of the proposed model.
Video Affective Effects Prediction with Multi-modal Fusion and Shot-Long Temporal Context
Sep 01, 2019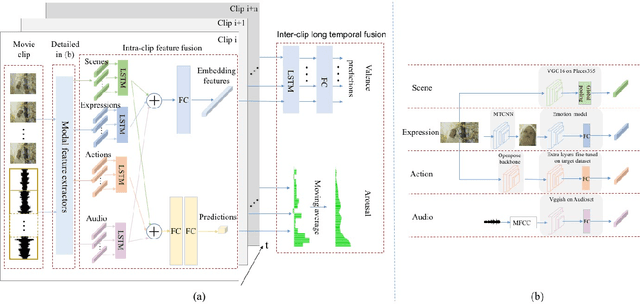
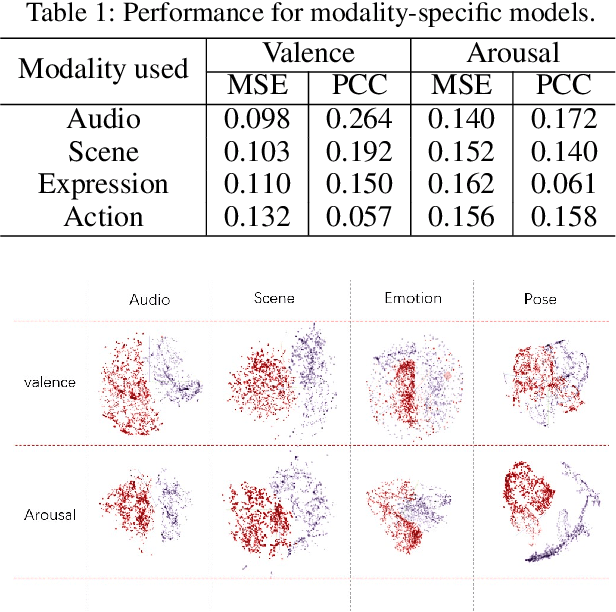
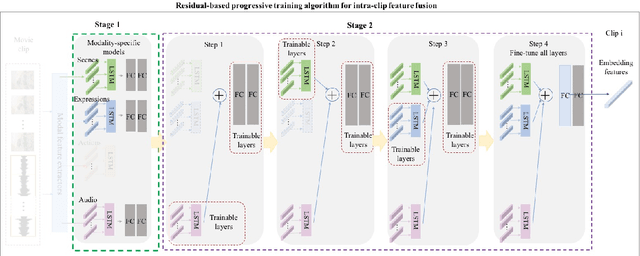
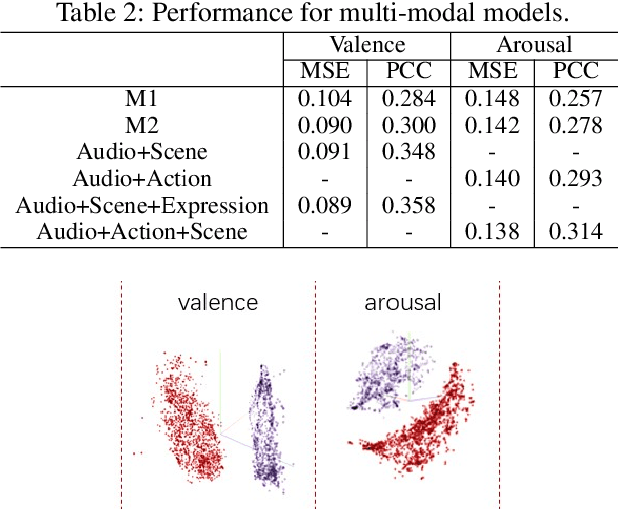
Predicting the emotional impact of videos using machine learning is a challenging task considering the varieties of modalities, the complicated temporal contex of the video as well as the time dependency of the emotional states. Feature extraction, multi-modal fusion and temporal context fusion are crucial stages for predicting valence and arousal values in the emotional impact, but have not been successfully exploited. In this paper, we propose a comprehensive framework with novel designs of modal structure and multi-modal fusion strategy. We select the most suitable modalities for valence and arousal tasks respectively and each modal feature is extracted using the modality-specific pre-trained deep model on large generic dataset. Two-time-scale structures, one for the intra-clip and the other for the inter-clip, are proposed to capture the temporal dependency of video content and emotion states. To combine the complementary information from multiple modalities, an effective and efficient residual-based progressive training strategy is proposed. Each modality is step-wisely combined into the multi-modal model, responsible for completing the missing parts of features. With all those improvements above, our proposed prediction framework achieves better performance on the LIRIS-ACCEDE dataset with a large margin compared to the state-of-the-art.