 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairwise Emotional Relationship Recognition in Drama Videos: Dataset and Benchmark
Paper and Code
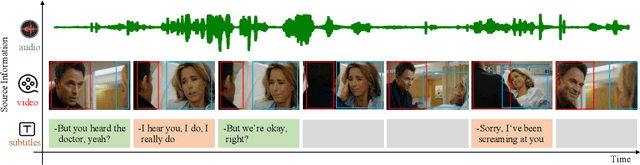
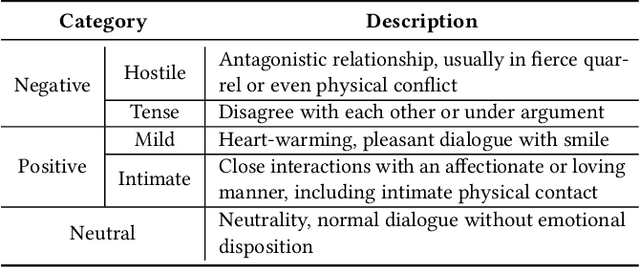
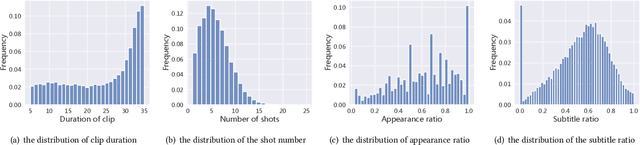
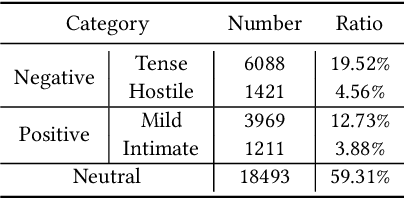
Recognizing the emotional state of people is a basic but challenging task in video understanding. In this paper, we propose a new task in this field, named Pairwise Emotional Relationship Recognition (PERR). This task aims to recognize the emotional relationship between the two interactive characters in a given video clip. It is different from the traditional emotion and social relation recognition task. Varieties of information, consisting of character appearance, behaviors, facial emotions, dialogues, background music as well as subtitles contribute differently to the final results, which makes the task more challenging but meaningful in developing more advanced multi-modal models. To facilitate the task, we develop a new dataset called Emotional RelAtionship of inTeractiOn (ERATO) based on dramas and movies. ERATO is a large-scale multi-modal dataset for PERR task, which has 31,182 video clips, lasting about 203 video hours. Different from the existing datasets, ERATO contains interaction-centric videos with multi-shots, varied video length, and multiple modalities including visual, audio and text. As a minor contribution, we propose a baseline model composed of Synchronous Modal-Temporal Attention (SMTA) unit to fuse the multi-modal information for the PERR task. In contrast to other prevailing attention mechanisms, our proposed SMTA can steadily improve the performance by about 1\%. We expect the ERATO as well as our proposed SMTA to open up a new way for PERR task in video understanding and further improve the research of multi-modal fusion methodology.