 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Affective Effects Prediction with Multi-modal Fusion and Shot-Long Temporal Context
Paper and Code
Sep 01, 2019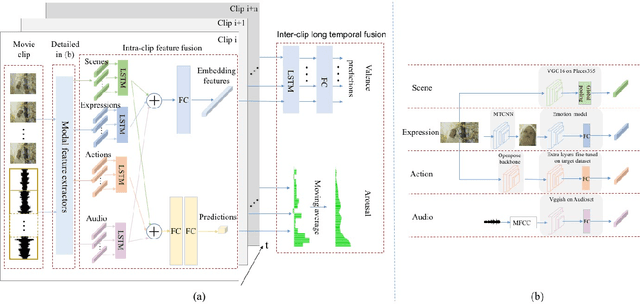
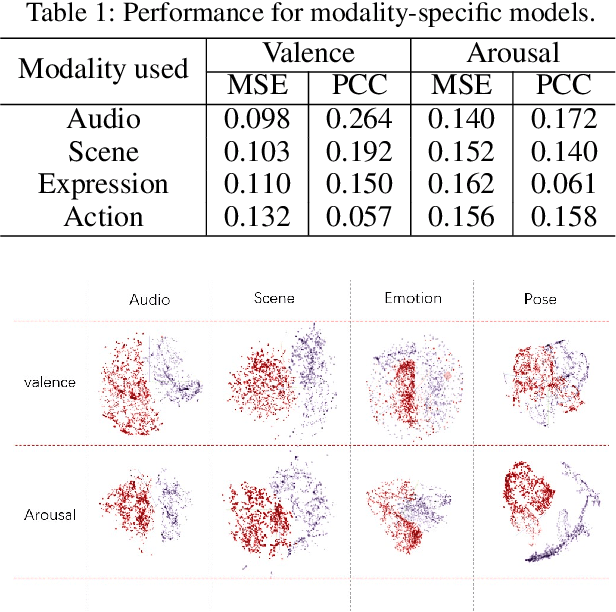
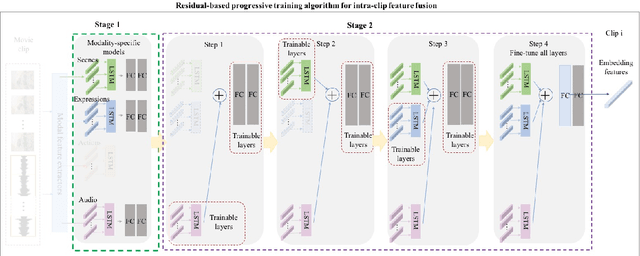
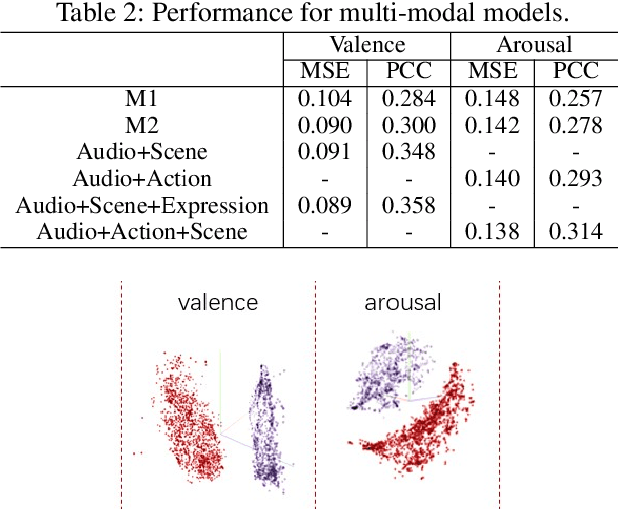
Predicting the emotional impact of videos using machine learning is a challenging task considering the varieties of modalities, the complicated temporal contex of the video as well as the time dependency of the emotional states. Feature extraction, multi-modal fusion and temporal context fusion are crucial stages for predicting valence and arousal values in the emotional impact, but have not been successfully exploited. In this paper, we propose a comprehensive framework with novel designs of modal structure and multi-modal fusion strategy. We select the most suitable modalities for valence and arousal tasks respectively and each modal feature is extracted using the modality-specific pre-trained deep model on large generic dataset. Two-time-scale structures, one for the intra-clip and the other for the inter-clip, are proposed to capture the temporal dependency of video content and emotion states. To combine the complementary information from multiple modalities, an effective and efficient residual-based progressive training strategy is proposed. Each modality is step-wisely combined into the multi-modal model, responsible for completing the missing parts of features. With all those improvements above, our proposed prediction framework achieves better performance on the LIRIS-ACCEDE dataset with a large margin compared to the state-of-the-art.