 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Reinforcement Learning from Non-Stationary Learning Agents
Oct 18, 2024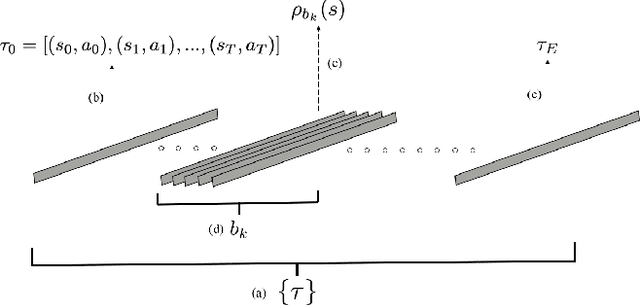

In this paper, we study an inverse reinforcement learning problem that involves learning the reward function of a learning agent using trajectory data collected while this agent is learning its optimal policy. To address this problem, we propose an inverse reinforcement learning method that allows us to estimate the policy parameters of the learning agent which can then be used to estimate its reward function. Our method relies on a new variant of the behavior cloning algorithm, which we call bundle behavior cloning, and uses a small number of trajectories generated by the learning agent's policy at different points in time to learn a set of policies that match the distribution of actions observed in the sampled trajectories. We then use the cloned policies to train a neural network model that estimates the reward function of the learning agent. We provide a theoretical analysis to show a complexity result on bound guarantees for our method that beats standard behavior cloning as well as numerical experiments for a reinforcement learning problem that validate the proposed method.
Transfer Reinforcement Learning in Heterogeneous Action Spaces using Subgoal Mapping
Oct 18, 2024

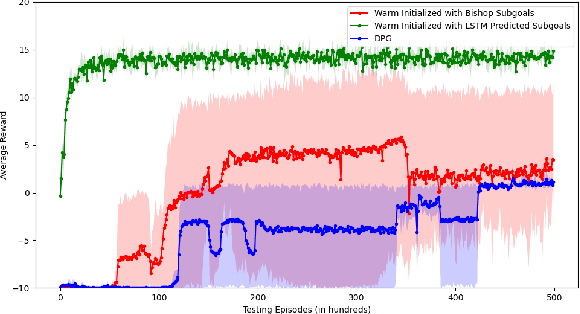
In this paper, we consider a transfer reinforcement learning problem involving agents with different action spaces. Specifically, for any new unseen task, the goal is to use a successful demonstration of this task by an expert agent in its action space to enable a learner agent learn an optimal policy in its own different action space with fewer samples than those required if the learner was learning on its own. Existing transfer learning methods across different action spaces either require handcrafted mappings between those action spaces provided by human experts, which can induce bias in the learning procedure, or require the expert agent to share its policy parameters with the learner agent, which does not generalize well to unseen tasks. In this work, we propose a method that learns a subgoal mapping between the expert agent policy and the learner agent policy. Since the expert agent and the learner agent have different action spaces, their optimal policies can have different subgoal trajectories. We learn this subgoal mapping by training a Long Short Term Memory (LSTM) network for a distribution of tasks and then use this mapping to predict the learner subgoal sequence for unseen tasks, thereby improving the speed of learning by biasing the agent's policy towards the predicted learner subgoal sequence. Through numerical experiments, we demonstrate that the proposed learning scheme can effectively find the subgoal mapping underlying the given distribution of tasks. Moreover, letting the learner agent imitate the expert agent's policy with the learnt subgoal mapping can significantly improve the sample efficiency and training time of the learner agent in unseen new tasks.
Perception Stitching: Zero-Shot Perception Encoder Transfer for Visuomotor Robot Policies
Jun 28, 2024



Vision-based imitation learning has shown promising capabilities of endowing robots with various motion skills given visual observation. However, current visuomotor policies fail to adapt to drastic changes in their visual observations. We present Perception Stitching that enables strong zero-shot adaptation to large visual changes by directly stitching novel combinations of visual encoders. Our key idea is to enforce modularity of visual encoders by aligning the latent visual features among different visuomotor policies. Our method disentangles the perceptual knowledge with the downstream motion skills and allows the reuse of the visual encoders by directly stitching them to a policy network trained with partially different visual conditions. We evaluate our method in various simulated and real-world manipulation tasks. While baseline methods failed at all attempts, our method could achieve zero-shot success in real-world visuomotor tasks. Our quantitative and qualitative analysis of the learned features of the policy network provides more insights into the high performance of our proposed method.
Policy Stitching: Learning Transferable Robot Policies
Sep 24, 2023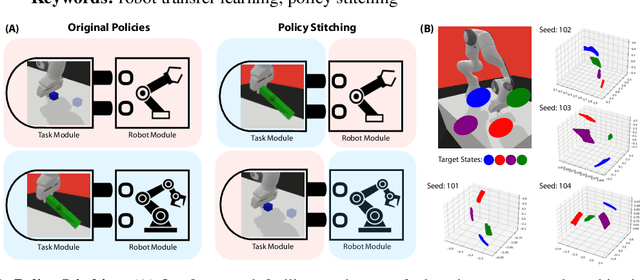
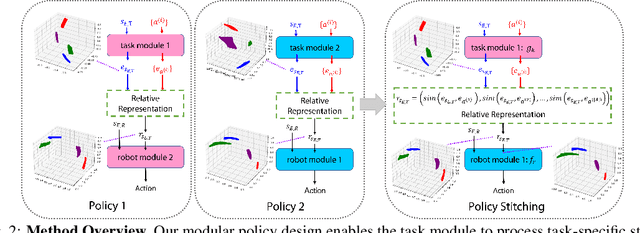

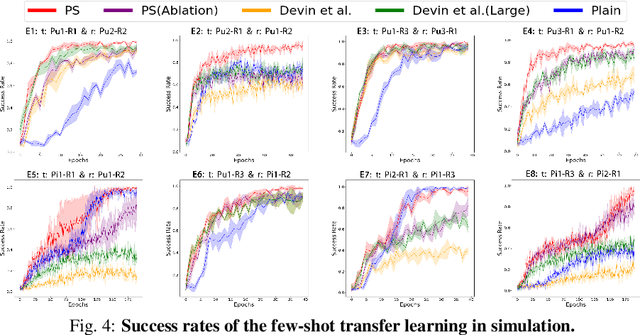
Training robots with reinforcement learning (RL) typically involves heavy interactions with the environment, and the acquired skills are often sensitive to changes in task environments and robot kinematics. Transfer RL aims to leverage previous knowledge to accelerate learning of new tasks or new body configurations. However, existing methods struggle to generalize to novel robot-task combinations and scale to realistic tasks due to complex architecture design or strong regularization that limits the capacity of the learned policy. We propose Policy Stitching, a novel framework that facilitates robot transfer learning for novel combinations of robots and tasks. Our key idea is to apply modular policy design and align the latent representations between the modular interfaces. Our method allows direct stitching of the robot and task modules trained separately to form a new policy for fast adaptation. Our simulated and real-world experiments on various 3D manipulation tasks demonstrate the superior zero-shot and few-shot transfer learning performances of our method. Our project website is at: http://generalroboticslab.com/PolicyStitching/ .