 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSD: Multi-Self-Distillation Learning via Multi-classifiers within Deep Neural Networks
Dec 02, 2019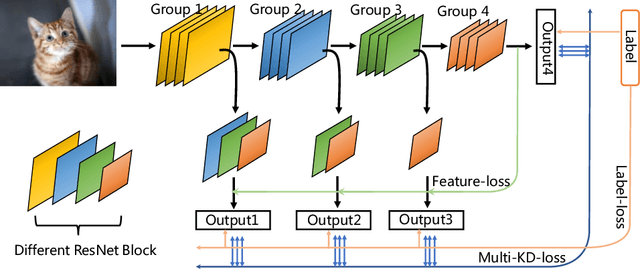

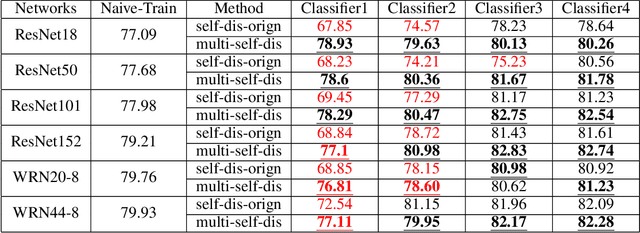
As the development of neural networks, more and more deep neural networks are adopted in various tasks, such as image classification. However, as the huge computational overhead, these networks could not be applied on mobile devices or other low latency scenes. To address this dilemma, multi-classifier convolutional network is proposed to allow faster inference via early classifiers with the corresponding classifiers. These networks utilize sophisticated designing to increase the early classifier accuracy. However, naively training the multi-classifier network could hurt the performance (accuracy) of deep neural networks as early classifiers throughout interfere with the feature generation process. In this paper, we propose a general training framework named multi-self-distillation learning (MSD), which mining knowledge of different classifiers within the same network and increase every classifier accuracy. Our approach can be applied not only to multi-classifier networks, but also modern CNNs (e.g., ResNet Series) augmented with additional side branch classifiers. We use sampling-based branch augmentation technique to transform a single-classifier network into a multi-classifier network. This reduces the gap of capacity between different classifiers, and improves the effectiveness of applying MSD. Our experiments show that MSD improves the accuracy of various networks: enhancing the accuracy of every classifier significantly for existing multi-classifier network (MSDNet), improving vanilla single-classifier networks with internal classifiers with high accuracy, while also improving the final accuracy.
Towards Efficient Large-Scale Graph Neural Network Computing
Oct 19, 2018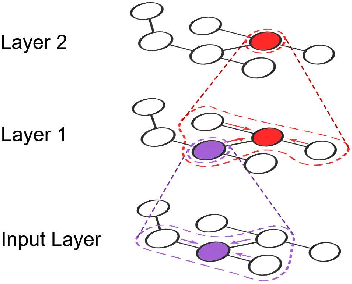
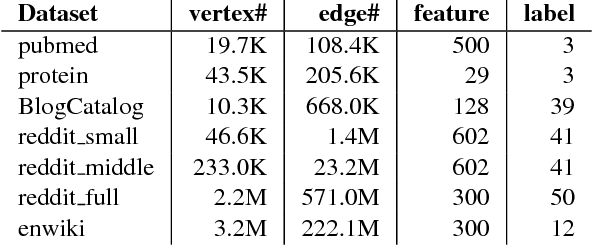

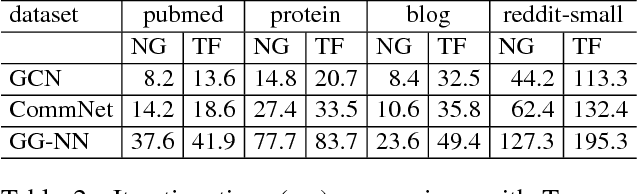
Recent deep learning models have moved beyond low-dimensional regular grids such as image, video, and speech, to high-dimensional graph-structured data, such as social networks, brain connections, and knowledge graphs. This evolution has led to large graph-based irregular and sparse models that go beyond what existing deep learning frameworks are designed for. Further, these models are not easily amenable to efficient, at scale, acceleration on parallel hardwares (e.g. GPUs). We introduce NGra, the first parallel processing framework for graph-based deep neural networks (GNNs). NGra presents a new SAGA-NN model for expressing deep neural networks as vertex programs with each layer in well-defined (Scatter, ApplyEdge, Gather, ApplyVertex) graph operation stages. This model not only allows GNNs to be expressed intuitively, but also facilitates the mapping to an efficient dataflow representation. NGra addresses the scalability challenge transparently through automatic graph partitioning and chunk-based stream processing out of GPU core or over multiple GPUs, which carefully considers data locality, data movement, and overlapping of parallel processing and data movement. NGra further achieves efficiency through highly optimized Scatter/Gather operators on GPUs despite its sparsity. Our evaluation shows that NGra scales to large real graphs that none of the existing frameworks can handle directly, while achieving up to about 4 times speedup even at small scales over the multiple-baseline design on TensorFlow.